This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
The quest for clean, usable data for pretraining LargeLanguageModels (LLMs) resembles searching for treasure amidst chaos. While rich with information, the digital realm is cluttered with extraneous content that complicates the extraction of valuable data.
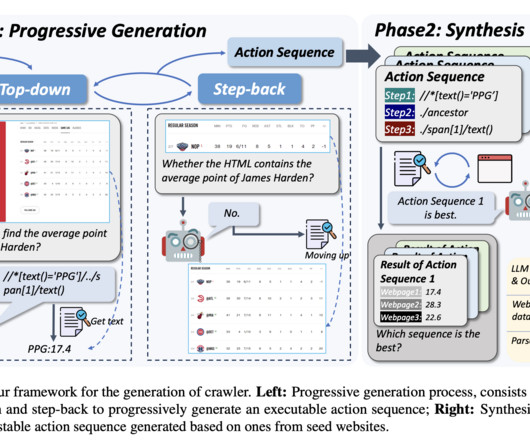
Firecrawl is a vital tool for data scientists because it addresses these issues head-on. This guarantees a complete dataextraction procedure by ensuring that no important data is lost. Firecrawl extractsdata and returns it in a clean, well-formatted Markdown.
Introduction The latest frontier in the evolution of LargeLanguageModels (LLMs) is the integration of multimodality, spearheaded initially by OpenAI’s GPT-4. However, Google has recently entered the arena with the launch of the Gemini Version of their model, unveiling its API to the public on December 13th.
A deep dive — dataextraction, initializing the model, splitting the data, embeddings, vector databases, modeling, and inference Photo by Simone Hutsch on Unsplash We are seeing a lot of use cases for langchain apps and largelanguagemodels these days.
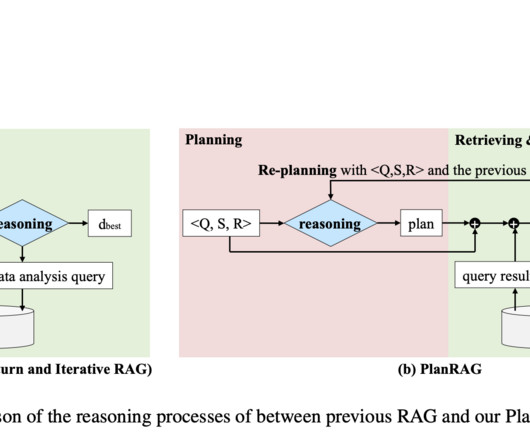
The benchmark is built using dataextracted from strategy video games that mimic real-world business situations. Don’t Forget to join our 45k+ ML SubReddit The post PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative LargeLanguageModels as Decision Makers appeared first on MarkTechPost.
Because traditional tools use a single chunk size for information retrieval, they frequently have trouble with different levels of data complexity. Most retrieval techniques concentrate on either precise data retrieval or semantic understanding.
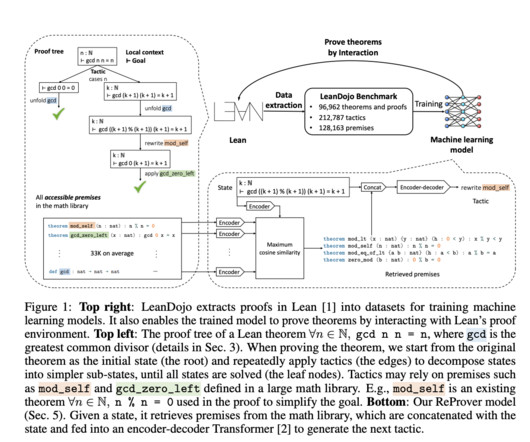
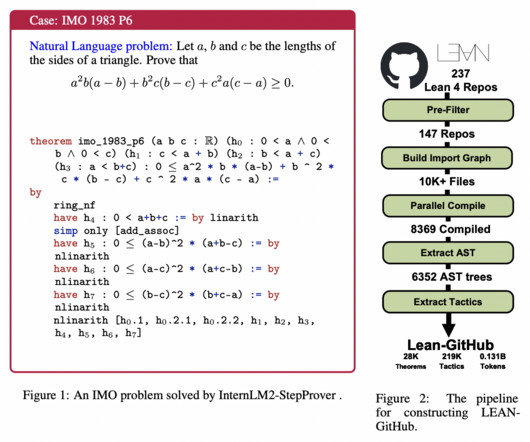
Largelanguagemodels (LLMs), which have demonstrated remarkable code generation capabilities, also face difficulties in theorem proving due to flaws in factuality and hallucination. It offers resources for working with Lean and extractingdata.
Collecting this data can be time-consuming and prone to errors, presenting a significant challenge in data-driven industries. Traditionally, web scraping tools have been utilized to automate the process of dataextraction. Unlike traditional tools, this innovative solution allows users to describe the needed data.
Utilizing advanced natural language processing (NLP) techniques, largelanguagemodels (LLMs), and a cloud-based architecture, the resulting system demonstrates high accuracy and reliability. The post Using Generative AI for DataExtraction Clinical Support appeared first on John Snow Labs.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Using Gen AI to enhance usability AI integration in RM and other modules AI functionality as a toolset What are some of the best practices to leverage AI and ML models in data management for large companies?
These advancements not only ensure near-instantaneous responses but also enable the model to handle complex instructions with precision and speed. In benchmark tests, Opus emerged as a frontrunner, outperforming GPT-4 in graduate-level reasoning and excelling in tasks involving maths, coding, and knowledge retrieval.
Prompt engineering is the art and science of crafting inputs (or “prompts”) to effectively guide and interact with generative AI models, particularly largelanguagemodels (LLMs) like ChatGPT. teaches students to automate document handling and dataextraction, among other skills.
Largelanguagemodels (LLMs) have demonstrated proficiency in solving complex problems across mathematics, scientific research, and software engineering. Chain-of-thought (CoT) prompting is pivotal in guiding models through intermediate reasoning steps before reaching conclusions.
Streaming Speech-to-Text : Streaming Speech-to-Text models convert live audio streams, like virtual meetings, into text at high accuracy and low latency. What’s new in Speech AI apps and tools?
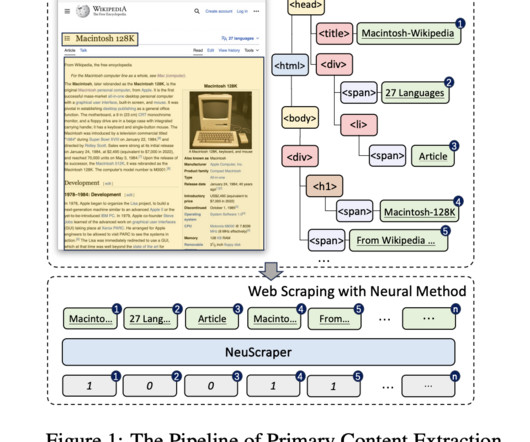
Unlike screen scraping, which simply captures the pixels displayed on a screen, web scraping captures the underlying HTML code along with the data stored in the corresponding database. This approach is among the most efficient and effective methods for dataextraction from websites.
With Amazon Bedrock Data Automation, this entire process is now simplified into a single unified API call. It also offers flexibility in dataextraction by supporting both explicit and implicit extractions. It also transcribes the audio into text and combines both visual and audio data for chapter level analysis.
While these tools are capable of collecting web data, they often do not format the output in a way that LLMs can easily process. Crawl4AI, an open-source tool, is designed to address the challenge of collecting and curating high-quality, relevant data for training largelanguagemodels.
Many of these tools depend on static rules or wrappers that cannot cope with the variability and unpredictability of modern web interfaces, leading to inefficiencies in web interaction and dataextraction.
In this evolving market, companies now have more options than ever for integrating largelanguagemodels into their infrastructure. DataExtraction & Analysis : Summarizing large reports or extracting key insights from datasets using GPT-4’s advanced reasoning abilities.
Largelanguagemodels have taken the world by storm, offering impressive capabilities in natural language processing. However, while these models are powerful, they can often benefit from fine-tuning or additional training to optimize performance for specific tasks or domains.
Prepare to be amazed as we delve into the world of LargeLanguageModels (LLMs) – the driving force behind NLP’s remarkable progress. In this comprehensive overview, we will explore the definition, significance, and real-world applications of these game-changing models. What are LargeLanguageModels (LLMs)?
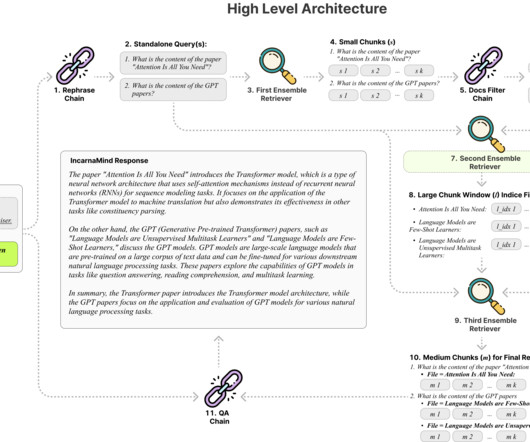
Photo by Sneaky Elbow on Unsplash The advent of largelanguagemodels (LLMs), such as OpenAI’s GPT-3, has ushered in a new era of possibilities in the realm of natural language processing. One such use case is the capacity to search for pertinent data effectively. However, this approach is not always ideal.
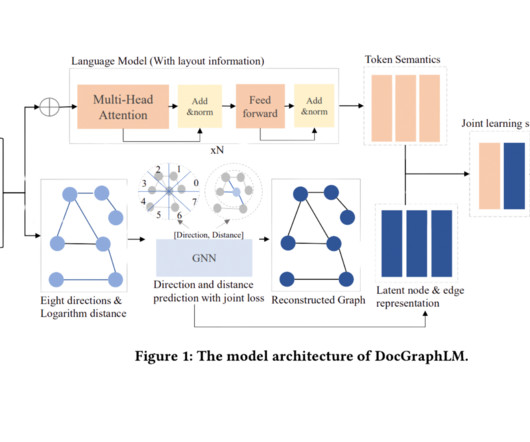
These documents, often in PDF or image formats, present a complex interplay of text, layout, and visual elements, necessitating innovative approaches for accurate information extraction. These methodologies have been instrumental in encoding text, layout, and image features to improve document interpretation. Check out the Paper.
LangChain Over the past few months, the AI world has been captivated by the incredible rise of LargeLanguageModels (LLMs). What is LargeLanguageModel ? So, in a simple ELI5 way, you can imagine you have a super-smart friend who knows everything about words and language.
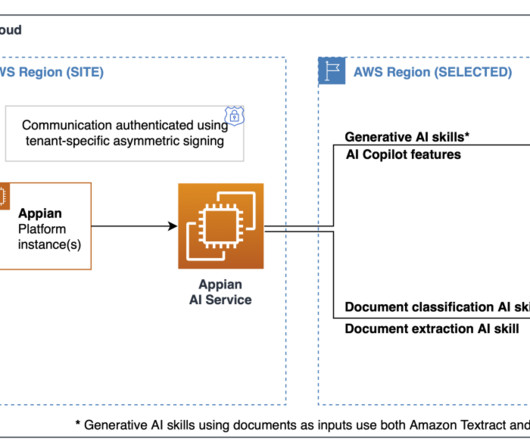
For customers, it translates to improved service quality, enhanced data protection, and a more dynamic, responsive service, ultimately driving better experiences and satisfaction. Appian has led the charge by offering generative AI skills powered by a collaboration with Amazon Bedrock and Anthropics Claude largelanguagemodels (LLMs).
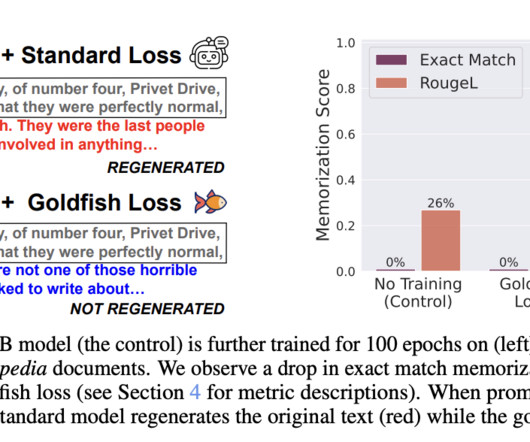
Extensive experiments with large Llama-2 models showed that goldfish loss significantly reduces memorization with minimal impact on performance. While goldfish-trained models may require slightly longer training times, they are resistant to verbatim reproduction and less susceptible to dataextraction attacks.
In our data-driven world, the ability to extract and process information efficiently is more valuable than ever. In this article, well explore innovative prompt engineering techniques that can elevate your interactions with LLMs, making your dataextraction tasks more efficient and insightful.
Enhancing the capabilities of IDP is the integration of generative AI, which harnesses largelanguagemodels (LLMs) and generative techniques to understand and generate human-like text. Solution overview The proposed solution uses Amazon Bedrock and the Amazon Titan Express model to enable IDP functionalities.
This unstructured data can impact the efficiency and productivity of clinical services, because it’s often found in various paper-based forms that can be difficult to manage and process. In this post, we explore using the Anthropic Claude 3 on Amazon Bedrock largelanguagemodel (LLM).
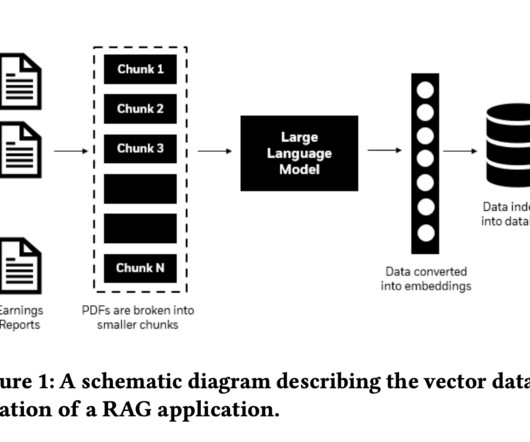
The ability to extract relevant insights from unstructured text, such as earnings call transcripts and financial reports, is essential for making informed decisions that can impact market predictions and investment strategies.
Largelanguagemodels (LLMs) show promise in solving high-school-level math problems using proof assistants, yet their performance still needs to improve due to data scarcity. Formal languages require significant expertise, resulting in limited corpora. Many learning-based systems (e.g.,
As largelanguagemodels (LLMs) become increasingly integrated into customer-facing applications, organizations are exploring ways to leverage their natural language processing capabilities. Integrating with Amazon SageMaker JumpStart to utilize the latest largelanguagemodels with managed solutions.
Further, the model has an improved function-calling feature that facilitates efficient processing of JSON-structured outputs. This feature makes it ideal for structured dataextraction applications, such as automated financial reporting, customer service automation, and real-time AI-based decision-making systems.
Users must create a new Conda environment, activate it, install RD-Agent, and configure their GPT model through a simple API key insertion. The system can be used with largelanguagemodels like GPT-4, making it highly adaptive for modern AI needs.
This growing prevalence underscores the need for advanced tools to analyze and interpret the vast amounts of clinical data generated in oncology. Relation extraction is used to connect biomarkers to their respective results, enabling a detailed understanding of the role biomarkers play in cancer diagnosis. setInputCol("text").setOutputCol("document")
Medical dataextraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). For instance, clinical texts might confuse ordinary NLP models since they are frequently filled with acronyms and specialized medical terminology.
This not only speeds up content production but also allows human writers to focus on more creative and strategic tasks. - **Data Analysis and Summarization**: These models can quickly analyze large volumes of data, extract relevant information, and summarize findings in a readable format.
Traditional rule-based systems, while precise, need help with the complexity and dynamism of modern business data. On the other hand, Artificial Intelligence (AI) models, particularly LargeLanguageModels (LLMs), excel in recognizing patterns and making predictions but may need more precision for specific business applications.
Sales intelligence platforms make it easier for sales organizations to automatically compile data, extract insights from that data, and drive efficiency in their operation. It might let them know where things went wrong (or right) and give them actionable advice on refining their approach next time.
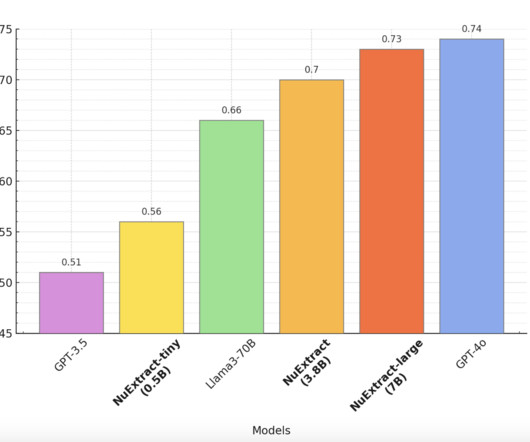
NuMind introduces NuExtract , a cutting-edge text-to-JSON languagemodel that represents a significant advancement in structured dataextraction from text. This model aims to transform unstructured text into structured data highly efficiently.
This enables companies to serve more clients, direct employees to higher-value tasks, speed up processes, lower expenses, enhance data accuracy, and increase efficiency. At the same time, the solution must provide data security, such as PII and SOC compliance. Data summarization using largelanguagemodels (LLMs).
Largelanguagemodels (LLMs) have shown remarkable advancements in reasoning capabilities in solving complex tasks. Second, it functions as a source for domain-specific seed dataextraction. First, it utilizes knowledge distillation and supervised finetuning to achieve steeper scaling trends than existing datasets.
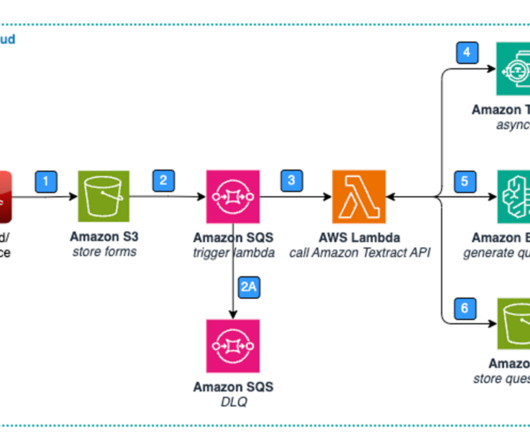
In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes dataextraction, management, and governance. The solution integrates data in three tiers. Then we move to the next stage of accessing the actual dataextracted from the raw unstructured data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content