This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using proprietary largelanguagemodel (LLM)-based agents, the platform facilitates the curation, synthesis, and triangulation of data to generate structured, decision-ready outputs.
With the significant advancement in the fields of Artificial Intelligence (AI) and NaturalLanguageProcessing (NLP), LargeLanguageModels (LLMs) like GPT have gained attention for producing fluent text without explicitly built grammar or semantic modules. If you like our work, you will love our newsletter.
GenAI can help by automatically clustering similar data points and inferring labels from unlabeled data, obtaining valuable insights from previously unusable sources. NaturalLanguageProcessing (NLP) is an example of where traditional methods can struggle with complex text data.
Largelanguagemodels (LLMs) are at the forefront of technological advancements in naturallanguageprocessing, marking a significant leap in the ability of machines to understand, interpret, and generate human-like text. Similarly, on the CaseHOLD dataset, there was a 32.6% enhancement, and on SNIPS, a 32.0%
Introduction The field of naturallanguageprocessing (NLP) and languagemodels has experienced a remarkable transformation in recent years, propelled by the advent of powerful largelanguagemodels (LLMs) like GPT-4, PaLM, and Llama.
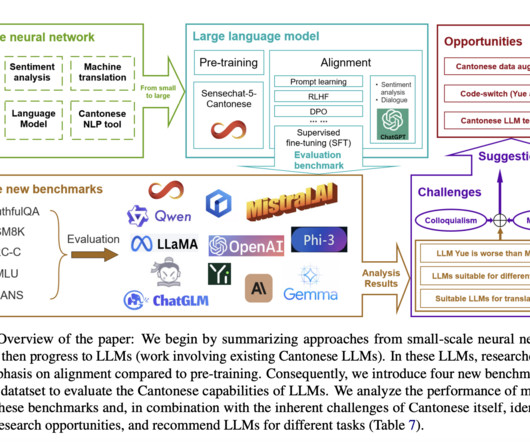
Largelanguagemodels (LLMs) have revolutionized naturallanguageprocessing (NLP), particularly for English and other data-rich languages. However, this rapid advancement has created a significant development gap for underrepresented languages, with Cantonese being a prime example.
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. DataScarcity: Pre-training on small datasets (e.g., Wikipedia + BookCorpus) restricts knowledge diversity.
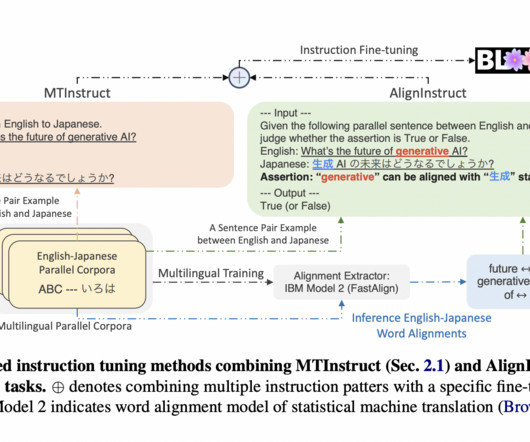
Machine translation, an integral branch of NaturalLanguageProcessing, is continually evolving to bridge language gaps across the globe. One persistent challenge is the translation of low-resource languages, which often need more substantial data for training robust models.
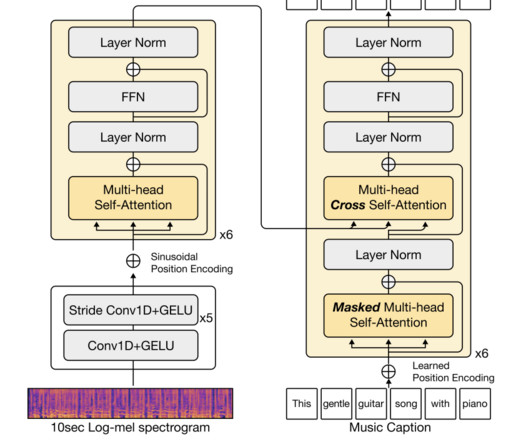
Also, the limited number of available music-language datasets poses a challenge. With the scarcity of datasets, training a music captioning model successfully doesn’t remain easy. Largelanguagemodels (LLMs) could be a potential solution for music caption generation. The training process of GPT-3.5
Multilingual naturallanguageprocessing (NLP) is a rapidly advancing field that aims to develop languagemodels capable of understanding & generating text in multiple languages. These models facilitate effective communication and information access across diverse linguistic backgrounds.
The rapid advancement of largelanguagemodels has ushered in a new era of naturallanguageprocessing capabilities. However, a significant challenge persists: most of these models are primarily trained on a limited set of widely spoken languages, leaving a vast linguistic diversity unexplored.
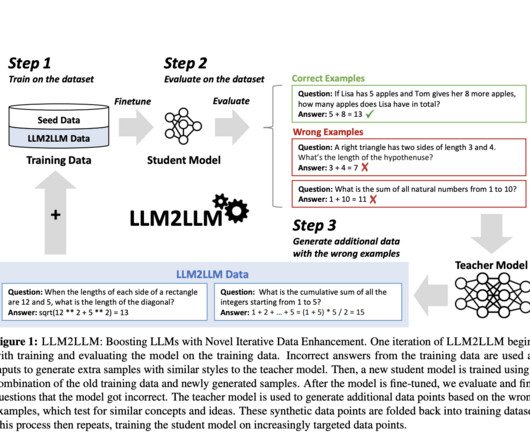
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machine learning , data analysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
On various NaturalLanguageProcessing (NLP) tasks, LargeLanguageModels (LLMs) such as GPT-3.5 They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first.
Generated with Midjourney The NeurIPS 2023 conference showcased a range of significant advancements in AI, with a particular focus on largelanguagemodels (LLMs), reflecting current trends in AI research. Outstanding Papers Awards Are Emerged Abilities of LargeLanguageModels a Mirage?
The ability to translate spoken words into another language in real time is known as simultaneous speech translation, and it paves the way for instantaneous communication across language barriers. There has been a lot of buzz about machine-assisted autonomous interpretation in naturallanguageprocessing (NLP).
LargeLanguageModels (LLMs) have revolutionized naturallanguageprocessing in recent years. The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family.
Summary: Small LanguageModels (SLMs) are transforming the AI landscape by providing efficient, cost-effective solutions for NaturalLanguageProcessing tasks. With innovations in model compression and transfer learning, SLMs are being applied across diverse sectors. What Are Small LanguageModels (SLMs)?
Many use cases involve using pre-trained largelanguagemodels (LLMs) through approaches like Retrieval Augmented Generation (RAG). However, for advanced, domain-specific tasks or those requiring specific formats, model customization techniques such as fine-tuning are sometimes necessary. Yiyue holds a Ph.D.
Highlighted work from our institute appearing at this year’s EMNLP conference Empirical Methods in NaturalLanguageProcessing ( EMNLP ) is a leading conference in naturallanguageprocessing and artificial intelligence. Yet controlling these models through prompting alone is limited.
Illustration of a few-shot segmentation process. Segment Anything Model (SAM) Inspired by the success of prompting techniques utilized in the field of naturallanguageprocessing, researchers from Meta AI proposed the Segment Anything Model (SAM), which aims to perform image segmentation based on segmentation prompts.
By marrying the disciplines of computer vision, naturallanguageprocessing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology. The integration of multimodal LargeLanguageModels (LLMs) with robots is monumental in spearheading this field.
By marrying the disciplines of computer vision, naturallanguageprocessing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology. The integration of multimodal LargeLanguageModels (LLMs) with robots is monumental in spearheading this field.
At the forefront of this transformation are LargeLanguageModels (LLMs). These intelligent models have transcended their traditional linguistic boundaries to influence music generation. This approach enables high-quality, controllable melody generation with minimal lyric-melody paired data.
Disease Diagnosis Generative AI enhances disease diagnosis by enhancing the accuracy and efficiency of interpreting data. Healthcare NLP (NaturalLanguageProcessing) technologies extract insights from physician records, patient histories and diagnostic reports facilitating precise diagnosis. This improves access to care.
Illustration of a few-shot segmentation process. Segment Anything Model (SAM) Inspired by the success of prompting techniques utilized in the field of naturallanguageprocessing, researchers from Meta AI proposed the Segment Anything Model (SAM), which aims to perform image segmentation based on segmentation prompts.
Disease Diagnosis Generative AI enhances disease diagnosis by enhancing the accuracy and efficiency of interpreting data. Healthcare NLP (NaturalLanguageProcessing) technologies extract insights from physician records, patient histories and diagnostic reports facilitating precise diagnosis. This improves access to care.
With a vision to build a largelanguagemodel (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties. To tackle this datascarcity challenge, Fastweb had to build a comprehensive training dataset from scratch to enable effective model fine-tuning.
Unlike naturallanguageprocessing or vision-based AI, this area uniquely combines structured logic with the creative elements of human-like reasoning, holding the promise of transformative advancements. This has created a critical need for new approaches to bridge these gaps.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content