This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction NaturalLanguageProcessing (NLP) has recently received much attention in computationally representing and analyzing human speech. Machine translation is widely used in many fields such as spam detection, dataextraction, typing, medicine, question answering, and more.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Rethinking AI’s Pace Throughout History Although it feels like the buzz behind AI began when OpenAI launched ChatGPT in 2022, the origin of artificial intelligence and naturallanguageprocessing (NLPs) dates back decades.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
Plus, naturallanguageprocessing (NLP) and AI-driven search capabilities help businesses better understand user intent, enabling them to optimize product descriptions and attributes to match how customers actually search. to create those tailored product recommendations.
Intelligent document processing and its importance Intelligent document processing is a more advanced type of automation based on AI technology, machine learning, naturallanguageprocessing, and optical character recognition to collect, process, and organise data from multiple forms of paperwork.
NaturalLanguageProcessing has emerged as a powerful tool in oncology research as it extracts and analyzes information from unstructured clinical text like pathology reports, electronic health records ( EHRs ), radiology reports, and clinical notes.
Naturallanguageprocessing (NLP) is a core part of artificial intelligence. NaturalLanguageProcessing Succinctly Author : Joseph D. You’ll find all you need to know to build NLP solutions, starting with an overview of naturallanguageprocesses and what the technology can do.
Utilizing advanced naturallanguageprocessing (NLP) techniques, large language models (LLMs), and a cloud-based architecture, the resulting system demonstrates high accuracy and reliability. The post Using Generative AI for DataExtraction Clinical Support appeared first on John Snow Labs.
The model particularly focuses on ensuring the accurate extraction of crucial components like formulas, tables, and images, helping researchers acquire required data. MinerU’s architecture relies on naturallanguageprocessing (NLP) and machine learning (ML) techniques to extract and organize data effectively.
Learn NLP dataprocessing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk Many data we analyze as data scientists consist of a corpus of human-readable text.
These tools harness the power of machine learning, naturallanguageprocessing, and intelligent automation to simplify the creation, storage, and retrieval of critical business documents. Intelligent DataExtraction: Utilizes AI and machine learning to automatically recognize and extractdata from documents.
With Amazon Bedrock Data Automation, this entire process is now simplified into a single unified API call. It also offers flexibility in dataextraction by supporting both explicit and implicit extractions. Additionally, human-in-the-loop verification may be required for low-threshold outputs.
Companies can use high-quality human-powered data annotation services to enhance ML and AI implementations. In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. You can start training a new model once enough training data is available.
Please see the data provided below, which will be used for the purpose of this blog. It can analyze the text-based input provided by the user, interpret the query, and generate a response based on the content of the tabular data. Instead, we can use ChatGPT to generate SQL statements for a database that contains the data.
DataExtraction This project explores how data from Reddit, a widely used platform for discussions and content sharing, can be utilized to analyze global sentiment trends.
Photo by Sneaky Elbow on Unsplash The advent of large language models (LLMs), such as OpenAI’s GPT-3, has ushered in a new era of possibilities in the realm of naturallanguageprocessing. One such use case is the capacity to search for pertinent data effectively.
DataExtraction & Analysis : Summarizing large reports or extracting key insights from datasets using GPT-4’s advanced reasoning abilities. Cohere Cohere specializes in naturallanguageprocessing (NLP) and provides scalable solutions for enterprises, enabling secure and private data handling.
Introduction Deep Learning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. These models mimic the human brain’s neural networks, making them highly effective for image recognition, naturallanguageprocessing, and predictive analytics.
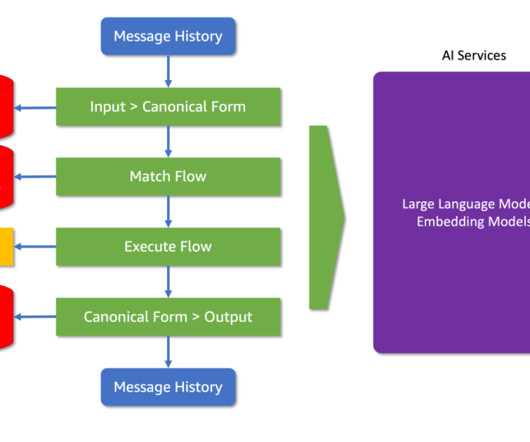
As large language models (LLMs) become increasingly integrated into customer-facing applications, organizations are exploring ways to leverage their naturallanguageprocessing capabilities. serves as a placeholder in Colang, signaling where dataextraction or inference is to be performed. The ellipsis (.
Medical dataextraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical naturallanguageprocessing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP.
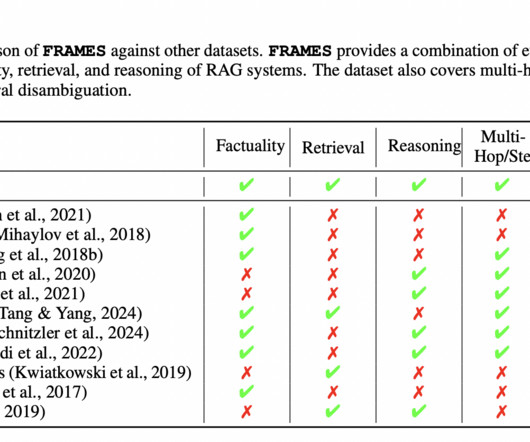
Retrieval-augmented generation (RAG) has been a transformative approach in naturallanguageprocessing, combining retrieval mechanisms with generative models to enhance factual accuracy and reasoning capabilities. The state-of-the-art model achieved 0.40 accuracy in a single-step evaluation scenario, improving to 0.45
In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes dataextraction, management, and governance. The solution integrates data in three tiers. Then we move to the next stage of accessing the actual dataextracted from the raw unstructured data.
Clone Researchers have developed various benchmarks to evaluate naturallanguageprocessing (NLP) tasks involving structured data, such as Table NaturalLanguage Inference (NLI) and Tabular Question Answering (QA). The Locating scenario involves questions about the optimal placement of resources (e.g.,
secondCarAds/dataset at main · cozypet/secondCarAds Understanding Language Studio’s Key Information Extraction Let’s begin by demystifying the world of naturallanguageprocessing. Azure Cognitive Service Language Studio offers powerful capabilities in entity recognition and key phrase extraction.
These development platforms support collaboration between data science and engineering teams, which decreases costs by reducing redundant efforts and automating routine tasks, such as data duplication or extraction. It does this by identifying named entities, parsing terms and conditions, and more.
While the GPT-4 series laid the foundation with its generalized language understanding and generation capabilities, o1 models were designed with improvements in context handling, resource efficiency, and task flexibility.
The impact of these challenges on the underwriting process is significant. Manual dataextraction and analysis can slow down the workflow, leading to longer processing times and lower customer retention. This can be time-consuming and may lack the necessary clarity and objectivity.
In this presentation, we delve into the effective utilization of NaturalLanguageProcessing (NLP) agents in the context of Acciona. We explore a range of practical use cases where NLP has been deployed to enhance various processes and interactions.
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. Dataextraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data.
While domain experts possess the knowledge to interpret these texts accurately, the computational aspects of processing large corpora require expertise in machine learning and naturallanguageprocessing (NLP).
Booke AI Booke AI is an AI-powered automation tool designed to streamline accounting processes for busy professionals. Features include real-time OCR dataextraction from invoices, bills, and receipts, automatic transaction categorization, and AI-assisted reconciliation.
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and dataextraction, among other skills. This 10-hour course, also highly rated at 4.8,
Claude Memory captures every conversation with the user, extracting important information such as facts, preferences, and key points, and then indexing and storing this data for future retrieval. This is done using naturallanguageprocessing techniques like named entity recognition, sentiment analysis, and topic modeling.
An IDP pipeline usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. Define and track key metrics related to document accuracy, processing times, and model efficacy.
Even if the document type is specified externally, it is advantageous to check the document type with the automatic classifier to avoid errors due to the input data. Named Entities in Clinical Data Abstraction based on NLP One of the most important tasks in NLP is named-entity recognition.
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of BeautifulSoup} Image by Author Behold the wondrous marvel known as BeautifulSoup, a mighty Python library renowned for its prowess in the realms of web scraping and dataextraction from HTML and XML documents.
Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents. You can apply human-in-the-loop to all types of deep learning AI projects, including naturallanguageprocessing (NLP), computer vision, and transcription.
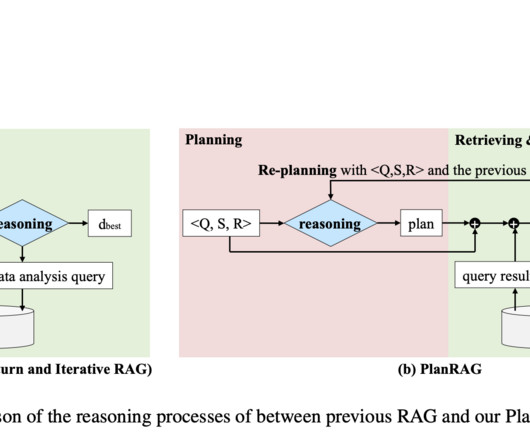
Retrieval Augmented Generation (RAG) models have emerged as a promising approach to enhance the capabilities of language models by incorporating external knowledge from large text corpora. Naive RAG models face limitations such as missing content, reasoning mismatch, and challenges in handling multimodal data.
Grammarly Grammarly makes use of naturallanguageprocessing techniques to provide support on every platform or browser page that you are visiting. AnyPicker AnyPicker is the ideal tool for scraping data from a webpage since it was designed for dataextraction from websites.
This growing prevalence underscores the need for advanced tools to analyze and interpret the vast amounts of clinical data generated in oncology. Furthermore, the introduction of zero-shot NER capabilities empowers users to identify and classify new entities with minimal effort, making the library adaptable to emerging research needs.
By using the advanced naturallanguageprocessing (NLP) capabilities of Anthropic Claude 3 Haiku, our intelligent document processing (IDP) solution can extract valuable data directly from images, eliminating the need for complex postprocessing.
Now, AI has evolved to understand and process complex document structures, making it an indispensable tool in modern business environments. In the past, Optical Character Recognition (OCR) and NaturalLanguageProcessing (NLP) were the main technologies used for document automation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










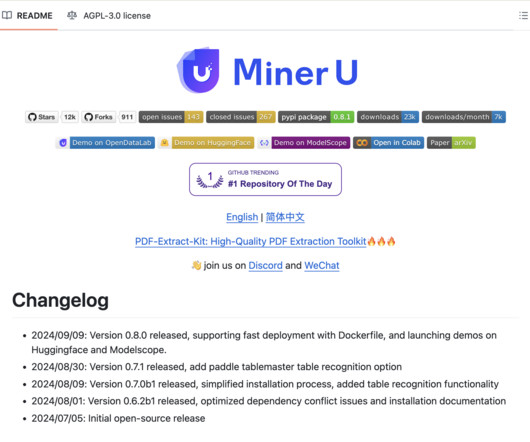






















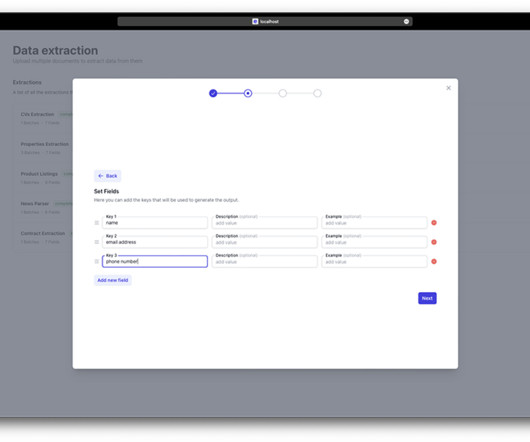






Let's personalize your content