This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
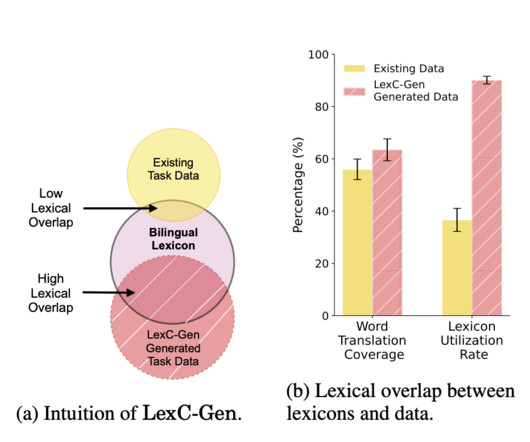
Datascarcity in low-resource languages can be mitigated using word-to-word translations from high-resource languages. However, bilingual lexicons typically need more overlap with task data, leading to inadequate translation coverage. This approach faces challenges with domain specificity and performance compared to native data.
Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios. Specifically, it solves two key problems: datascarcity and privacy concerns.
Introduction The field of natural language processing (NLP) and language models has experienced a remarkable transformation in recent years, propelled by the advent of powerful large language models (LLMs) like GPT-4, PaLM, and Llama. Issues such as datascarcity, bias, and noise can significantly impact model performance.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content