This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With Amazon Bedrock Data Automation, this entire process is now simplified into a single unified API call. It also offers flexibility in dataextraction by supporting both explicit and implicit extractions. Additionally, human-in-the-loop verification may be required for low-threshold outputs.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly.
Companies can use high-quality human-powered data annotation services to enhance ML and AI implementations. In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. You can start training a new model once enough training data is available.
Retrieval Augmented Generation (RAG) models have emerged as a promising approach to enhance the capabilities of language models by incorporating external knowledge from large text corpora. Naive RAG models face limitations such as missing content, reasoning mismatch, and challenges in handling multimodal data.
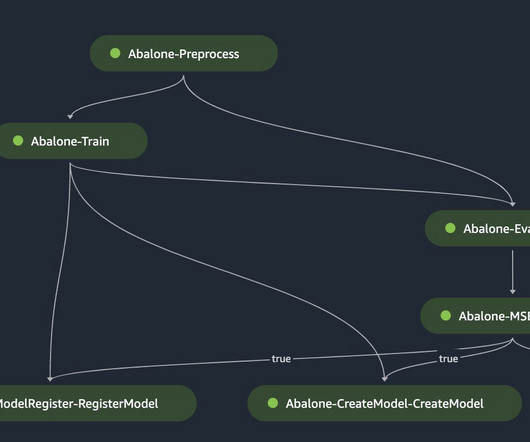
We use a typical pipeline flow, which includes steps such as dataextraction, training, evaluation, model registration and deployment, as a reference to demonstrate the advantages of Selective Execution. SageMaker Pipelines allows you to define runtime parameters for your pipeline run using pipeline parameters.
OCR The first step of document processing is usually a conversion of scanned PDFs to text information. The documentation can also include DICOM or other medical images, where both metadata and text information shown on the image needs to be converted to plain text.
In machine learning, experiment tracking stores all experiment metadata in a single location (database or a repository). Model hyperparameters, performance measurements, run logs, model artifacts, data artifacts, etc., Neptune AI ML model-building metadata may be managed and recorded using the Neptune platform.
Whether you’re looking to classify documents, extract keywords, detect and redact personally identifiable information (PIIs), or parse semantic relationships, you can start ideating your use case and use LLMs for your naturallanguageprocessing (NLP).
There is no doubt this powerful AI model becoming so popular and has opened up new possibilities for naturallanguageprocessing applications, enabling developers to create more sophisticated, human-like interactions in chatbots, question-answering systems, summarization tools, and beyond.
By taking advantage of advanced naturallanguageprocessing (NLP) capabilities and data analysis techniques, you can streamline common tasks like these in the financial industry: Automating dataextraction – The manual dataextractionprocess to analyze financial statements can be time-consuming and prone to human errors.
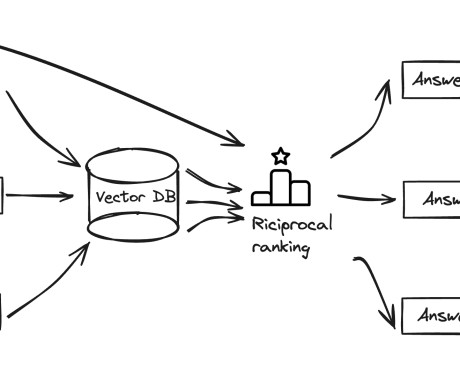
Amazon Kendra: Amazon Kendra provides semantic search capabilities for ranking of documents and passages, it also deals with the overhead of handling text extraction, embeddings, and managing vector datastore. Amazon Bedrock: This component is critical for processing and inference.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content