This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataplatform architecture has an interesting history. A read-optimized platform that can integrate data from multiple applications emerged. In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different dataplatform solution.
Database metadata can be expressed in various formats, including schema.org and DCAT. Unfortunately, these formats weren’t made with machine learning data in mind. Google has recently introduced Croissant, a new format for metadata in ML-ready datasets. Users can then publish their datasets.
That is, it should support both sound data governance —such as allowing access only by authorized processes and stakeholders—and provide oversight into the use and trustworthiness of AI through transparency and explainability.
Year after year, IBM Consulting works with the United States Tennis Association (USTA) to transform massive amounts of data into meaningful insight for tennis fans. This year, the USTA is using watsonx , IBM’s new AI and dataplatform for business.
For use cases where accuracy is critical, customers need the use of mathematically sound techniques and explainable reasoning to help generate accurate FM responses. This includes watermarking, content moderation, and C2PA support (available in Amazon Nova Canvas) to add metadata by default to generated images.
Data lake foundations This module helps data lake admins set up a data lake to ingest data, curate datasets, and use the AWS Lake Formation governance model for managing fine-grained data access across accounts and users using a centralized data catalog, data access policies, and tag-based access controls.
This data source may be related to the sales sector, the manufacturing industry, finance, health, and R&D… Briefly, I am talking about a field-specific data source. The domain of the data. Regardless, the data fabric must be consistent for all its components. Data fabric needs metadata management maturity.
You will see an Amazon Simple Storage Service (Amazon S3) link to a metadata file. To discover the schema to be used while invoking the API from Einstein Studio, choose Information in the navigation pane of the Model Registry. Copy and paste the link into a new browser tab URL. Let’s look at the file without downloading it.
Tools range from dataplatforms to vector databases, embedding providers, fine-tuning platforms, prompt engineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. Model management Teams typically manage their models, including versioning and metadata.
There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata. We’re assuming that data scientists, for the most part, don’t want to write transformations elsewhere. Mikiko Bazeley: 100%. We offer that.
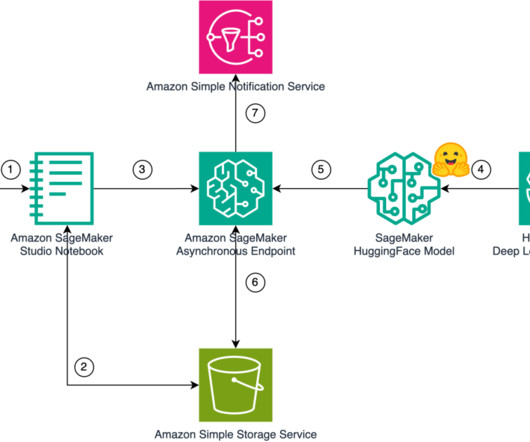
The following diagram explains the sequence of steps to invoke the asynchronous inference endpoint. Asynchronous music generation As soon as the response metadata is sent to the client, the asynchronous inference begins the music generation. He specializes in building dataplatforms and architecting seamless data ecosystems.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. You need to build your ML platform with experimentation and general workflow reproducibility in mind.
It’s often described as a way to simply increase data access, but the transition is about far more than that. When effectively implemented, a data democracy simplifies the data stack, eliminates data gatekeepers, and makes the company’s comprehensive dataplatform easily accessible by different teams via a user-friendly dashboard.
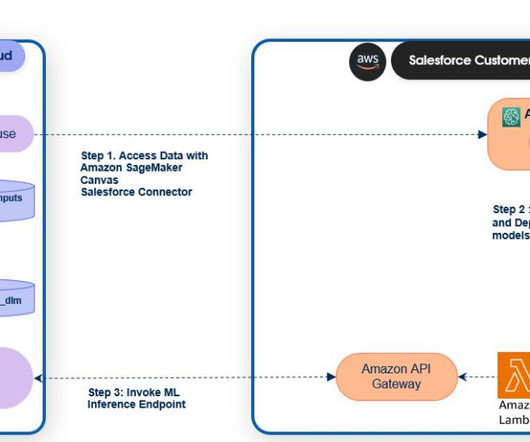
SageMaker Canvas provides a no-code experience to access data from Salesforce Data Cloud and build, test, and deploy models using just a few clicks. SageMaker Canvas also enables you to understand your predictions using feature importance and SHAP values, making it straightforward for you to explain predictions made by ML models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content