This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As emerging DevOps trends redefine software development, companies leverage advanced capabilities to speed up their AI adoption. That’s why, you need to embrace the dynamic duo of AI and DevOps to stay competitive and stay relevant. How does DevOps expedite AI? Poor data can distort AI responses.
It serves as the hub for defining and enforcing data governance policies, data cataloging, data lineage tracking, and managing data access controls across the organization. Data lake account (producer) – There can be one or more data lake accounts within the organization.
Everything is data—digital messages, emails, customer information, contracts, presentations, sensor data—virtually anything humans interact with can be converted into data, analyzed for insights or transformed into a product. Managing this level of oversight requires adept handling of large volumes of data.
Enhanced Test Data Management With AI-driven tools, managing test data becomes much simpler. Solutions offering synthetic data generation and data masking ensure that the test data is realistic and accurate while protecting sensitive information. AI-powered QA is also becoming central to DevOps.
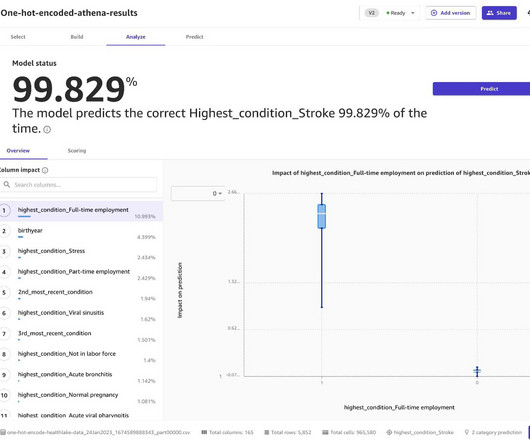
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. The information pertaining to the request and response is stored in Amazon S3.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
While seemingly a variant of MLOps or DevOps, LLMOps has unique nuances catering to large language models' demands. Training Data : The essence of a language model lies in its training data. The data'squality and diversity significantly impact the model's accuracy and versatility.
Can you debug system information? Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Can you compare images?
The need for MLOps at TWCo TWCo strives to help consumers and businesses make informed, more confident decisions based on weather. The DataQuality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline.
See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge", These are key files calculated from raw data used as a baseline.
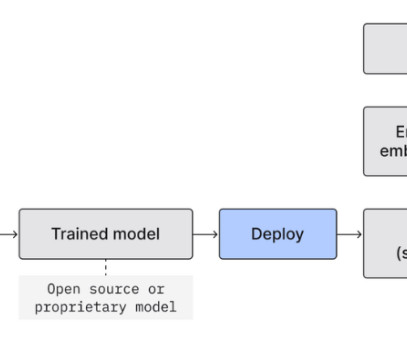
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a data science development account (which has more controls than a typical application development account). Refer to Operating model for best practices regarding a multi-account strategy for ML.
Data-Planning to Implementation Balaji Raghunathan | VP of Digital Experience | ITC Infotech Over his 20+ year-long career, Balaji Raghunatthan has worked with cloud-based architectures, microservices, DevOps, Java, .NET, NET, and AWS.
These challenges include a limited number of data science experts, the complexity of ML, and the low volume of data due to restricted Protected Health Information (PHI) and infrastructure capacity. No special permissions are required because the data doesn’t contain any sensitive information.
Consumer Data Protection Will Be The Prime Concern As we move into the digital world, there will be a growing demand for systems that can assure data safety. Consumers are now more aware and want complete confidence when it comes to the information they share. It is one of the best e-learning platforms for Data Science.
Verifying and validating annotations to maintain high dataquality and reliability. Good understanding of spatial data, 2D and 3D geometry, and coordinate systems. Staying informed on advances in computer vision and image technology relevant to annotation tasks. cars in traffic, or a medical condition in healthcare.
Information created intentionally rather than as a result of actual events is known as synthetic data. Synthetic data is generated algorithmically and used to train machine learning models, validate mathematical models, and act as a stand-in for test production or operational data test datasets.
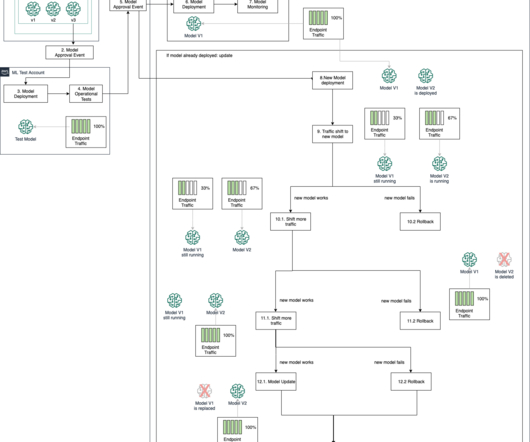
For general information on these patterns, refer to Take advantage of advanced deployment strategies using Amazon SageMaker deployment guardrails and Deployment guardrails. When the model update process is complete, SageMaker Model Monitor continually monitors the model performance for drifts into the model and dataquality.
They can’t be sure that a trained model (or models) will generalize to unseen data without monitoring and evaluating their experiments. The data science team can use this information to choose the best model, parameters, and performance metrics. Varying workflows so users can decide what they want to track.
Depending on your size, you might have a data catalog. Maybe storing and emitting open lineage information, etc. One of the features that Hamilton has is that it has a really lightweight dataquality runtime check. If you’re using tabular data, there’s Pandera. How to be a valuable MLOps Engineer?
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Data ingestion (extraction and versioning). Data validation (writing tests to check for dataquality). Data preprocessing. Model performance analysis and evaluation.
” — Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Monitoring Monitoring is an essential DevOps practice, and MLOps should be no different. Collaboration The principles you have learned in this guide are mostly born out of DevOps principles. My Story DevOps Engineers Who they are?
Archana Joshi brings over 24 years of experience in the IT services industry, with expertise in AI (including generative AI), Agile and DevOps methodologies, and green software initiatives. GenAI processes vast amounts of data to provide actionable insights. They were facing scalability and accuracy issues with their manual approach.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content