This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It emerged to address challenges unique to ML, such as ensuring dataquality and avoiding bias, and has become a standard approach for managing ML models across business functions. LLMs require massive computing power, advanced infrastructure, and techniques like promptengineering to operate efficiently.
First is clear alignment of the data strategy with the business goals, making sure the technology teams are working on what matters the most to the business. Second, is dataquality and accessibility, the quality of the data is critical. Poor dataquality will lead to inaccurate insights.
When you connect an AI agent or chatbot to these systems and begin asking questions, you'll get different answers because the data definitions aren't aligned. Poor dataquality creates a classic “ garbage in, garbage out ” scenario that becomes exponentially more serious when AI tools are deployed across an enterprise.
But it means that companies must overcome the challenges experienced so far in GenAII projects, including: Poor dataquality: GenAI ends up only being as good as the data it uses, and many companies still dont trust their data.
Sponsor When Generative AI Gets It Wrong, TrainAI Helps Make It Right TrainAI provides promptengineering, response refinement and red teaming with locale-specific domain experts to fine-tune GenAI. Need data to train or fine-tune GenAI? Download 20 must-ask questions to find the right data partner for your AI project.
Must-Have PromptEngineering Skills, Preventing Data Poisoning, and How AI Will Impact Various Industries in 2024 Must-Have PromptEngineering Skills for 2024 In this comprehensive blog, we reviewed hundreds of promptengineering job descriptions to identify the skills, platforms, and knowledge that employers are looking for in this emerging field.
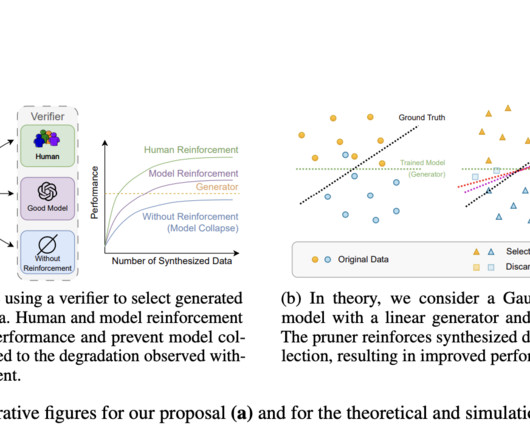
Current methods to counteract model collapse involve several approaches, including using Reinforcement Learning with Human Feedback (RLHF), data curation, and promptengineering. RLHF leverages human feedback to ensure the dataquality used for training, thereby maintaining or enhancing model performance.
This includes handling unexpected inputs, adversarial manipulations, and varying dataquality without significant degradation in performance. To learn more about CoT and other promptengineering techniques for Amazon Bedrock LLMs, see General guidelines for Amazon Bedrock LLM users.
More generalist skill sets were helpful to cultivate further professional opportunities in the pre-AI era of work, but today businesses need specialists with deep expertise in specific work related to the tech, such as data extraction or dataquality analysis. Relearning learning.
In summary, text embeddings trained on LLM-generated synthetic data establish new state-of-the-art results, while using simpler and more efficient training compared to prior multi-stage approaches. With further research intoprompt engineering and synthetic dataquality, this methodology could greatly advance multilingual text embeddings.
Fine-tuning Anthropic’s Claude 3 Haiku has demonstrated superior performance compared to few-shot promptengineering on base Anthropic’s Claude 3 Haiku, Anthropic’s Claude 3 Sonnet, and Anthropic’s Claude 3.5 The process is inherently iterative, allowing for continuous improvement as new data or requirements emerge.
Structured data is important in this process, as it provides a clear and organized framework for the AI to learn from, unlike messy or unstructured data, which can lead to ambiguities. Employ Data Templates With dataquality, implementing data templates offers another layer of control and precision.
Gary identified three major roadblocks: DataQuality and Integration AI models require high-quality, structured, and connected data to function effectively. The Future of Analytics Careers in an AI-Powered World Given these shifts, what skills will be most valuable for future data professionals?
LLM alignment techniques come in three major varieties: Promptengineering that explicitly tells the model how to behave. Supervised fine-tuning with targeted and curated prompts and responses. Dataquality dependency: Success depends heavily on having high-quality preference data.
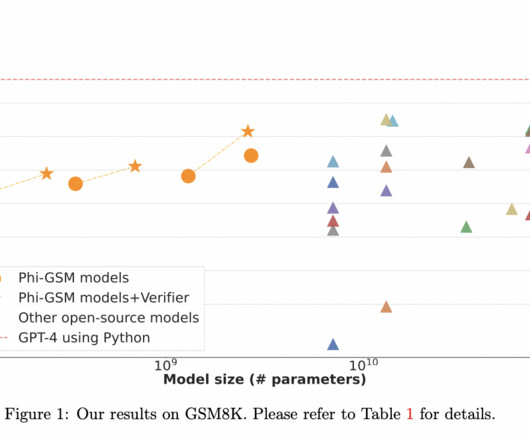
Researchers propose leveraging high-quality datasets like TinyGSM and a verifier model for optimal output selection from multiple candidate generations to achieve this. Filtering ensures dataquality, excluding short problems or non-numeric content. By fine-tuning a 1.3B generation model and a 1.3B
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack.
Current Challenges with Llama 2 Data Generalization : Both Llama 2 and GPT-4 sometimes falter in uniformly high performance across divergent tasks. Dataquality and diversity are just as pivotal as volume in these scenarios. Additionally, the license prohibits the use of LLaMa 2 for the improvement of other language models.
This approach, he noted, applies equally to leveraging AI in areas like data management, marketing, and customer service. Right now, effective promptengineering requires a careful balance of clarity, specificity, and contextual understanding to get the most useful responses from an AI model.
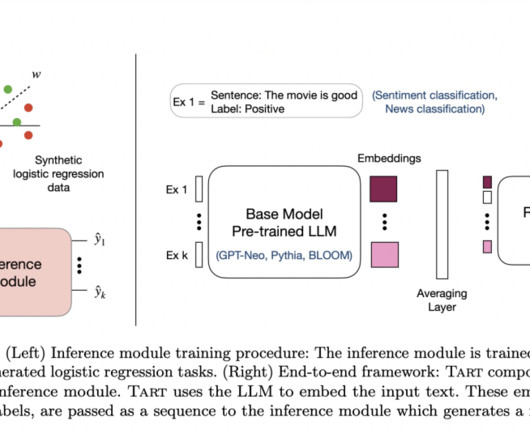
Surprisingly, most methods for narrowing the performance gap, such as promptengineering and active example selection, only target the LLM’s learned representations. In particular, Tart achieves the necessary goals: • Task-neutral: Tart’s inference module must be trained once with fictitious data.
Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. Promptengineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes.
PromptEngineering : Engineering precise prompts is vital to elicit accurate and reliable responses from LLMs, mitigating risks like model hallucination and prompt hacking. Training Data : The essence of a language model lies in its training data.
He identifies several key specializations within modern datascience: Data Science & Analysis: Traditional statistical modeling and machine learning applications. DataEngineering: The infrastructure and pipeline work that supports AI and datascience. Instead, they serve as powerful tools that can augment human capabilities.
W&B (Weights & Biases) W&B is a machine learning platform for your data science teams to track experiments, version and iterate on datasets, evaluate model performance, reproduce models, visualize results, spot regressions, and share findings with colleagues. Data monitoring tools help monitor the quality of the data.
PromptEngineering This involves carefully crafting prompts to provide context and guide the LLM towards factual, grounded responses. Heavily depend on training dataquality and external knowledge sources. Retrieval augmentation – Retrieving external evidence to ground content.
Regardless of the approach, the training process for DSLMs involves exposing the model to large volumes of domain-specific textual data, such as academic papers, legal documents, financial reports, or medical records. While these efforts have made significant strides, the development and deployment of healthcare LLMs face several challenges.
Data Observability for Real-Time Analysis In an era where real-time decision-making is critical, data observability will gain traction in 2024. Businesses will increasingly adopt data observability platforms that monitor the health of data pipelines, track dataquality, and provide instant insights.
Data Observability for Real-Time Analysis In an era where real-time decision-making is critical, data observability will gain traction in 2024. Businesses will increasingly adopt data observability platforms that monitor the health of data pipelines, track dataquality, and provide instant insights.
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis.
LLM alignment techniques come in three major varieties: Promptengineering that explicitly tells the model how to behave. Supervised fine-tuning with targeted and curated prompts and responses. Dataquality dependency: Success depends heavily on having high-quality preference data.
PromptengineeringPromptengineering refers to efforts to extract accurate, consistent, and fair outputs from large models, such text-to-image synthesizers or large language models. For more information, refer to EMNLP: Promptengineering is the new feature engineering.
Effective mitigation strategies involve enhancing dataquality, alignment, information retrieval methods, and promptengineering. Broadly speaking, we can reduce hallucinations in LLMs by filtering responses, promptengineering, achieving better alignment, and improving the training data.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few. He is currently focused on Generative AI, LLMs, promptengineering, and scaling Machine Learning across enterprises.
Inadequate PromptEngineering: Prompts should be treated as critical components of the system, with version control and transparency to ensure consistent performance. Focus on dataquality over quantity. Curated datasets can yield better results than massive, unfiltered datasets.
You’ll also be introduced to promptengineering, a crucial skill for optimizing AI interactions. In particular, you’ll explore the criticality of dataquality and availability, making data accessible through APIs, and techniques for making data GenAI-ready. Sign me up! Are you intrigued?
ODSC West Confirmed Sessions Pre-Bootcamp Warmup and Self-Paced Sessions Data Literacy Primer* Data Wrangling with SQL* Programming with Python* Data Wrangling with Python* Introduction to AI* Introduction to NLP Introduction to R Programming Introduction to Generative AI Large Language Models (LLMs) PromptEngineering Introduction to Fine-Tuning LLMs (..)
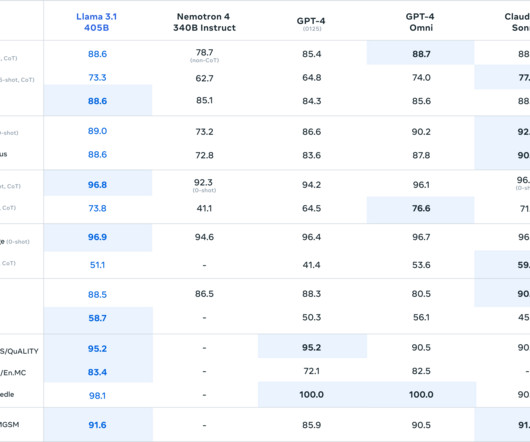
DataQuality and Processing: Meta significantly enhanced their data pipeline for Llama 3.1: DataQuality and Processing: Meta significantly enhanced their data pipeline for Llama 3.1: DataQuality and Processing: Meta significantly enhanced their data pipeline for Llama 3.1:
Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% AI users are definitely facing these problems: 7% report that dataquality has hindered further adoption, and 4% cite the difficulty of training a model on their data.
You can adapt foundation models to downstream tasks in the following ways: PromptEngineering: Promptengineering is a powerful technique that enables LLMs to be more controllable and interpretable in their outputs, making them more suitable for real-world applications with specific requirements and constraints.
Among other topics, he highlighted how visual prompts and parameter-efficient models enable rapid iteration for improved dataquality and model performance.
Among other topics, he highlighted how visual prompts and parameter-efficient models enable rapid iteration for improved dataquality and model performance.
For example, if you are working on a virtual assistant, your UX designers will have to understand promptengineering to create a natural user flow. All of this might require new skills on your team such as promptengineering and conversational design.
Some of the other key dimensions and themes that they have improved upon with regards to model development: DataQuality and Diversity: The quality and diversity of training data is crucial for model performance. 👷 The LLM Engineer focuses on creating LLM-based applications and deploying them.
We have someone from Adobe using it to help manage some promptengineering work that they’re doing, for example. We have someone precisely using it more for feature engineering, but using it within a Flask app. One of the features that Hamilton has is that it has a really lightweight dataquality runtime check.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































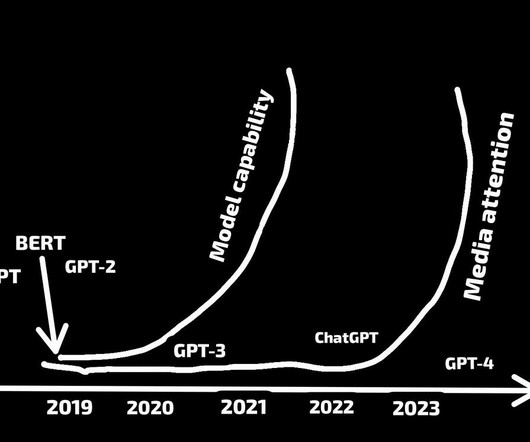


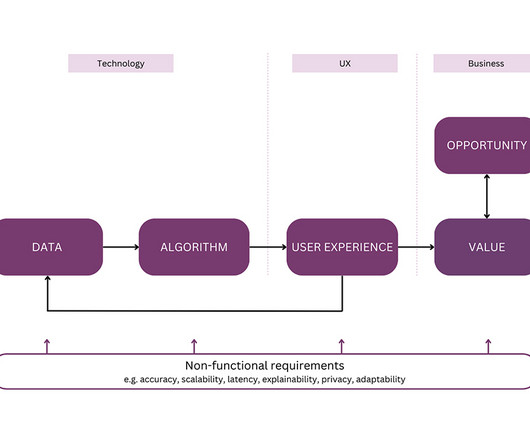








Let's personalize your content