This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
Also, the article demonstrates the technique using both synthetic and real stock price data, showcasing its potential for identifying patterns and volatility differences in financial markets. It covers key considerations like balancing dataquality versus quantity, ensuring data diversity, and selecting the right tuning method.
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). They are huge, complex, and data-hungry. They also need a lot of data to learn from, which can raise dataquality, privacy, and ethics issues. However, LLMs are also very different from other models.
Adding linguistic techniques in SAS NLP with LLMs not only help address quality issues in text data, but since they can incorporate subject matter expertise, they give organizations a tremendous amount of control over their corpora.
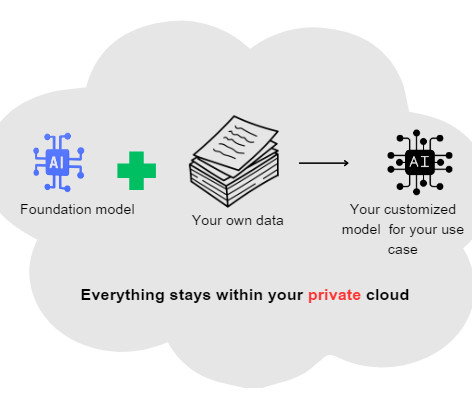
Data: the foundation of your foundation model Dataquality matters. An AI model trained on biased or toxic data will naturally tend to produce biased or toxic outputs. When objectionable data is identified, we remove it, retrain the model, and repeat. Data curation is a task that’s never truly finished.
Plus, natural language processing (NLP) and AI-driven search capabilities help businesses better understand user intent, enabling them to optimize product descriptions and attributes to match how customers actually search.
Language models have become a cornerstone of modern NLP, enabling significant advancements in various applications, including text generation, machine translation, and question-answering systems. Recent research has focused on scaling these models in terms of the amount of training data and the number of parameters.
Intelligent insights and recommendations Using its large knowledge base and advanced natural language processing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. These data sources provide contextual information and serve as a knowledge base for the LLM.
Test Management Tools TestRail integrates AI to streamline test management by generating test cases through NLP. Its AI-driven quality risk analysis recommends tests for high-risk areas, ensuring that critical issues are covered. It goes one step further and prioritizes each test case based on risk.
A critical challenge in multilingual NLP is the uneven distribution of linguistic resources. High-resource languages benefit from extensive corpora, while languages spoken in developing regions often lack sufficient training data.
In the ever-evolving field of Natural Language Processing (NLP), the development of machine translation and language models has been primarily driven by the availability of vast training datasets in languages like English. This limitation hampers the progress of NLP technologies for a wide range of linguistic communities worldwide.
The emergence of large language models (LLMs) such as Llama, PaLM, and GPT-4 has revolutionized natural language processing (NLP), significantly advancing text understanding and generation. Understanding hallucinations’ various types and underlying causes is crucial for developing effective mitigation strategies.
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
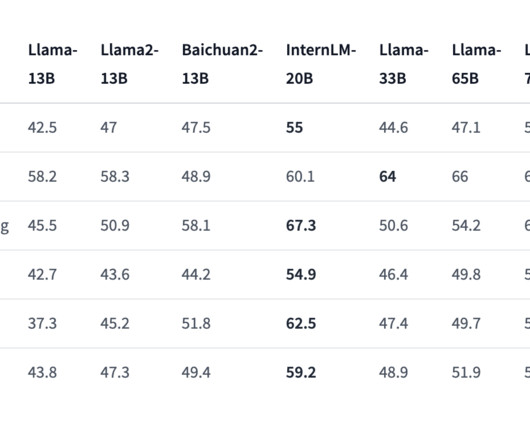
InternLM-20B represents a significant leap forward in language model architecture and training dataquality. This depth empowers the model to excel in language understanding, a crucial aspect of NLP. What truly sets InternLM-20B apart is its training data.
at Google, and “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” by Patrick Lewis, et al., For example, a mention of “NLP” might refer to natural language processing in one context or neural linguistic programming in another. Chunk your documents from unstructured data sources, as usual in GraphRAG.
In this presentation, we delve into the effective utilization of Natural Language Processing (NLP) agents in the context of Acciona. We explore a range of practical use cases where NLP has been deployed to enhance various processes and interactions.
NLP, or Natural Language Processing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges.
This limitation has paved the way for more advanced solutions that harness the power of Natural Language Processing (NLP). This has spurred the development of more advanced solutions powered by Natural Language Processing (NLP) that offer a more comprehensive approach to language-related tasks.
These models have played an important role in this dynamic field by influencing natural language processing (NLP) significantly. AI’s Yi models that focus on dataquality. This paper highlights the most influential open-source LLMs like Mistral’s sparse Mixture of Experts model Mixtral-8x7B, Alibaba Cloud’s multilingual Qwen1.5
Our customers are working on a wide range of applications, including augmented and virtual reality, computer vision , conversational AI, generative AI, search relevance and speech and natural language processing (NLP), among others.
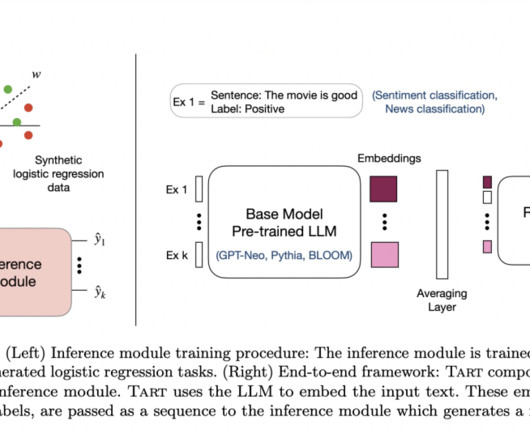
In particular, Tart achieves the necessary goals: • Task-neutral: Tart’s inference module must be trained once with fictitious data. Quality: Performs better than basic LLM across the board and closes the gap using task-specific fine-tuning techniques. Data-scalable: Handling 10 times as many instances as in-context learning.
Unlike traditional AI, which operates within predefined rules and tasks, It uses advanced technologies like Machine Learning, Natural Language Processing (NLP) , and Large Language Models (LLMs) to navigate complex, dynamic environments. It uses Natural Language Processing (NLP) to facilitate seamless communication between humans and AI.
The retrieval component uses Amazon Kendra as the intelligent search service, offering natural language processing (NLP) capabilities, machine learning (ML) powered relevance ranking, and support for multiple data sources and formats. Focus should be placed on dataquality through robust validation and consistent formatting.
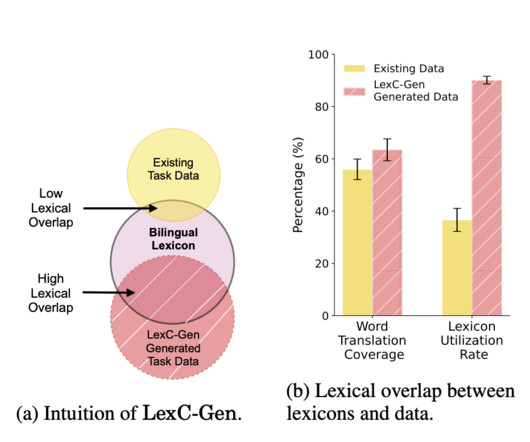
Extremely low-resource languages need more labeled data, widening the gap in NLP progress compared to high-resource languages. Lexicon-based cross-lingual data augmentation involves swapping words in high-resource language data with their translations from bilingual lexicons to generate data for low-resource languages.
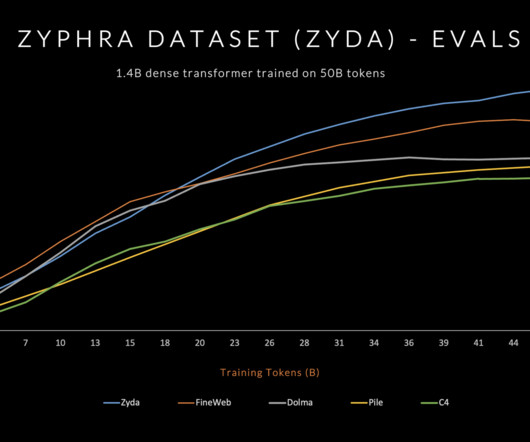
Zyda amalgamates several high-quality open datasets, refining them through rigorous filtering and deduplication. The result is a dataset that boasts an impressive token count and maintains the highest dataquality standards. This aligns with Zyphra’s commitment to fostering open research and collaboration in NLP.
Enter Natural Language Processing (NLP) and its transformational power. This is the promise of NLP: to transform the way we approach legal discovery. The seemingly impossible chore of sorting through mountains of legal documents can be accomplished with astonishing efficiency and precision using NLP.
John Snow Labs Debuts Comprehensive Healthcare Data Library on Databricks Marketplace: Over 2,400 Expertly Curated, Clean, and Enriched Datasets Now Accessible, Amplifying Data Science Capabilities in Healthcare and Life Sciences.
The field of Natural Language Processing (NLP) has been greatly impacted by the advancements in machine learning, leading to a significant improvement in linguistic understanding and generation. However, new challenges have emerged with the development of these powerful NLP models. Is Your NLP Model Truly Robust?
To do this, Pixability had trained a natural language processing (NLP) model to classify videos automatically, yet the performance wasn’t strong enough. Goal Minimize the time spent labeling high-cardinality training data while expanding their ability to provide more granular insights to their customers.
Understanding the Impact of Bias on NLP Models Why test NLP models for Bias? Natural Language Processing (NLP) models rely heavily on bias to function effectively. This is due to the fact that bias helps NLP models to identify important features and relationships among data points.
Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. This facilitates various NLP tasks by providing meaningful word embeddings. This piece compares and contrasts between the two models. The story starts with word embedding. What is Word Embedding?
Denoising Autoencoders (DAEs) Denoising autoencoders are trained on corrupted versions of the input data. The model learns to reconstruct the original data from this noisy input, making them effective for tasks like image denoising and signal processing. They help improve dataquality by filtering out noise.
Natural Language Processing (NLP) Entity Annotation: Tagging entities like names, dates, or locations. Speech-to-Text Alignment: Transcript creation for NLP processing is known as speech-to-text alignment. Advantages of Data Labeling Better Predictions: Accurate models are the outcome of high-quality labeling.
2021) 2021 saw many exciting advances in machine learning (ML) and natural language processing (NLP). If CNNs are pre-trained the same way as transformer models, they achieve competitive performance on many NLP tasks [28]. Popularized by GPT-3 [32] , prompting has emerged as a viable alternative input format for NLP models.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. With further research intoprompt engineering and synthetic dataquality, this methodology could greatly advance multilingual text embeddings.
Multilingual applications and cross-lingual tasks are central to natural language processing (NLP) today, making robust embedding models essential. However, existing models often struggle with noisy training data, limited domain diversity, and inefficiencies in managing multilingual datasets. and released under the MIT license.
The initial version of DataPerf consists of four challenges focused on three common data-centric tasks across three application domains; vision, speech and natural language processing (NLP). Training dataset evaluation (NLP) : Quality datasets can be expensive to construct, and are becoming valuable commodities.
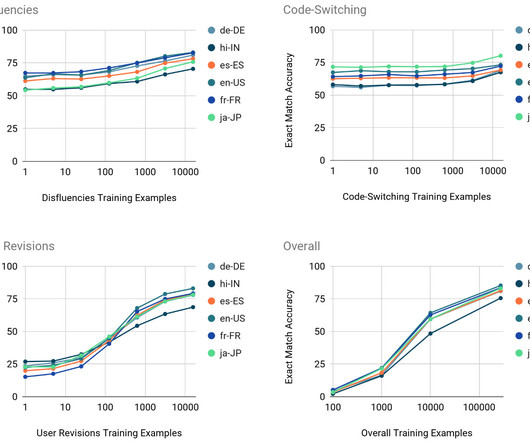
In the natural language processing (NLP) literature, this is mainly framed as a task-oriented dialogue parsing task, where a given dialogue needs to be parsed by a system to understand the user intent and carry out the operation to fulfill that intent. Examples of utterances in English, Japanese, and French with filler words or repetitions.
Data engineering is crucial in today’s digital landscape as organizations increasingly rely on data-driven insights for decision-making. Learning data engineering ensures proficiency in designing robust data pipelines, optimizing data storage, and ensuring dataquality.
At Appen, we work at the intersection of AI and data, and my experience has allowed me to lead the company and navigate complexities in the rapidly evolving AI space, moving through major developments like voice recognition, NLP, recommendation systems, and now generative AI. Dataquality plays a crucial role in AI model development.
In the domain of Artificial Intelligence (AI) , workflows are essential, connecting various tasks from initial data preprocessing to the final stages of model deployment. This foundational step requires clean and well-structured data to facilitate accurate model training. Next, efficient model training is critical.
AI and ML applications have improved dataquality, rigor, detection, and chemical identification, facilitating major disease screening and diagnosis findings. This process involves matching m/z and MS/MS fragmentation data to confirm metabolites.
Challenges of building custom LLMs Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues. Acquiring a significant volume of domain-specific data can be challenging, especially if the data is niche or sensitive.
Dandelion Health is a provider of multimodal, longitudinal clinical data for healthcare innovators. This session shows how it built a de-identification process for free-text clinical notes, with John Snow Labs’ Healthcare NLP & LLM at its core. Breaking down different note types (e.g.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content