This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The structural flexibility of RNA, which leads to the scarcity of experimentally determined data, complicates computational prediction efforts. Here we present RhoFold+, an RNA language model-based deeplearning method that accurately predicts 3D structures of single-chain RNAs from sequences.
Over the past decade, advancements in deeplearning and artificial intelligence have driven significant strides in self-driving vehicle technology. Deeplearning and AI technologies play crucial roles in both modular and End2End systems for autonomous driving. Classical methodologies for these tasks are also explored.
Unlike conventional methods, this approach utilizes Bayesian inference and Monte Carlo techniques to effectively manage uncertainty and datascarcity. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Together, these techniques mitigate the issues of limited target data, improving the model’s adaptability and accuracy. A recent paper published by a Chinese research team proposes a novel approach to combat datascarcity in classification tasks within target domains. Check out the Paper.
Point clouds serve as a prevalent representation of 3D data, with the extraction of point-wise features being crucial for various tasks related to 3D understanding. However, the scarcity and limited annotation of 3D data present significant challenges for the development and impact of 3D pretraining.
Deeplearning automates and improves medical picture analysis. Convolutional neural networks (CNNs) can learn complicated patterns and features from enormous datasets, emulating the human visual system. Convolutional Neural Networks (CNNs) Deeplearning in medical image analysis relies on CNNs.
Transfer Learning in DeepLearning: A Brief Overview Collecting large volumes of data, filtering it and then interpreting is a challenging task. What if we say that you have the option of using a pre-trained model that works as a framework for data training? Yes, Transfer Learning is the answer to it.
They are effective in face recognition, image similarity, and one-shot learning but face challenges like high computational costs and data imbalance. Introduction Neural networks form the backbone of DeepLearning , allowing machines to learn from data by mimicking the human brain’s structure.
Datascarcity and data imbalance are two of these challenges. Using insufficiently large or imbalanced datasets to train or evaluate a machine learning model may result in systemic biases in model performance. Still, their synthetic results lack the image quality of GANs.
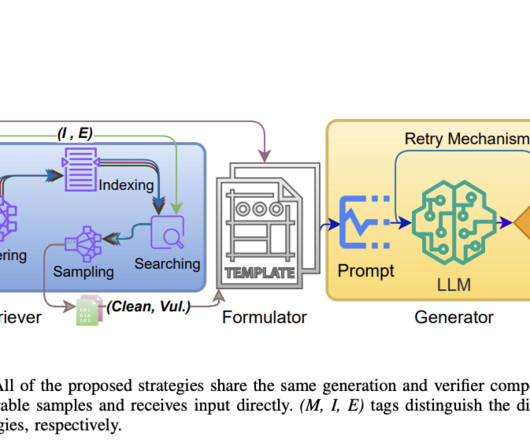
A significant challenge in developing these automated tools is the lack of extensive and diverse datasets required to effectively train deeplearning-based vulnerability detection (DLVD) models. Without sufficient data, these models struggle to accurately identify and generalize different types of vulnerabilities.
Transfer learning and ensemble methods address challenges like overfitting, underfitting, and datascarcity. ML facilitates the exploration of vast unanalyzed datasets, promising new strategies in bioprocess development.
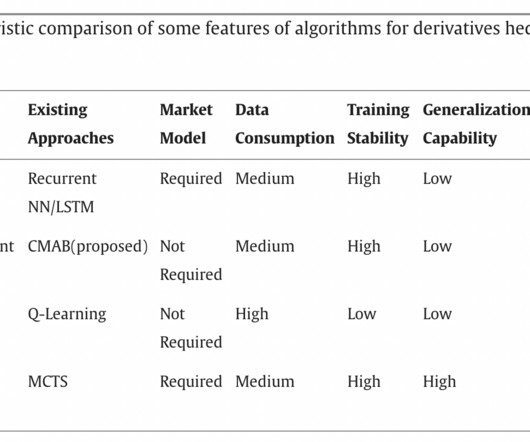
He highlighted the necessity for effective data use by stressing the significant amount of data many AI systems consume. Another researcher highlighted the challenge of considering AI model-free due to market datascarcity for training, particularly in realistic derivative markets.
Datascarcity: Paired natural anguage descriptions of music and corresponding music recordings are extremely scarce, in contrast to the abundance of image/descriptions pairs available online, e.g. in online art galleries or social media. This also makes the evaluation step harder and highly subjective.
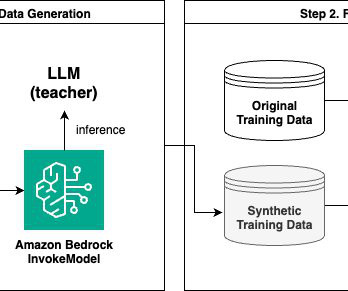
We use the larger teacher model to generate new data based on its knowledge, which is then used to train the smaller student model. If youre interested in working with the AWS Generative AI Innovation Center and learning more about LLM customization and other generative AI use cases, visit Generative AI Innovation Center.
Multi-Task LearningDeepLearning is a towering pillar in the vast landscape of artificial intelligence, revolutionising various domains with remarkable capabilities. DeepLearning algorithms have become integral to modern technology, from image recognition to Natural Language Processing.
A key finding is that for a fixed compute budget, training with up to four epochs of repeated data shows negligible differences in loss compared to training with unique data. The paper also explores alternative strategies to mitigate datascarcity.
Harnessing the power of deeplearning for image segmentation is revolutionizing numerous industries, but often encounters a significant obstacle – the limited availability of training data. Over the years, various successful deeplearning architectures have been developed for this task, such as U-Net or SegFormer.
While deeplearning’s scaling effects have driven advancements in AI, particularly in LLMs like GPT, further scaling during training faces limitations due to datascarcity and computational constraints.
Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios. Specifically, it solves two key problems: datascarcity and privacy concerns. Technique No.
Deep Dive: Convolutional Neural Network Algorithms for Specific Challenges CNNs, while powerful, face distinct challenges in their application, particularly in scenarios like datascarcity, overfitting, and unstructured data environments.
The most common example is security analytics , where deeplearning models analyze CCTV footage to detect theft, traffic violations, or intrusions in real-time. ResNet Residual Neural Networks ( ResNets ) use the CNN architecture to learn complex visual patterns. This is the result of very small gradients during backpropagation.
Here are a few of the significant challenges: Data Availability: The availability of high-quality and diverse linguistic data for training and fine-tuning AI models for several languages is a major roadblock in multilingual prompt engineering. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Our software helps several leading organizations start with computer vision and implement deeplearning models efficiently with minimal overhead for various downstream tasks. For instance, recent research from Carnegie Mellon developed a framework to use audio and text to learn about visual data. Get a demo here.
Harnessing the power of deeplearning for image segmentation is revolutionizing numerous industries, but often encounters a significant obstacle the limited availability of training data. Over the years, various successful deeplearning architectures have been developed for this task, such as U-Net or SegFormer.
Data and Computational Requirements Generalizing models requires massive datasets for training, which aren’t always available or easy to collect. Processing this data also demands significant computational resources, especially for deeplearning models.
Data and Computational Requirements Generalizing models requires massive datasets for training, which aren’t always available or easy to collect. Processing this data also demands significant computational resources, especially for deeplearning models.
Gen AI, particularly through deeplearning models, has shown remarkable accuracy in diagnosing diseases from medical images. Overcoming Data Limitations In healthcare, the availability and quality of data can be significant barriers to research and development.
Gen AI, particularly through deeplearning models, has shown remarkable accuracy in diagnosing diseases from medical images. Overcoming Data Limitations In healthcare, the availability and quality of data can be significant barriers to research and development.
He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deeplearning applications. Kshitiz Gupta is a Solutions Architect at NVIDIA. Outside of work, he enjoys running, hiking, and wildlife watching.
For tabular learning, where datasets are typically smaller and structured, tree-based models often compete effectively with larger deep-learning models. Interpretability in machine learning aims to provide human-understandable explanations of a model’s internal reasoning process.
Muzic is a “research project on AI music that empowers music understanding and generation with deeplearning and artificial intelligence.” Muzic is a research project from Microsoft that uses deeplearning techniques for music generation and understanding – source.
This capability allows organisations to expand their datasets without the need for extensive data collection, thus enhancing model training and performance while addressing issues of datascarcity and imbalance effectively.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content