This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
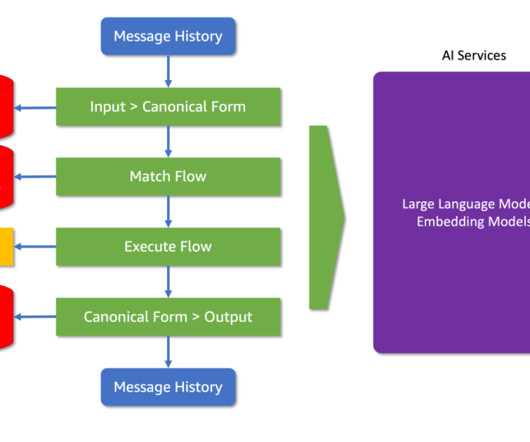
In this blog post, we explore a real-world scenario where a fictional retail store, AnyCompany Pet Supplies, leverages LLMs to enhance their customer experience. We will provide a brief introduction to guardrails and the Nemo Guardrails framework for managing LLM interactions. What is Nemo Guardrails? The ellipsis (.
The benefits of using Amazon Bedrock Data Automation Amazon Bedrock Data Automation provides a single, unified API that automates the processing of unstructured multi-modal content, minimizing the complexity of orchestrating multiple models, fine-tuning prompts, and stitching outputs together.
It provides a broad set of capabilities needed to build generative AI applications with security, privacy, and responsibleAI. Sonnet large language model (LLM) on Amazon Bedrock. For naturalization applications, LLMs offer key advantages. Screen showing documents have been uploaded.
The platform revolutionizes the quoting process for businesses by utilizing advanced AI technologies to automate what has traditionally been a labor-intensive and error-prone task. This automation begins with DataExtraction, employing OCR and AI to efficiently process customer emails and extract relevant information.
In this blog, we explore how Bright Data’s tools can enhance your data collection process and what the future holds for web data in the context of AI. With options for customizable and real-time data access, their solutions adapt to evolving data requirements.
In this blog post, we will explore ten valuable datasets that can assist you in fine-tuning or training your LLM. Fine-tuning a pre-trained LLM allows you to customize the model’s behavior and adapt it to your specific requirements. Each dataset offers unique features and can enhance your model’s performance. Why Fine-Tune a Model?
These organizations and others will be showcasing their latest products and services that can help you implement AI in your organization or improve your processes that are already in progress. Learn more about the AI Insight Talks below.
The solution uses Amazon Bedrock , a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, providing a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
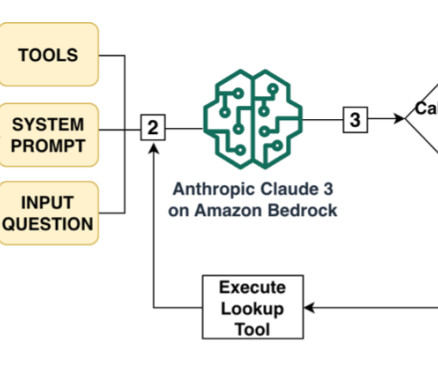
Amazon Bedrock Agents can be used to configure specialized agents that run actions seamlessly based on user input and your organizations data. These managed agents play conductor, orchestrating interactions between FMs, API integrations, user conversations, and knowledge bases loaded with your data.
Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation across diverse domains as showcased in numerous leaderboards (e.g., HELM , Hugging Face Open LLM leaderboard ) that evaluate them on a myriad of generic tasks. A three-shot prompting strategy is used for this task.
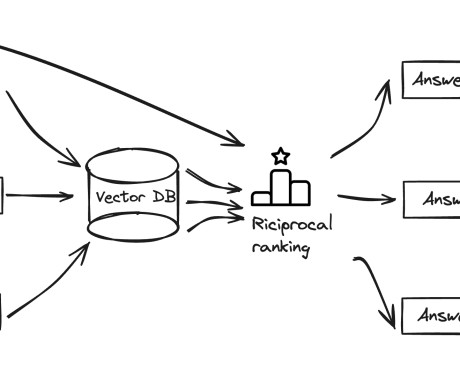
Additionally, we discuss the design from security and responsibleAI perspectives, demonstrating how you can apply this solution to a wider range of industry scenarios. Vector embedding and data cataloging To support natural language query similarity matching, the respective data is vectorized and stored as vector embeddings.
MSD collaborated with AWS Generative Innovation Center (GenAIIC) to implement a powerful text-to-SQL generative AI solution that streamlines dataextraction from complex healthcare databases. MSD employs numerous analysts and data scientists who analyze databases for valuable insights.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content