This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Promptengineering that explicitly tells the model how to behave.
But it means that companies must overcome the challenges experienced so far in GenAII projects, including: Poor dataquality: GenAI ends up only being as good as the data it uses, and many companies still dont trust their data. Copilots are usually built using RAG pipelines. RAG is the Way. Prediction 4. Prediction 5.
Sponsor When Generative AI Gets It Wrong, TrainAI Helps Make It Right TrainAI provides promptengineering, response refinement and red teaming with locale-specific domain experts to fine-tune GenAI. Need data to train or fine-tune GenAI? Download 20 must-ask questions to find the right data partner for your AI project.
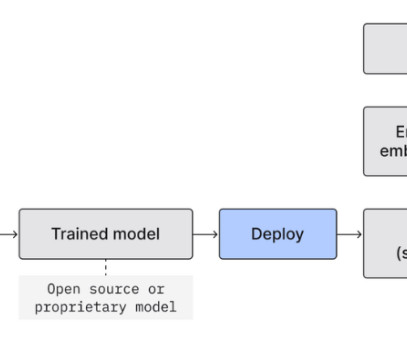
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. By fine-tuning, the LLM can adapt its knowledge base to specific data and tasks, resulting in enhanced task-specific capabilities.
Synthetic Data Generation: Prompt the LLM with the designed prompts to generate hundreds of thousands of (query, document) pairs covering a wide variety of semantic tasks across 93 languages. Model Training: Fine-tune a powerful open-source LLM such as Mistral on the synthetic data using contrastive loss.
This is where LLMOps steps in, embodying a set of best practices, tools, and processes to ensure the reliable, secure, and efficient operation of LLMs. Custom LLM Training : Developing a LLM from scratch promises an unparalleled accuracy tailored to the task at hand.
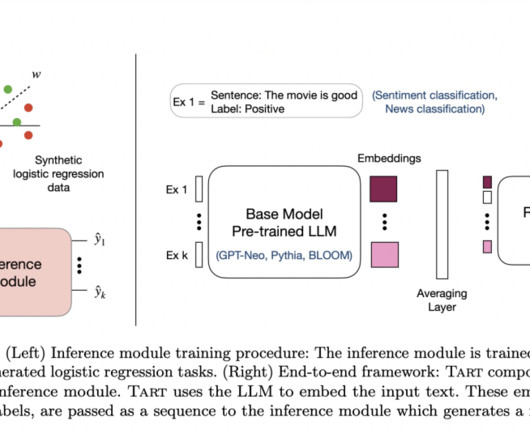
. • Quality: Across these several tasks, achieves accuracy competitive with task-specific approaches. Data-scalable: Learning efficiency increases as the number of task instances increases. They start by looking at the causes of the quality discrepancy.
This includes handling unexpected inputs, adversarial manipulations, and varying dataquality without significant degradation in performance. To learn more about CoT and other promptengineering techniques for Amazon Bedrock LLMs, see General guidelines for Amazon Bedrock LLM users.
Below are six ways discussed to prevent hallucinations in LLMs: Use High-QualityData The use of high-qualitydata is one simple-to-do thing. The data that trains an LLM serves as its primary knowledge base, and any shortcomings in this dataset can directly lead to flawed outputs.
TL;DR Hallucinations are an inherent feature of LLMs that becomes a bug in LLM-based applications. Causes of hallucinations include insufficient training data, misalignment, attention limitations, and tokenizer issues. What are LLM hallucinations? LLMs like GPT4o , Llama 3.1 , Claude 3.5 , or Gemini Pro 1.5
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Promptengineering that explicitly tells the model how to behave.
Taxonomy of Hallucination Mitigation Techniques Researchers have introduced diverse techniques to combat hallucinations in LLMs, which can be categorized into: 1. PromptEngineering This involves carefully crafting prompts to provide context and guide the LLM towards factual, grounded responses.
DataEngineering: The infrastructure and pipeline work that supports AI and datascience. Data Management & Governance: Ensuring dataquality, compliance, and security. Research & Project Management: Applying scientific methods and overseeing large-scale data initiatives.
Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. Promptengineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes.
W&B (Weights & Biases) W&B is a machine learning platform for your data science teams to track experiments, version and iterate on datasets, evaluate model performance, reproduce models, visualize results, spot regressions, and share findings with colleagues. Data monitoring tools help monitor the quality of the data.
You’ll also be introduced to promptengineering, a crucial skill for optimizing AI interactions. This two-hour session is crafted for AI practitioners who already possess a background in Python and familiarity with LangChain, aiming to elevate their skills in developing cutting-edge LLM agentic applications. Sign me up!
We must create new tools and best practices to manage the LLM application lifecycle to address these issues. " The LLMOps Steps LLMs, sophisticated artificial intelligence (AI) systems trained on enormous text and code datasets, have changed the game in various fields, from natural language processing to content generation.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few. He is currently focused on Generative AI, LLMs, promptengineering, and scaling Machine Learning across enterprises.
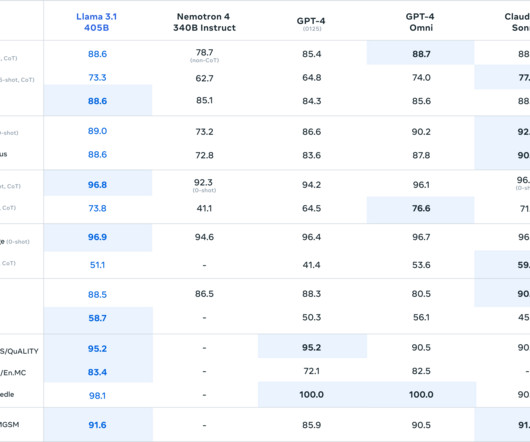
model size and data volume are significantly different as well as various strategies for data sampling. Articles Meta has announced the release of Llama 3.1 , latest and most capable open-source large language model (LLM) collection to date. Today, we had a special issue with Llama3.1
Some of the other key dimensions and themes that they have improved upon with regards to model development: DataQuality and Diversity: The quality and diversity of training data is crucial for model performance. 👷 The LLMEngineer focuses on creating LLM-based applications and deploying them.
That means curating an optimized set of prompts and responses for instruction tuning as well as cultivating the right mix of pre-training data for self-supervision. Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain.
That means curating an optimized set of prompts and responses for instruction tuning as well as cultivating the right mix of pre-training data for self-supervision. Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain.
For example, if you are working on a virtual assistant, your UX designers will have to understand promptengineering to create a natural user flow. All of this might require new skills on your team such as promptengineering and conversational design. Prompting is great to get a head-start into pre-trained models.
Understanding and addressing LLM vulnerabilities, threats, and risks during the design and architecture phases helps teams focus on maximizing the economic and productivity benefits generative AI can bring. This post provides three guided steps to architect risk management strategies while developing generative AI applications using LLMs.
It emerged to address challenges unique to ML, such as ensuring dataquality and avoiding bias, and has become a standard approach for managing ML models across business functions. With the rise of large language models (LLMs), however, new challenges have surfaced.
However, the world of LLMs isn't simply a plug-and-play paradise; there are challenges in usability, safety, and computational demands. In this article, we will dive deep into the capabilities of Llama 2 , while providing a detailed walkthrough for setting up this high-performing LLM via Hugging Face and T4 GPUs on Google Colab.
Regardless of the approach, the training process for DSLMs involves exposing the model to large volumes of domain-specific textual data, such as academic papers, legal documents, financial reports, or medical records. Here are some notable examples: Legal Domain Law LLM Assistant SaulLM-7B Equall.ai
As we enter the second wave of generative AI productization, companies are realizing that successfully implementing these technologies requires more than simply connecting an LLM to their data. While touted as a promising career path, promptengineering is essentially recreating the same barriers we've struggled with in data analytics.
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis.
ODSC West Confirmed Sessions Pre-Bootcamp Warmup and Self-Paced Sessions Data Literacy Primer* Data Wrangling with SQL* Programming with Python* Data Wrangling with Python* Introduction to AI* Introduction to NLP Introduction to R Programming Introduction to Generative AI Large Language Models (LLMs) PromptEngineering Introduction to Fine-Tuning LLMs (..)
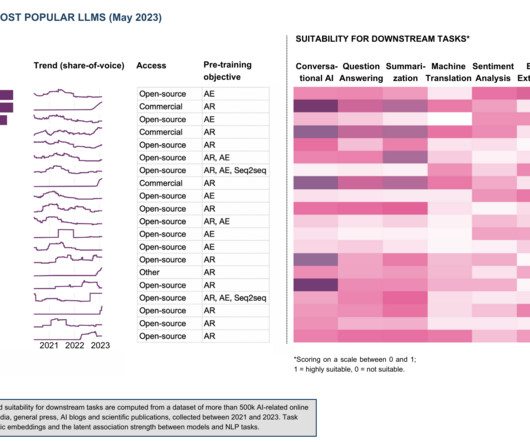
In October 2022, I published an article on LLM selection for specific NLP use cases , such as conversation, translation and summarisation. Open-source competes with for-profits, spurring innovation in LLM efficiency and scaling. Generative AI pushes autoregressive models, while autoencoding models are waiting for their moment.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content