This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction NaturalLanguageProcessing (NLP) has recently received much attention in computationally representing and analyzing human speech. Machine translation is widely used in many fields such as spam detection, dataextraction, typing, medicine, question answering, and more.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent dataextraction. However, it encounters challenges with handwritten text, especially when the visuals are intricate or difficult to process.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
Plus, naturallanguageprocessing (NLP) and AI-driven search capabilities help businesses better understand user intent, enabling them to optimize product descriptions and attributes to match how customers actually search. to create those tailored product recommendations.
NaturalLanguageProcessing has emerged as a powerful tool in oncology research as it extracts and analyzes information from unstructured clinical text like pathology reports, electronic health records ( EHRs ), radiology reports, and clinical notes.
Learn NLPdataprocessing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk Many data we analyze as data scientists consist of a corpus of human-readable text.
Naturallanguageprocessing (NLP) is a core part of artificial intelligence. But how can you find the best books on NLP? 10 Must-read Books on NLP One quick note before we jump into the list. Some of these books cover more basic NLP elements. NaturalLanguageProcessing Succinctly Author : Joseph D.
Medical dataextraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical naturallanguageprocessing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP.
In essence, this study combines Country Recognition with Sentiment Analysis, leveraging the RoBERTa NLP model for Named Entity Recognition (NER) and Sentiment Classification to explore how sentiments vary across different geographical regions. lower() + ' ' + row['comment_body'].lower()
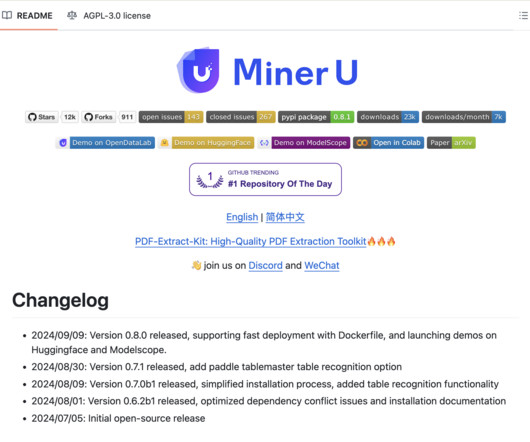
The model particularly focuses on ensuring the accurate extraction of crucial components like formulas, tables, and images, helping researchers acquire required data. MinerU’s architecture relies on naturallanguageprocessing (NLP) and machine learning (ML) techniques to extract and organize data effectively.
Companies can use high-quality human-powered data annotation services to enhance ML and AI implementations. In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. Prodigy offers the support in the paid version.
Summary: Deep Learning models revolutionise dataprocessing, solving complex image recognition, NLP, and analytics tasks. Introduction Deep Learning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. With a projected market growth from USD 6.4
Please see the data provided below, which will be used for the purpose of this blog. It can analyze the text-based input provided by the user, interpret the query, and generate a response based on the content of the tabular data. Instead, we can use ChatGPT to generate SQL statements for a database that contains the data.
In this presentation, we delve into the effective utilization of NaturalLanguageProcessing (NLP) agents in the context of Acciona. We explore a range of practical use cases where NLP has been deployed to enhance various processes and interactions.
DataExtraction & Analysis : Summarizing large reports or extracting key insights from datasets using GPT-4’s advanced reasoning abilities. Cohere Cohere specializes in naturallanguageprocessing (NLP) and provides scalable solutions for enterprises, enabling secure and private data handling.
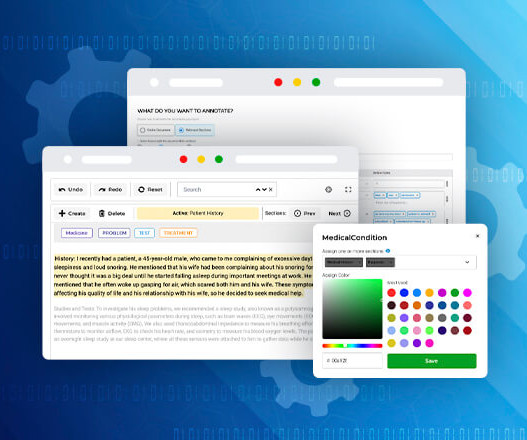
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. This growing prevalence underscores the need for advanced tools to analyze and interpret the vast amounts of clinical data generated in oncology.
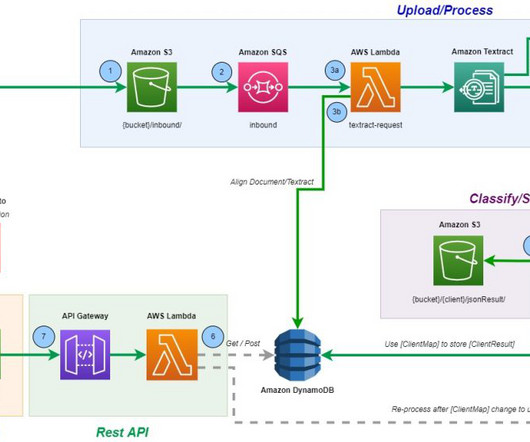
In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes dataextraction, management, and governance. The solution integrates data in three tiers. Then we move to the next stage of accessing the actual dataextracted from the raw unstructured data.
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and dataextraction, among other skills. This 10-hour course, also highly rated at 4.8,
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. Dataextraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data.
The realm of NaturalLanguageProcessing has been growing exponentially, bringing about a host of advancements that are pushing the boundaries of technology and its application. Automatic Section Identification The NLP Lab has made section identification a breeze.
While domain experts possess the knowledge to interpret these texts accurately, the computational aspects of processing large corpora require expertise in machine learning and naturallanguageprocessing (NLP). Meta’s Llama 3.1, Alibaba’s Qwen 2.5
Clone Researchers have developed various benchmarks to evaluate naturallanguageprocessing (NLP) tasks involving structured data, such as Table NaturalLanguage Inference (NLI) and Tabular Question Answering (QA). The Locating scenario involves questions about the optimal placement of resources (e.g.,
This blog explores the performance and comparison of de-identification services provided by Healthcare NLP, Amazon, and Azure, focusing on their accuracy when applied to a dataset annotated by healthcare experts. John Snow Labs Healthcare NLP & LLM library offers a powerful solution to streamline the de-identification of medical records.
These development platforms support collaboration between data science and engineering teams, which decreases costs by reducing redundant efforts and automating routine tasks, such as data duplication or extraction. It does this by identifying named entities, parsing terms and conditions, and more.
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards naturallanguageprocessing (NLP). 2020 ) and language modelling ( Khandelwal et al., In NLP, Gunel et al. 2020 ; Lewis et al.,
While the GPT-4 series laid the foundation with its generalized language understanding and generation capabilities, o1 models were designed with improvements in context handling, resource efficiency, and task flexibility.
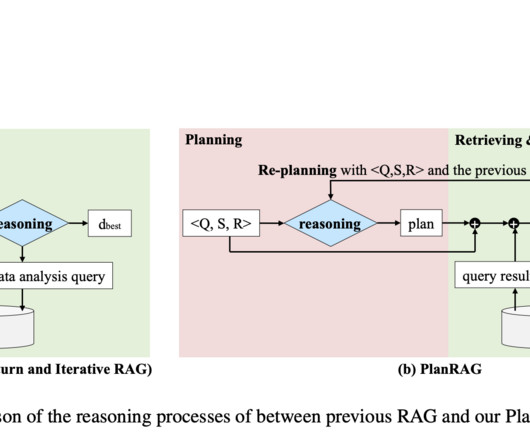
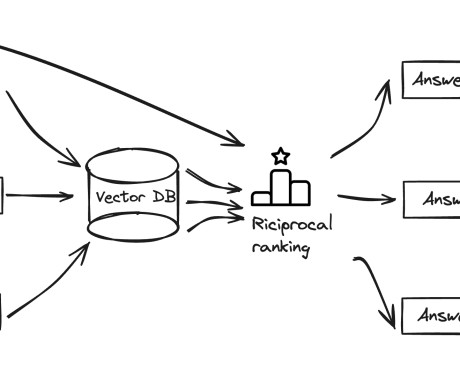
Retrieval Augmented Generation (RAG) models have emerged as a promising approach to enhance the capabilities of language models by incorporating external knowledge from large text corpora. Naive RAG models face limitations such as missing content, reasoning mismatch, and challenges in handling multimodal data.
Now, AI has evolved to understand and process complex document structures, making it an indispensable tool in modern business environments. In the past, Optical Character Recognition (OCR) and NaturalLanguageProcessing (NLP) were the main technologies used for document automation. LLMs are like language wizards.
An IDP pipeline usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. Define and track key metrics related to document accuracy, processing times, and model efficacy.
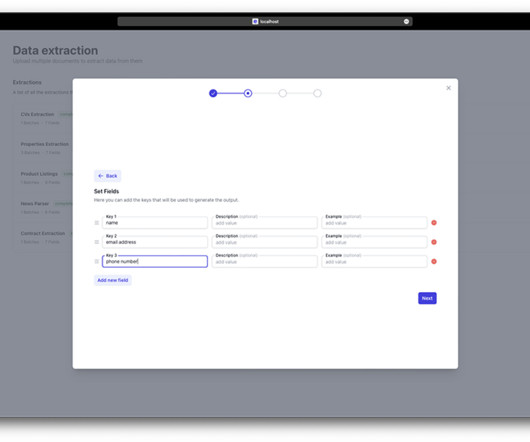
Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents. You can apply human-in-the-loop to all types of deep learning AI projects, including naturallanguageprocessing (NLP), computer vision, and transcription.
Research And Discovery: Analyzing biomarker dataextracted from large volumes of clinical notes can uncover new correlations and insights, potentially leading to the identification of novel biomarkers or combinations with diagnostic or prognostic value.
By using the advanced naturallanguageprocessing (NLP) capabilities of Anthropic Claude 3 Haiku, our intelligent document processing (IDP) solution can extract valuable data directly from images, eliminating the need for complex postprocessing.
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
Use NaturalLanguageProcessing (NLP) NLP techniques can be used to make processing documents even better. It is possible to get more accurate dataextraction with the help of NLP, which helps understand the context and meaning of the text.
This blog explores the performance and comparison of de-identification services provided by Healthcare NLP, Amazon, Azure, and OpenAI focusing on their accuracy when applied to a dataset annotated by healthcare experts. Its important to note that this pipeline does not rely on any LLM components.
An IDP project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author.
Whether you’re looking to classify documents, extract keywords, detect and redact personally identifiable information (PIIs), or parse semantic relationships, you can start ideating your use case and use LLMs for your naturallanguageprocessing (NLP).
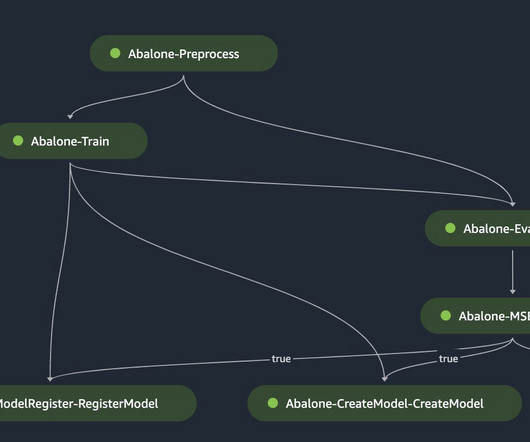
We use a typical pipeline flow, which includes steps such as dataextraction, training, evaluation, model registration and deployment, as a reference to demonstrate the advantages of Selective Execution. SageMaker Pipelines allows you to define runtime parameters for your pipeline run using pipeline parameters.
AI Research Assistant are sophisticated tools designed to aid researchers in their quest for knowledge, providing support in data collection , analysis, and interpretation. Data Analysis Once data is collected, AI assistants employ Machine Learning techniques to analyse it. naturallanguageprocessing models for text analysis).
Introduction Deep Learning has revolutionised the tech landscape, driving innovations in AI-powered applications like image recognition, naturallanguageprocessing, and autonomous systems. Each layer transforms the input data, extracting increasingly complex features.
R’s machine learning capabilities allow for model training, evaluation, and deployment. · Text Mining and NaturalLanguageProcessing (NLP): R offers packages such as tm, quanteda, and text2vec that facilitate text mining and NLP tasks.
Large language models have taken the world by storm, offering impressive capabilities in naturallanguageprocessing. This pairing is invaluable as it demonstrates how unstructured data, often found in naturallanguage texts, can be systematically broken down and translated into a structured format.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content