This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
Much like a solid foundation is essential for a structure's stability, an AI model's effectiveness is fundamentally linked to the quality of the data it is built upon. In recent years, it has become increasingly evident that even the most advanced AI models are only as good as the data they are trained on.
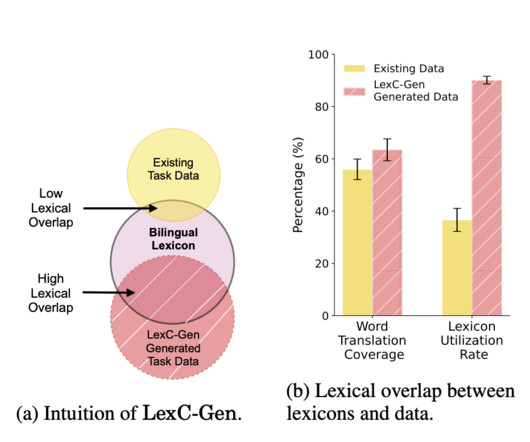
Datascarcity in low-resource languages can be mitigated using word-to-word translations from high-resource languages. However, bilingual lexicons typically need more overlap with task data, leading to inadequate translation coverage. This approach faces challenges with domain specificity and performance compared to native data.
The competitive dynamic between the two networks allows for continuous refinement of the synthetic data. As a result, the framework can generate high-quality, diverse datasets that can be applied to various domains, such as medical imaging or text generation, where dataquality is critical.
Availability of training data: Deep learning’s efficacy relies heavily on dataquality, with simulation environments bridging the gap between real-world datascarcity and training requirements.
The navigator then evaluates the fidelity of these instructions, filtering out low-qualitydata to train a better generator in subsequent iterations. This iterative refinement ensures continuous improvement in both the dataquality and the models’ performance.
Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios. Specifically, it solves two key problems: datascarcity and privacy concerns.
Ensuring dataquality, addressing potential biases, and maintaining strict privacy and security standards for sensitive medical data are the major concerns. Data Availability and Quality : Obtaining high-quality, domain-specific datasets is crucial for training accurate and reliable DSLMs.
Such richness and diversity promise to significantly reduce the time and resources data teams spend on improving dataquality, which has traditionally consumed up to 80% of their workload.
By leveraging GenAI, businesses can personalize customer experiences and improve dataquality while maintaining privacy and compliance. Introduction Generative AI (GenAI) is transforming Data Analytics by enabling organisations to extract deeper insights and make more informed decisions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content