

What is Data Ingestion? Understanding the Basics
Pickl AI
JULY 25, 2024
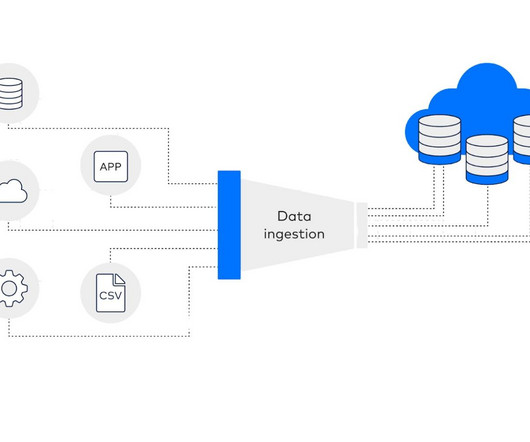
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where data ingestion comes in.






























Let's personalize your content