This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
To operate effectively, multimodal AI requires large amounts of high-qualitydata from multiple modalities, and inconsistent dataquality across modalities can affect the performance of these systems.
Rethinking AI’s Pace Throughout History Although it feels like the buzz behind AI began when OpenAI launched ChatGPT in 2022, the origin of artificial intelligence and naturallanguageprocessing (NLPs) dates back decades. Inadequate access to data means life or death for AI innovation within the enterprise.
Adding linguistic techniques in SAS NLP with LLMs not only help address quality issues in text data, but since they can incorporate subject matter expertise, they give organizations a tremendous amount of control over their corpora.
With daily advancements in machine learning , naturallanguageprocessing , and automation, many of these companies identify as “cutting-edge,” but struggle to stand out. As of 2024, there are approximately 70,000 AI companies worldwide, contributing to a global AI market value of nearly $200 billion.
Akeneo's Supplier Data Manager (SDM) is designed to streamline the collection, management, and enrichment of supplier-provided product information and assets by offering a user-friendly portal where suppliers can upload product data and media files, which are then automatically mapped to the retailer's and/or distributors data structure.
Alix Melchy is the VP of AI at Jumio, where he leads teams of machine learning engineers across the globe with a focus on computer vision, naturallanguageprocessing and statistical modeling. The role of AI in identity verification will continue to expand significantly over the next five years.
LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in NaturalLanguageProcessing (NLP). They are huge, complex, and data-hungry.
Researchers continually strive to build models that can understand, reason, and generate text like humans in the rapidly evolving field of naturallanguageprocessing. These models must grapple with complex linguistic nuances, bridge language gaps, and adapt to diverse tasks. Check out the Project and Github.
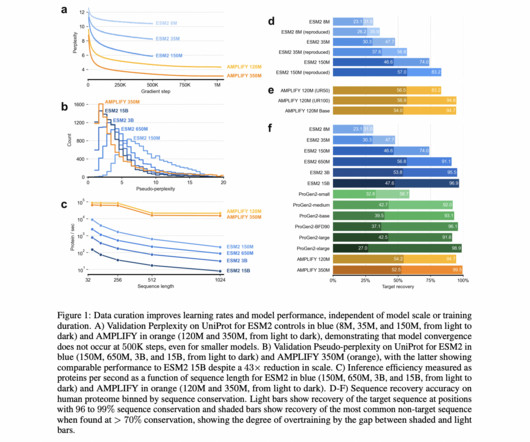
Unlike large-scale models like ESM2 and ProGen2, AMPLIFY focuses on improving dataquality rather than model size, achieving superior performance with 43 times fewer parameters. The team evaluated three strategies—dataquality, quantity, and training steps—finding that improving dataquality alone can create state-of-the-art models.
In the ever-evolving field of NaturalLanguageProcessing (NLP), the development of machine translation and language models has been primarily driven by the availability of vast training datasets in languages like English. This hands-on approach ensured the dataset met the highest quality standards.
The emergence of large language models (LLMs) such as Llama, PaLM, and GPT-4 has revolutionized naturallanguageprocessing (NLP), significantly advancing text understanding and generation. Conclusion Hallucinations in LLMs present significant challenges to their practical deployment and reliability.
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
The advancements in large language models have significantly accelerated the development of naturallanguageprocessing , or NLP. These extend far beyond the traditional text-based processing of LLMs to include multimodal interactions.
The retrieval component uses Amazon Kendra as the intelligent search service, offering naturallanguageprocessing (NLP) capabilities, machine learning (ML) powered relevance ranking, and support for multiple data sources and formats.
Our customers are working on a wide range of applications, including augmented and virtual reality, computer vision , conversational AI, generative AI, search relevance and speech and naturallanguageprocessing (NLP), among others.
In the domain of Artificial Intelligence (AI) , workflows are essential, connecting various tasks from initial data preprocessing to the final stages of model deployment. These structured processes are necessary for developing robust and effective AI systems. Next, efficient model training is critical.
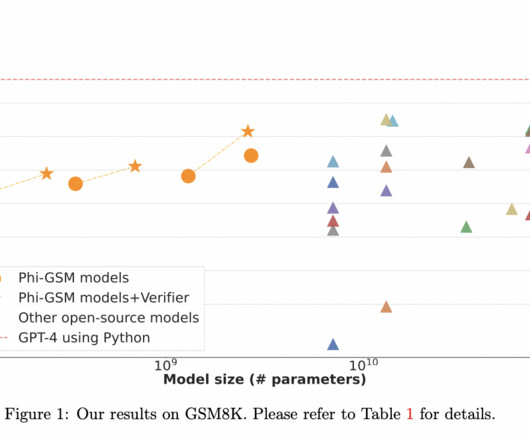
Departing from conventional approaches, Phi-2 relies on meticulously curated high-quality training data and leverages knowledge transfer from smaller models, presenting a formidable challenge to the established norms in language model scaling. The crux of Phi-2’s methodology lies in two pivotal insights.
Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
Denoising Autoencoders (DAEs) Denoising autoencoders are trained on corrupted versions of the input data. The model learns to reconstruct the original data from this noisy input, making them effective for tasks like image denoising and signal processing. They help improve dataquality by filtering out noise.
Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processingdata, and taking action to achieve specified goals. DataQuality and Bias: The effectiveness of AI agents depends on the quality of the data they are trained on.
Much like how foundation models in language, such as BERT and GPT, have transformed naturallanguageprocessing by leveraging vast textual data, pretrained foundation models hold similar promise for SDM.
These models have played an important role in this dynamic field by influencing naturallanguageprocessing (NLP) significantly. AI’s Yi models that focus on dataquality. series, Abacus AI’s Smaug, and 01.AI’s
Intelligent insights and recommendations Using its large knowledge base and advanced naturallanguageprocessing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. These insights can include: Potential adverse event detection and reporting.
At a recent Gartner event, Rita Sallam, distinguished vice-president analyst, said that at least 30% of GenAI projects will be dropped after POCs by the end of 2025 due to such issues as poor dataquality, insufficient risk controls, fast-growing costs, or an inability to realize desired business value. will, while 6.5%
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. Its diverse content includes academic papers, web data, books, and code. Frequently Asked Questions What is the Pile dataset?
In naturallanguageprocessing, the spotlight is shifting toward the untapped potential of small language models (SLMs). Filtering ensures dataquality, excluding short problems or non-numeric content. The study explores this pivotal question, delving into SLMs’ advantages and introducing TinyGSM.
GANs are a proven technique for creating realistic, high-quality synthetic data. Distilabel is a scalable, efficient, and flexible solution suitable for various AI applications, including image classification, naturallanguageprocessing, and medical imaging.
Unlike traditional AI, which operates within predefined rules and tasks, It uses advanced technologies like Machine Learning, NaturalLanguageProcessing (NLP) , and Large Language Models (LLMs) to navigate complex, dynamic environments. For example, a chatbot that understands user sentiment and intent through NLP.
Time and effort can be greatly decreased by using machine learning models that have been trained to label particular data categories. For accuracy, automation depends on a high-quality ground-truth dataset and frequently fails in edge circumstances. Pose estimation: The process of estimating human poses by marking important places.
Steps for building a successful AI strategy The following steps are commonly used to help craft an effective artificial intelligence strategy: Explore the technology Gain an understanding of various AI technologies, including generative AI , machine learning (ML), naturallanguageprocessing, computer vision, etc.
Developing and refining Large Language Models (LLMs) has become a focal point of cutting-edge research in the rapidly evolving field of artificial intelligence, particularly in naturallanguageprocessing. A recent survey by researchers from South China University of Technology, INTSIG Information Co.,
Dataquality plays a crucial role in AI model development. Could you share how Appen ensures the accuracy, diversity, and relevance of its datasets, especially with the increasing demand for high-quality LLM training data? We feel we are just at the beginning of the largest AI wave.
Training artificial intelligence (AI) models often requires massive amounts of labeled data. It can be highly expensive and time-consuming, especially for complex tasks like image recognition or naturallanguageprocessing. Annotating data is similar to finding a specific grain of sand on a beach.
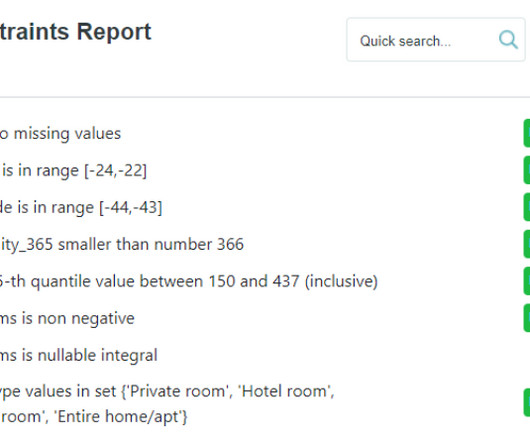
Let’s download the dataframe with: import pandas as pd df_target = pd.read_parquet("[link] /Listings/airbnb_listings_target.parquet") Let’s simulate a scenario where we want to assert the quality of a batch of production data. These constraints operate on top of statistical summaries of data, rather than on the raw data itself.
Word embedding is a technique in naturallanguageprocessing (NLP) where words are represented as vectors in a continuous vector space. This focus on understanding context is similar to the way YData Fabric, a dataquality platform designed for data […] The story starts with word embedding.
NLP, or NaturalLanguageProcessing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges.
These technologies have revolutionized computer vision, robotics, and naturallanguageprocessing and played a pivotal role in the autonomous driving revolution. Over the past decade, advancements in deep learning and artificial intelligence have driven significant strides in self-driving vehicle technology.
Advantages of vector databases Spatial Indexing – Vector databases use spatial indexing techniques like R-trees and Quad-trees to enable data retrieval based on geographical relationships, such as proximity and confinement, which makes vector databases better than other databases.
For example, a mention of “NLP” might refer to naturallanguageprocessing in one context or neural linguistic programming in another. A generalized, unbundled workflow A more accountable approach to GraphRAG is to unbundle the process of knowledge graph construction, paying special attention to dataquality.
The model series includes language-specific models capable of processing visual information alongside text. These are based on an evolved transformer architecture that’s been fine-tuned with a keen eye on dataquality, a factor that significantly boosts performance across various benchmarks.
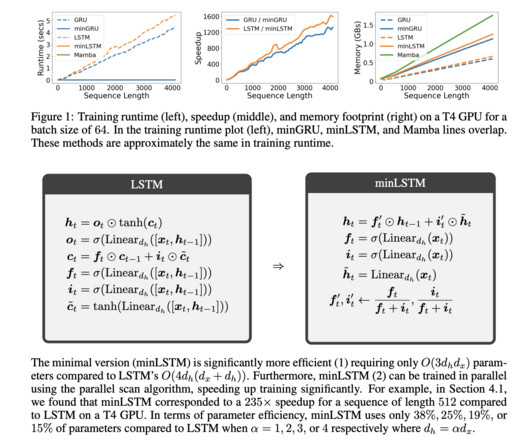
Recurrent neural networks (RNNs) have been foundational in machine learning for addressing various sequence-based problems, including time series forecasting and naturallanguageprocessing. indicating strong results across varying levels of dataquality. while the minGRU scored 79.4,
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




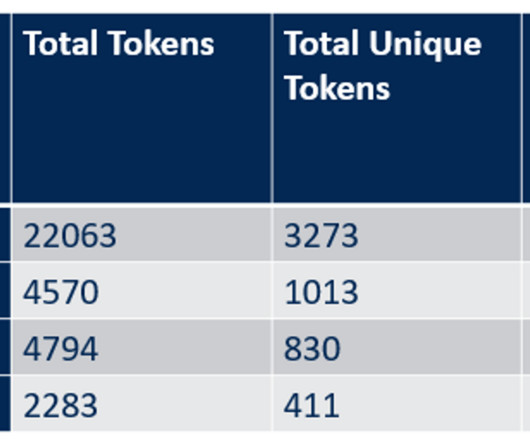




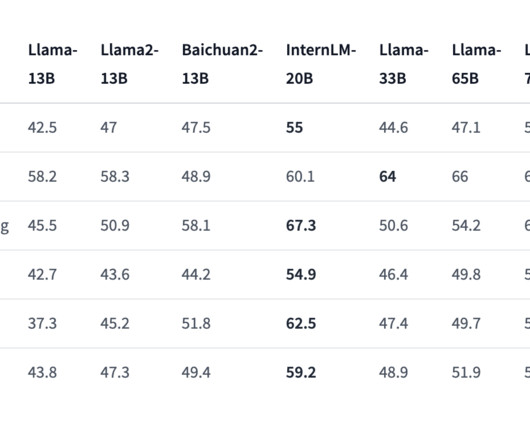
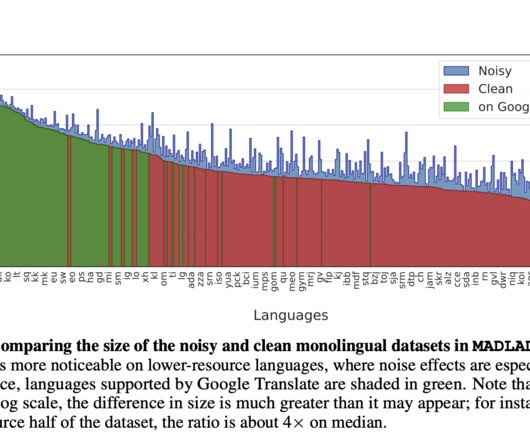





























Let's personalize your content