This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. Data Scientist with AWS Professional Services. Raju Patil is a Sr.
The DataQuality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline. Within this pipeline, SageMaker on-demand DataQuality Monitor steps are incorporated to detect any drift when compared to the input data.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Your data team can manage large-scale, structured, and unstructured data with high performance and durability. Data monitoring tools help monitor the quality of the data.
GitLab CI/CD serves as the macro-orchestrator, orchestrating model build and model deploy pipelines, which include sourcing, building, and provisioning Amazon SageMaker Pipelines and supporting resources using the SageMaker Python SDK and Terraform. The central model registry could optionally be placed in a shared services account as well.
MLOps is the intersection of Machine Learning, DevOps, and Data Engineering. Dataquality: ensuring the data received in production is processed in the same way as the training data. Zero, “ How to write better scientific code in Python,” Towards Data Science, Feb. 15, 2022. [4]
The repository also includes additional Python source code with helper functions, used in the setup notebook, to set up required permissions. See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge",
Data-Planning to Implementation Balaji Raghunathan | VP of Digital Experience | ITC Infotech Over his 20+ year-long career, Balaji Raghunatthan has worked with cloud-based architectures, microservices, DevOps, Java, .NET, NET, and AWS.
Read Blog: W hich technologies combine to make data a critical organizational asset? Python Might Go Viral Yes, you read it right. While several programming languages play a significant role across different technologies, Python holds a special position. Add to this, Python has a friendly learning curve for beginners.
Experience with classical computer vision tools, such as OpenCV , object detection, image segmentation, data annotation, etc. Proficiency with one or more programming languages such as Python or C++, and tools like TensorFlow, and PyTorch. Verifying and validating annotations to maintain high dataquality and reliability.
If you want to add rules to monitor your data pipeline’s quality over time, you can add a step for AWS Glue DataQuality. And if you want to add more bespoke integrations, Step Functions lets you scale out to handle as much data or as little data as you need in parallel and only pay for what you use.
You essentially divide things up into large tasks and chunks, but the software engineering that goes within that task is the thing that you’re generally gonna be updating and adding to over time as your machine learning grows within your company or you have new data sources, you want to create new models, right? To figure it out.
Robustness You need an elastic data model to support: Varying team sizes and structures (a single data scientist only, or maybe a team of one data scientist, 4 machine learning engineers, 2 DevOps engineers, etc.). Varying workflows so users can decide what they want to track. Some will only track the post-training phase.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Data ingestion (extraction and versioning). Data validation (writing tests to check for dataquality). Data preprocessing. Model performance analysis and evaluation.
” — Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Monitoring Monitoring is an essential DevOps practice, and MLOps should be no different. Collaboration The principles you have learned in this guide are mostly born out of DevOps principles. My Story DevOps Engineers Who they are?
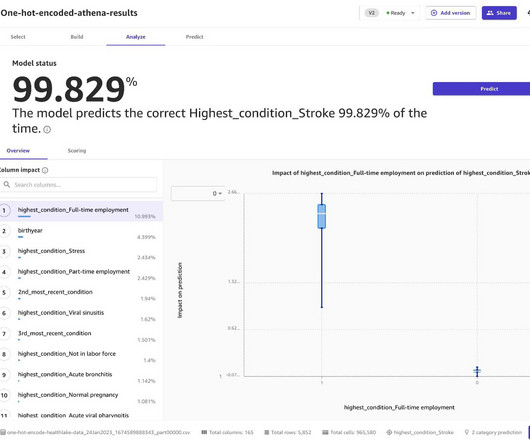
DataQuality and Standardization The adage “garbage in, garbage out” holds true. Inconsistent data formats, missing values, and data bias can significantly impact the success of large-scale Data Science projects. This builds trust in model results and enables debugging or bias mitigation strategies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content