This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
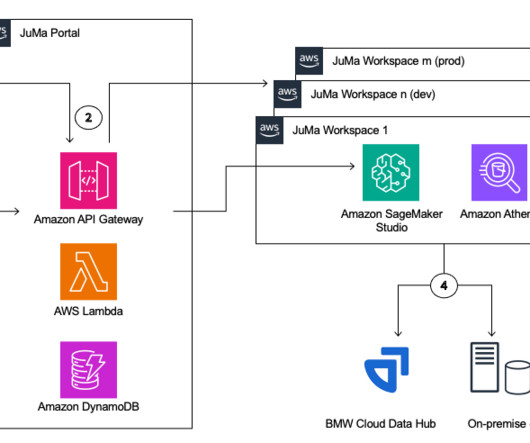
JuMa is a service of BMW Group’s AI platform for its data analysts, ML engineers, and data scientists that provides a user-friendly workspace with an integrated development environment (IDE). It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R.
This approach led to data scientists spending more than 50% of their time on operational tasks, leaving little room for innovation, and posed challenges in monitoring model performance in production. Snowflake is the preferred dataplatform, and it receives data from Step Functions state machine runs through Amazon CloudWatch logs.
Data Estate: This element represents the organizational data estate, potential data sources, and targets for a data science project. Data Engineers would be the primary owners of this element of the MLOps v2 lifecycle. The Azure dataplatforms in this diagram are neither exhaustive nor prescriptive.
Stefan is a software engineer, data scientist, and has been doing work as an ML engineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. You could almost think of Hamilton as DBT for Python functions. It gives a very opinionary way of writing Python.
I actually did not pick up Python until about a year before I made the transition to a data scientist role. I switched from analytics to data science, then to machine learning, then to data engineering, then to MLOps. You shifted straight from data science, if I understand correctly. It’s two things.
” — Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Monitoring Monitoring is an essential DevOps practice, and MLOps should be no different. Checking at intervals to make sure that model performance isn’t degrading in production is a good MLOps practice for both teams and platforms.
One popular library for implementing distributed training is DeepSpeed, a Python optimization library that handles distributed training and makes it memory-efficient and fast by enabling both data and model parallelization. He has expertise in AWS cloud services, DevOps practices, security, data analytics and generative AI.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content