This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
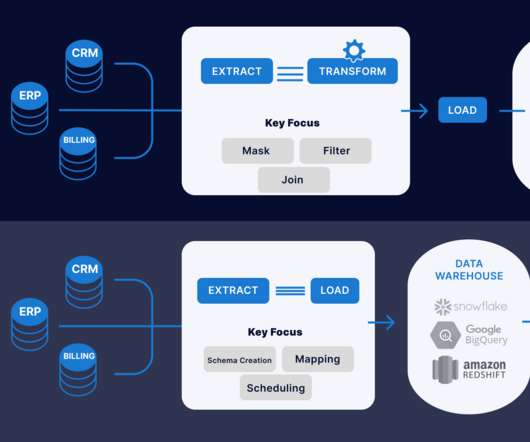
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
Users can take advantage of DATALORE’s data governance, dataintegration, and machine learning services, among others, on cloud computing platforms like Amazon Web Services, Microsoft Azure, and Google Cloud. This improves DATALORE’s efficiency by avoiding the costly investigation of search spaces.
With the advent of big data in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The Big Data and RTOS connection IoT and embedded devices are among the biggest sources of big data.
Summary : Data Analytics trends like generative AI, edge computing, and Explainable AI redefine insights and decision-making. Businesses harness these innovations for real-time analytics, operational efficiency, and data democratisation, ensuring competitiveness in 2025.
Consider these common scenarios: A perfect validation script cant fix inconsistent data entry practices The most robust ETL pipeline cant resolve disagreements about business rules Real-time quality monitoring cant replace clear data ownership. Another challenge is dataintegration and consistency.
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Top 50+ Interview Questions for Data Analysts Technical Questions SQL Queries What is SQL, and why is it necessary for data analysis? SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. Data Visualisation What are the fundamental principles of data visualisation?
It explains various architectures such as hierarchical, network, and relational models, highlighting their functionalities and importance in efficient data storage, retrieval, and management. Introduction In today’s data-driven world, organizations generate approximately 2.5
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen data scientists through open source and customized recipes. When necessary, the platform also enables numerous governance and explainability elements.
The platform’s schema independence allows you to directly consume data in any format or type. It contains native storage for specified schemas, which explains why. The supported formats include geospatial data, JSON, RDF, and large binaries like films. It will combine all of your data sources. Integrate.io
It also supports horizontal scaling through sharding, making it suitable for handling large volumes of data. Explain The Difference Between MongoDB and SQL Databases. MongoDB is a NoSQL database that stores data in documents, while SQL databases store data in tables with rows and columns.
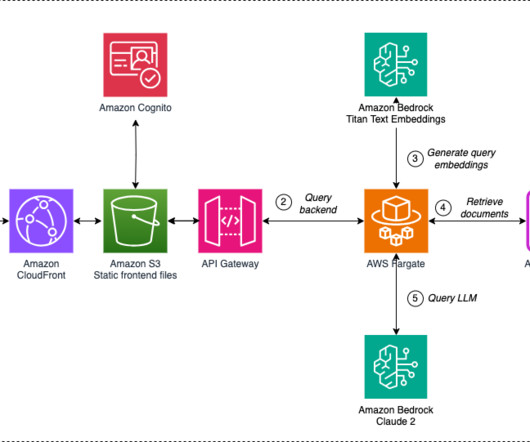
In this post, we explain how Cepsa Química and partner Keepler have implemented a generative AI assistant to increase the efficiency of the product stewardship team when answering compliance queries related to the chemical products they market. The following diagram illustrates this architecture.
Then, it applies these insights to automate and orchestrate the data lifecycle. Instead of handling extract, transform and load (ETL) operations within a data lake, a data mesh defines the data as a product in multiple repositories, each given its own domain for managing its data pipeline.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content