This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
AI agents, on the other hand, hold a lot of promise but are still constrained by the reliability of LLM reasoning. From an engineering perspective, the core challenge for both lies in improving accuracy and reliability to meet real-world business requirements. They also inspired a bunch of new potentials for MLengineers.
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Data monitoring tools help monitor the quality of the data.
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content. Register now.
That means curating an optimized set of prompts and responses for instruction tuning as well as cultivating the right mix of pre-training data for self-supervision. Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain.
That means curating an optimized set of prompts and responses for instruction tuning as well as cultivating the right mix of pre-training data for self-supervision. Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content. Register now.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content.
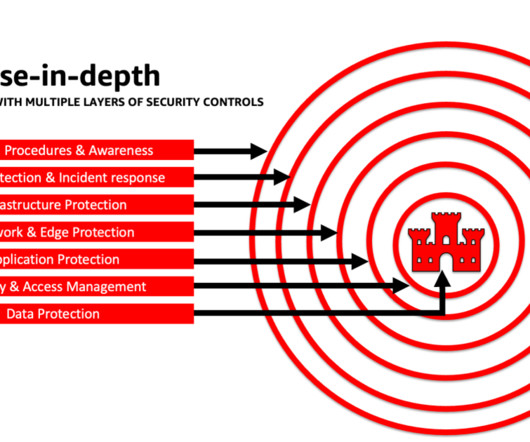
Understanding and addressing LLM vulnerabilities, threats, and risks during the design and architecture phases helps teams focus on maximizing the economic and productivity benefits generative AI can bring. This post provides three guided steps to architect risk management strategies while developing generative AI applications using LLMs.
. — Peter Norvig, The Unreasonable Effectiveness of Data. Edited Photo by Taylor Vick on Unsplash In MLengineering, dataquality isn’t just critical — it’s foundational. Since 2011, Peter Norvig’s words underscore the power of a data-centric approach in machine learning. Using biased or low-qualitydata?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content