This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
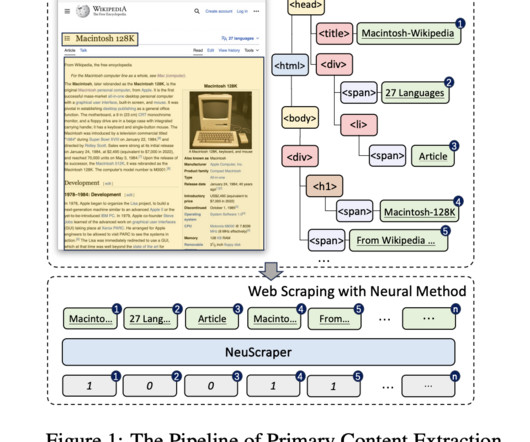
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
The quest for clean, usable data for pretraining LargeLanguageModels (LLMs) resembles searching for treasure amidst chaos. While rich with information, the digital realm is cluttered with extraneous content that complicates the extraction of valuable data.
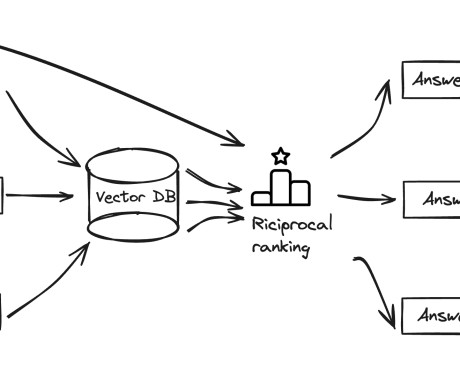
A deep dive — dataextraction, initializing the model, splitting the data, embeddings, vector databases, modeling, and inference Photo by Simone Hutsch on Unsplash We are seeing a lot of use cases for langchain apps and largelanguagemodels these days.
Clone Researchers have developed various benchmarks to evaluate natural language processing (NLP) tasks involving structured data, such as Table Natural Language Inference (NLI) and Tabular Question Answering (QA). The Locating scenario involves questions about the optimal placement of resources (e.g.,
Medical dataextraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP.
Prompt engineering is the art and science of crafting inputs (or “prompts”) to effectively guide and interact with generative AI models, particularly largelanguagemodels (LLMs) like ChatGPT. teaches students to automate document handling and dataextraction, among other skills.
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. This growing prevalence underscores the need for advanced tools to analyze and interpret the vast amounts of clinical data generated in oncology.
AI has witnessed rapid advancements in NLP in recent years, yet many existing models still struggle to balance intuitive responses with deep, structured reasoning. While proficient in conversational fluency, traditional AI chat models often fail to meet when faced with complex logical queries requiring step-by-step analysis.
In this evolving market, companies now have more options than ever for integrating largelanguagemodels into their infrastructure. DataExtraction & Analysis : Summarizing large reports or extracting key insights from datasets using GPT-4’s advanced reasoning abilities.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of LargeLanguageModels (LLMs) – the driving force behind NLP’s remarkable progress. What are LargeLanguageModels (LLMs)?
Largelanguagemodels have taken the world by storm, offering impressive capabilities in natural language processing. However, while these models are powerful, they can often benefit from fine-tuning or additional training to optimize performance for specific tasks or domains.
This enables companies to serve more clients, direct employees to higher-value tasks, speed up processes, lower expenses, enhance data accuracy, and increase efficiency. At the same time, the solution must provide data security, such as PII and SOC compliance. Data summarization using largelanguagemodels (LLMs).
In this presentation, we delve into the effective utilization of Natural Language Processing (NLP) agents in the context of Acciona. We explore a range of practical use cases where NLP has been deployed to enhance various processes and interactions.
While domain experts possess the knowledge to interpret these texts accurately, the computational aspects of processing large corpora require expertise in machine learning and natural language processing (NLP). Meta’s Llama 3.1, Alibaba’s Qwen 2.5
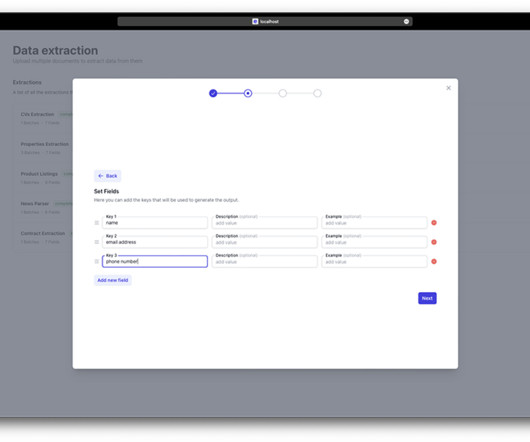
In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes dataextraction, management, and governance. The solution integrates data in three tiers. Then we move to the next stage of accessing the actual dataextracted from the raw unstructured data.
This blog explores the performance and comparison of de-identification services provided by Healthcare NLP, Amazon, and Azure, focusing on their accuracy when applied to a dataset annotated by healthcare experts. John Snow Labs has created custom largelanguagemodels ( LLMs ) tailored for diverse healthcare use cases.
Many techniques were created to process this unstructured data, such as sentiment analysis, keyword extraction, named entity recognition, parsing, etc. The evolution of LargeLanguageModels (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with.
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). 2020 ) and languagemodelling ( Khandelwal et al., In NLP, Gunel et al. 2020 ; Lewis et al., 2019 ; Pfeiffer et al.,
Through its proficient understanding of language and patterns, it can swiftly navigate and comprehend the data, extracting meaningful insights that might have remained hidden by the casual viewer. Imagine equipping generative AI with a dataset rich in information from various sources. All of this goes beyond mere computation.
Largelanguagemodels (LLMs) have unlocked new possibilities for extracting information from unstructured text data. Prompt engineering relies on large pretrained languagemodels that have been trained on massive amounts of text data. .*"
Additionally, we examine potential solutions to enhance the capabilities of largelanguagemodels (LLMs) and visual languagemodels (VLMs) with advanced LangChain capabilities, enabling them to generate more comprehensive, coherent, and accurate outputs while effectively handling multimodal data.
Apart from describing the contents of the dataset, during this presentation we will go through the process of its creation, which involved tasks such as dataextraction and preprocessing using different resources (Biopython, Spark NLP for Healthcare, and OpenCV, among others).
In the past, Optical Character Recognition (OCR) and Natural Language Processing (NLP) were the main technologies used for document automation. OCR converts images of text into machine-encoded text, while NLP helps the system understand and interpret human language. LLMs are like language wizards.
With Intelligent Document Processing (IDP) leveraging artificial intelligence (AI), the task of extractingdata from large amounts of documents with differing types and structures becomes efficient and accurate. Large pre-trained languagemodels exhibit state-of-the-art results on many NLP tasks due to stored factual knowledge.
Research And Discovery: Analyzing biomarker dataextracted from large volumes of clinical notes can uncover new correlations and insights, potentially leading to the identification of novel biomarkers or combinations with diagnostic or prognostic value.
This blog explores the performance and comparison of de-identification services provided by Healthcare NLP, Amazon, Azure, and OpenAI focusing on their accuracy when applied to a dataset annotated by healthcare experts. John Snow Labs has created custom largelanguagemodels ( LLMs ) tailored for diverse healthcare use cases.
The field of NLP, in particular, has experienced a significant transformation due to the emergence of LargeLanguageModels (LLMs). An interesting approach One algorithm of note focuses on topic classification by employing data compression algorithms. The initial release of ChatGPT, powered by GPT-3.5,
How does BloombergGPT, which was purpose-built for finance, differ in its training and design from generic largelanguagemodels ? What are the key advantages that it offers for financial NLP tasks? We had spent a lot of time thinking about how to centralize the management and improve our dataextraction and processing.
In-context learning is a prompt engineering approach where languagemodels learn tasks from a few natural language examples and try to perform them. ICL is a new approach in NLP with similar objectives to few-shot learning that lets models understand context without extensive tuning.
How does BloombergGPT, which was purpose-built for finance, differ in its training and design from generic largelanguagemodels ? What are the key advantages that it offers for financial NLP tasks? We had spent a lot of time thinking about how to centralize the management and improve our dataextraction and processing.
How does BloombergGPT, which was purpose-built for finance, differ in its training and design from generic largelanguagemodels ? What are the key advantages that it offers for financial NLP tasks? We had spent a lot of time thinking about how to centralize the management and improve our dataextraction and processing.
This AI Insight talk will showcase how VESSL AI enables enterprises to scale the deployment of over 100+ LargeLanguageModels (LLMs) starting at just $10, helping businesses save substantial cloud costs — up to $100K annually. Want to take a deeper dive into topics like LLMs, Generative AI, Machine Learning, NLP, and more?
It offers the capability to quickly identify relevant studies, extract key data, and even apply customizable inclusion and exclusion criteria—all within a seamless, interactive interface. ’ For each data point, you can provide a custom prompt to help the LLM better understand the specific concept that needs to be extracted. .”
We also discuss a qualitative study demonstrating how Layout improves generative artificial intelligence (AI) task accuracy for both abstractive and extractive tasks for document processing workloads involving largelanguagemodels (LLMs).
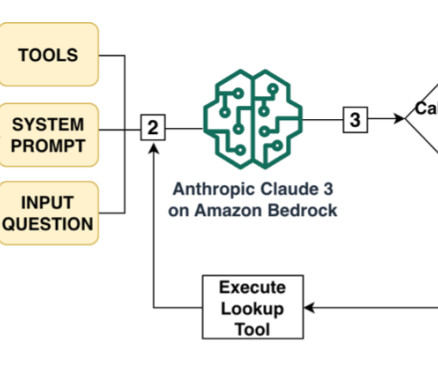
These languages might not be supported out of the box by existing document extraction software. Anthropic’s Claude models , deployed on Amazon Bedrock , can help overcome these language limitations. These largelanguagemodels (LLMs) are trained on a vast amount of data from various domains and languages.
Pathology, an aspect of diagnosis is undergoing significant changes, with the emergence of LargeLanguageModels (LLMs). A research published in “Nature Medicine” reported that an AI model achieved a 0.98 This progress signals the start of an era in healthcare known as precision pathology.
Agent Creator is a no-code visual tool that empowers business users and application developers to create sophisticated largelanguagemodel (LLM) powered applications and agents without programming expertise. He focuses on Deep learning including NLP and Computer Vision domains. The next paragraphs illustrate just a few.
The integrated approach and ease of use of Amazon Bedrock in deploying largelanguagemodels (LLMs), along with built-in features that facilitate seamless integration with other AWS services like Amazon Kendra, made it the preferred choice. By using Claude 3’s vision capabilities, we could upload image-rich PDF documents.
Traditional NLP pipelines and ML classification models Traditional natural language processing pipelines struggle with email complexity due to their reliance on rigid rules and poor handling of language variations, making them impractical for dynamic client communications.
Generative AI is transforming the way healthcare organizations interact with their data. MSD collaborated with AWS Generative Innovation Center (GenAIIC) to implement a powerful text-to-SQL generative AI solution that streamlines dataextraction from complex healthcare databases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content