This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
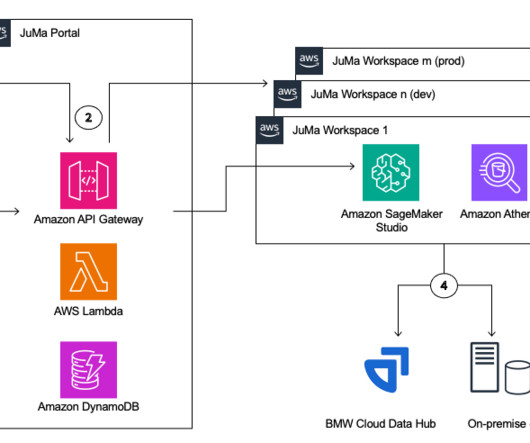
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and MLengineers require capable tooling and sufficient compute for their work. It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R.
We’ll also discuss some of the benefits of using set union(), and we’ll see why it’s a popular tool for Python developers. How to Build a 5-Layer Data Stack Spinning up a dataplatform doesn’t have to be complicated. Here are the 5 must-have layers to drive data product adoption at scale.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + PythonML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + PythonML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline?
SageMaker geospatial capabilities make it easy for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. The results of SUEWS are then visualized, in this case with Arup’s existing geospatial dataplatform.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and MLengineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. You could almost think of Hamilton as DBT for Python functions. Stefan: Yeah. Thanks for having me.
How did you manage to jump from a more analytical, scientific type of role to a more engineering one? I actually did not pick up Python until about a year before I made the transition to a data scientist role. I see so many of these job seekers, especially on the MLOps side or the MLengineer side. It’s two things.
It became apparent to both Razi and me that we had the opportunity to make a significant impact by radically simplifying the feature engineering process and providing data scientists and MLengineers with the right tools and user experience for seamless feature experimentation and feature serving.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content