This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise-wide AI adoption faces barriers like dataquality, infrastructure constraints, and high costs. While Cirrascale does not offer DataQuality type services, we do partner with companies that can assist with Data issues. How does Cirrascale address these challenges for businesses scaling AI initiatives?
Edited Photo by Taylor Vick on Unsplash In MLengineering, dataquality isn’t just critical — it’s foundational. Since 2011, Peter Norvig’s words underscore the power of a data-centric approach in machine learning. Because of how ML practitioners were initially trained.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
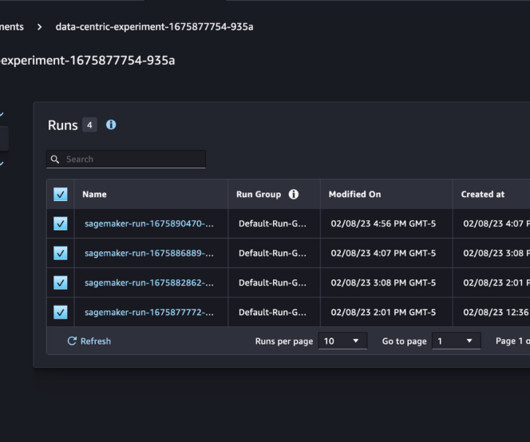
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. This allows you to keep track of your ML experiments. We specifically focus on SageMaker with MLflow.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
As industries begin adopting processes dependent on machine learning (ML) technologies, it is critical to establish machine learning operations (MLOps) that scale to support growth and utilization of this technology. There were noticeable challenges when running ML workflows in the cloud.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
In this post, I want to shift the conversation to how Deepseek is redefining the future of machine learning engineering. It has already inspired me to set new goals for 2025, and I hope it can do the same for other MLengineers. It is fascinating what Deepseek has achieved with their top noche engineering skill.
TL;DR Feedback integration is crucial for ML models to meet user needs. A robust ML infrastructure gives teams a competitive advantage. I started my ML journey as an analyst back in 2016. Mailchimp’s ML Platform: genesis, challenges, and objectives Mailchimp is a 20-year-old bootstrapped email marketing company.
Regulatory compliance By integrating the extracted insights and recommendations into clinical trial management systems and EHRs, this approach facilitates compliance with regulatory requirements for data capture, adverse event reporting, and trial monitoring. He helps customers implement big data, machine learning, and analytics solutions.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data.
As machine learning (ML) models have improved, data scientists, MLengineers and researchers have shifted more of their attention to defining and bettering dataquality. Applying these techniques allows ML practitioners to reduce the amount of data required to train an ML model.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any MLengineer, data scientist, or data analyst.
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
This is where visualizations in ML come in. Graphical representations of structures and data flow within a deep learning model make its complexity easier to comprehend and enable insight into its decision-making process. Data scientists and MLengineers: Creating and training deep learning models is no easy feat.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
The Role of Data Scientists and MLEngineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and MLengineers who play a critical role in harnessing the power of data and developing intelligent algorithms. We pay our contributors, and we don't sell ads.
While Vodafone has used AI/ML for some time in production, the growing number of use cases has posed challenges for industrialization and scalability. For Vodafone, it is key to rapidly build and deploy ML use cases at scale in a highly regulated industry. Once the Data Contract is agreed upon, it cannot change.
It’s critical for beginners learn this, since it affects everything: workflows, dataquality requirements, etc. Model mindset prioritizes the ML model that you are building. While product mindset focuses on the end data product: the minimum viable product. R&D’s focus IS building ML models and new algorithms.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Once the best model is identified, it is usually deployed in production to make accurate predictions on real-world data (similar to the one on which the model was trained initially). Ideally, the responsibilities of the MLengineering team should be completed once the model is deployed. But this is only sometimes the case.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Chief Data Scientist dive into data science’s history, impact, and challenges in the United States government. The center aimed to address recurring bottlenecks in their ML projects and improve collaborative workflows between data scientists and subject-matter experts. Current specialized ML libraries (e.g.,
Accelerate ML Adoption by Addressing Hidden Needs Max Williams, AI platform product manager at Wells Fargo , discussed the challenges of achieving a return on investment in machine learning as well as the hidden needs an organization must address for ML to gain widespread adoption and deliver attractive returns.
Accelerate ML Adoption by Addressing Hidden Needs Max Williams, AI platform product manager at Wells Fargo , discussed the challenges of achieving a return on investment in machine learning as well as the hidden needs an organization must address for ML to gain widespread adoption and deliver attractive returns.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Chief Data Scientist dive into data science’s history, impact, and challenges in the United States government. The center aimed to address recurring bottlenecks in their ML projects and improve collaborative workflows between data scientists and subject-matter experts. Current specialized ML libraries (e.g.,
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems Data Drift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
Data scrubbing is often used interchangeably but there’s a subtle difference. Cleaning is broader, improving dataquality. This is a more intensive technique within data cleaning, focusing on identifying and correcting errors. Data scrubbing is a powerful tool within this cleaning service.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. This includes dataquality, privacy, and compliance.
Chief Data Scientist dive into data science’s history, impact, and challenges in the United States government. The center aimed to address recurring bottlenecks in their ML projects and improve collaborative workflows between data scientists and subject-matter experts. Current specialized ML libraries (e.g.,
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Is more data always better?
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Is more data always better?
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Is more data always better?
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Jason Falks about deploying conversational AI products to production. Stephen: Great.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content