This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor dataquality can lead to inaccurate predictions and poor model performance.
Introduction Whether you’re a fresher or an experienced professional in the Data industry, did you know that ML models can experience up to a 20% performance drop in their first year? Monitoring these models is crucial, yet it poses challenges such as data changes, concept alterations, and dataquality issues.
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive data preparation capabilities powered by Amazon SageMaker Data Wrangler. Now you have a balanced target column.
Challenges of Using AI in Healthcare Physicians, doctors, nurses, and other healthcare providers face many challenges integrating AI into their workflows, from displacement of human labor to dataquality issues. Interoperability Problems and DataQuality Issues Data from different sources can often fail to integrate seamlessly.
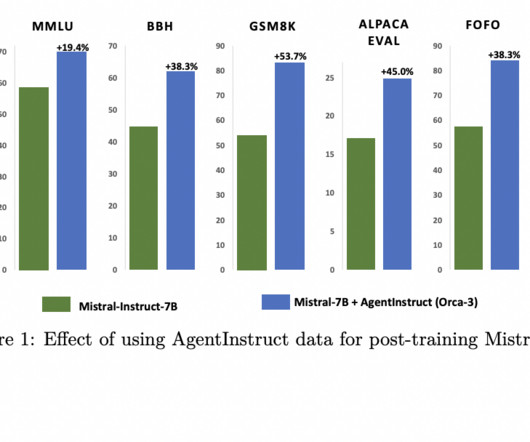
In conclusion, AgentInstruct represents a breakthrough in generating synthetic data for AI training. Automating the creation of diverse and high-qualitydata addresses the critical issues of manual curation and dataquality, leading to significant improvements in the performance and reliability of large language models.
Enterprise-wide AI adoption faces barriers like dataquality, infrastructure constraints, and high costs. While Cirrascale does not offer DataQuality type services, we do partner with companies that can assist with Data issues. How does Cirrascale address these challenges for businesses scaling AI initiatives?
Machine learning (ML) is a powerful technology that can solve complex problems and deliver customer value. However, ML models are challenging to develop and deploy. MLOps are practices that automate and simplify ML workflows and deployments. MLOps make ML models faster, safer, and more reliable in production.
Machine learning (ML) models are fundamentally shaped by data, and building inclusive ML systems requires significant considerations around how to design representative datasets.
With the increasing use of large models, requiring a large number of accelerated compute instances, observability plays a critical role in ML operations, empowering you to improve performance, diagnose and fix failures, and optimize resource utilization. This data makes sure models are being trained smoothly and reliably.
First is clear alignment of the data strategy with the business goals, making sure the technology teams are working on what matters the most to the business. Second, is dataquality and accessibility, the quality of the data is critical. Poor dataquality will lead to inaccurate insights.
When unstructured data surfaces during AI development, the DevOps process plays a crucial role in data cleansing, ultimately enhancing the overall model quality. Improving AI quality: AI system effectiveness hinges on dataquality. Poor data can distort AI responses.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with Data Integrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
Posted by Peter Mattson, Senior Staff Engineer, ML Performance, and Praveen Paritosh, Senior Research Scientist, Google Research, Brain Team Machine learning (ML) offers tremendous potential, from diagnosing cancer to engineering safe self-driving cars to amplifying human productivity. Each step can introduce issues and biases.
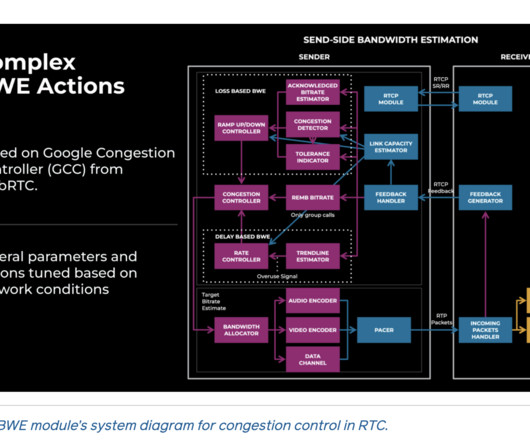
Researchers from Meta developed a machine learning (ML)-based approach to address the challenges of optimizing bandwidth estimation (BWE) and congestion control for real-time communication (RTC) across Meta’s family of apps. Meta’s ML-based approach involves two main components: offline ML model learning and parameter tuning.
AI and ML in Untargeted Metabolomics and Exposomics: Metabolomics employs a high-throughput approach to measure a variety of metabolites and small molecules in biological samples, providing crucial insights into human health and disease. The HRMS generates data in three dimensions: mass-to-charge ratio, retention time, and abundance.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
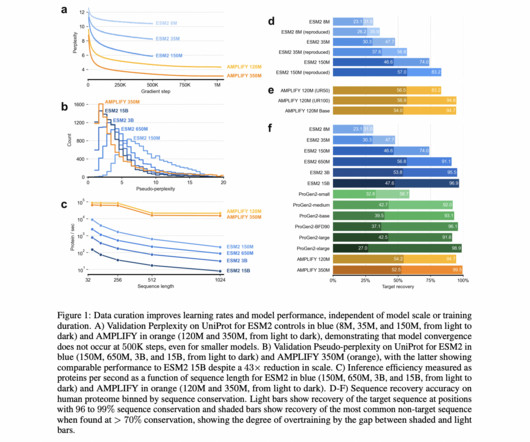
Unlike large-scale models like ESM2 and ProGen2, AMPLIFY focuses on improving dataquality rather than model size, achieving superior performance with 43 times fewer parameters. The team evaluated three strategies—dataquality, quantity, and training steps—finding that improving dataquality alone can create state-of-the-art models.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace.
The burgeoning expansion of the data landscape, propelled by the Internet of Things (IoT), presents a pressing challenge: ensuring dataquality amidst the deluge of information. However, the quality of that data is paramount, especially given the escalating reliance on Machine Learning (ML) across various industries.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
However, once deployed in a real-world setting, its performance plummeted due to dataquality issues and unforeseen biases. This scenario highlights a common reality in the Machine Learning landscape: despite the hype surrounding ML capabilities, many projects fail to deliver expected results due to various challenges.
Some of the APM strategies employed for this include: Predictive Maintenance: By using modern AI/ML capabilities to analyze big data , this strategy can monitor an asset’s health and forecast maintenance. Root Cause Analysis (RCA): This strategy emphasizes understanding the root causes of asset failures in a structured manner.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. This allows you to keep track of your ML experiments. We specifically focus on SageMaker with MLflow.
Read the full series here: Building the foundation for customer dataquality. The rapid advancement of artificial intelligence (AI) and machine learning (ML) technologies is pushing the boundaries of what can be achieved in marketing, customer experience … This article is part of a VB special issue.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Data Quantity Multilingual models require a larger vocabulary to represent tokens in many languages than monolingual models, but many languages lack large-scale datasets. DataQuality Concerns Ensuring the accuracy and cultural appropriateness of multilingual LLM outputs across languages is a significant concern.
Data Scientists and AI experts: Historically we have seen Data Scientists build and choose traditional ML models for their use cases. Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks.
This is the first one, where we look at some functions for dataquality checks, which are the initial steps I take in EDA. 🧰 The dummy data While Spark is famous for its ability to work with big data, for demo purposes, I have created a small dataset with an obvious duplicate issue. Let’s get started.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
By adopting technologies like artificial intelligence (AI) and machine learning (ML), companies can give a boost to their customer segmentation efforts. In those cases, a traditional approach run by humans can work better, especially if you mainly have qualitative data. Here’s a guide to help you accomplish that.
Akeneos Product Cloud solution has PIM, syndication, and supplier data manager capabilities, which allows retailers to have all their product data in one spot. While personalization is nothing new to brands, AI and ML technology allows brands to enter new levels of customer personalization to meet the high consumer expectations.
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
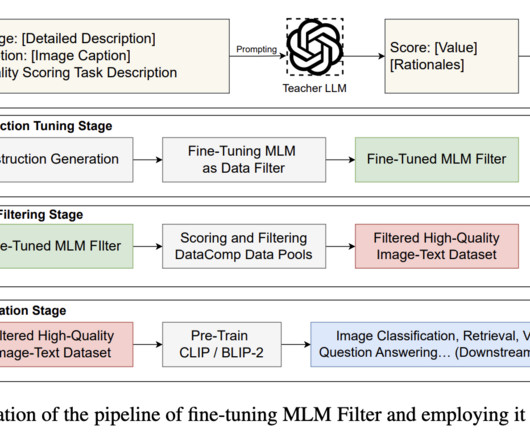
Their solution focuses on filtering image-text data, a novel approach that introduces a nuanced scoring system for dataquality evaluation, offering a more refined assessment than its predecessors. The research introduces a comprehensive scoring system that evaluates the quality of image-text pairs across four distinct metrics.
The retrieval component uses Amazon Kendra as the intelligent search service, offering natural language processing (NLP) capabilities, machine learning (ML) powered relevance ranking, and support for multiple data sources and formats. Focus should be placed on dataquality through robust validation and consistent formatting.
This calls for the organization to also make important decisions regarding data, talent and technology: A well-crafted strategy will provide a clear plan for managing, analyzing and leveraging data for AI initiatives. Identify potential partners and vendors Find companies in the AI and ML space that have worked within your industry.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Regulatory compliance By integrating the extracted insights and recommendations into clinical trial management systems and EHRs, this approach facilitates compliance with regulatory requirements for data capture, adverse event reporting, and trial monitoring. He helps customers implement big data, machine learning, and analytics solutions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content