This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving landscape of artificial intelligence, the art of promptengineering has emerged as a pivotal skill set for professionals and enthusiasts alike. Promptengineering, essentially, is the craft of designing inputs that guide these AI systems to produce the most accurate, relevant, and creative outputs.
Large Language Models (LLMs) like GPT-4, Claude-4, and others have transformed how we interact with data, enabling everything from analyzing research papers to managing business reports and even engaging in everyday conversations. However, to fully harness their capabilities, understanding the art of promptengineering is essential.
With Amazon Bedrock Data Automation, this entire process is now simplified into a single unified API call. It also offers flexibility in dataextraction by supporting both explicit and implicit extractions. These analytics are implemented with either Amazon Comprehend , or separate promptengineering with FMs.
More generalist skill sets were helpful to cultivate further professional opportunities in the pre-AI era of work, but today businesses need specialists with deep expertise in specific work related to the tech, such as dataextraction or data quality analysis. Relearning learning.
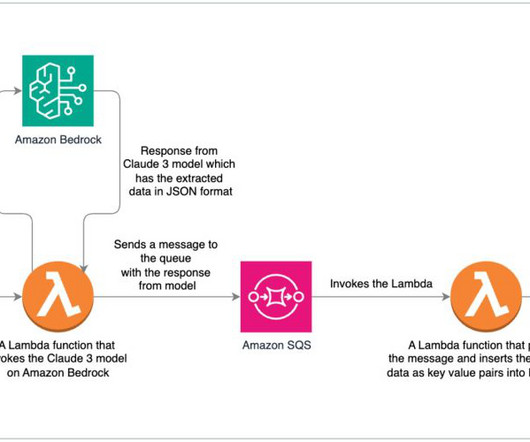
The architecture seamlessly integrates multiple AWS services with Amazon Bedrock, allowing for efficient dataextraction and comparison. The function constructs a detailed prompt designed to guide the Amazon Titan Express model in evaluating the universitys submission.
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. We also examine the uplift from fine-tuning an LLM for a specific extractive task. In this example, you explicitly set the instance type to ml.g5.48xlarge.
DataExtraction & Analysis : Summarizing large reports or extracting key insights from datasets using GPT-4’s advanced reasoning abilities. Implementing LLM APIs in Enterprise Applications Best Practices PromptEngineering : Craft precise prompts to guide model output effectively.
One of the key features of the o1 models is their ability to work efficiently across different domains, including natural language processing (NLP), dataextraction, summarization, and even code generation.
In this step we use a LLM for classification and dataextraction from the documents. Sonnet LLM: document processing for dataextraction and summarization of the extracted information. Sonnet alongside promptengineering techniques to refine outputs and meet specific requirements with precision.
We use Amazon Textract’s document extraction abilities with LangChain to get the text from the document and then use promptengineering to identify the possible document category. LangChain uses Amazon Textract’s DetectDocumentText API for extracting text from printed, scanned, or handwritten documents.
Prompt, In-context Learning and Chaining Step 1 You pick a model, give it a prompt, get a response, evaluate the response, and re-prompt if needed until you get the desired outcome. In-context learning is a promptengineering approach where language models learn tasks from a few natural language examples and try to perform them.
GM: Well before this training challenge, we had done a lot of work in organizing our data internally. We had spent a lot of time thinking about how to centralize the management and improve our dataextraction and processing. How you engineer the test set matters a ton for whether the model actually works in the real world.
GM: Well before this training challenge, we had done a lot of work in organizing our data internally. We had spent a lot of time thinking about how to centralize the management and improve our dataextraction and processing. How you engineer the test set matters a ton for whether the model actually works in the real world.
GM: Well before this training challenge, we had done a lot of work in organizing our data internally. We had spent a lot of time thinking about how to centralize the management and improve our dataextraction and processing. How you engineer the test set matters a ton for whether the model actually works in the real world.
It facilitates the seamless customization of FMs with enterprise-specific data using advanced techniques like promptengineering and RAG so outputs are relevant and accurate. SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS).
This combination enables advanced document understanding, highly effective structured dataextraction, automated document classification, and seamless information retrieval from unstructured text. decode('utf-8') Promptengineering is a critical factor in unlocking the full potential of generative AI applications like IDP.
Developers face significant challenges when using foundation models (FMs) to extractdata from unstructured assets. This dataextraction process requires carefully identifying models that meet the developers specific accuracy, cost, and feature requirements.
Task 1: Query generation from natural language This task’s objective is to assess a model’s capacity to translate natural language questions into SQL queries, using contextual knowledge of the underlying data schema. We used promptengineering guidelines to tailor our prompts to generate better responses from the LLM.
The architecture comprises three key components, as shown in the following diagram: orchestration, structured dataextraction, and intelligent response generation. Version management streamlines controlled testing of prompt variations. Built-in conditional logic handles different processing paths.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content