This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, before data can be analyzed and converted into actionable insights, it must first be effectively sourced and extracted from a myriad of platforms, applications, and systems. This is where dataextraction tools come into play. What is DataExtraction? Why is DataExtraction Crucial for Businesses?
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
According to Bloomberg , the investigation stems from suspicious dataextraction activity detected in late 2024 via OpenAIs application programming interface (API), sparking broader concerns over international AI competition. A banner on its website informed users of a temporary sign-up restriction.
If the sales team isn’t communicating updated forecasts to procurement, they might secure long-term contracts based on outdated information, locking into agreements that may not align with current customer demand.
Announced last week, the update introduces a Responses API, an open-source Agents SDK, and built-in tools for web search, file search, and computer control all designed to streamline how AI systems interact with real-world information and applications.
Organizations face challenges when dealing with unstructured data from various sources like forms, invoices, and receipts. This data, often stored in different formats, is difficult to process and extract meaningful information from, especially at scale.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
When you're reading a research paper or article online, Paperguide can automatically detect all the important citation information: authors, publication dates, journal names, DOIs, etc. The AI is pretty clever about pulling this data even from tricky sources like PDFs or complex academic websites.
For complex tasks, AI agents can dramatically accelerate processing by summarizing long documents, allowing humans to review key information much faster. AI excels at ingesting large amounts of information and providing concise summaries, saving human reviewers significant time.
Pro, it retains the ability for multimodal reasoning across vast amounts of information and features the breakthrough long context window of one million tokens. The company has developed prototype agents that can process information faster, understand context better, and respond quickly in conversation. While lighter-weight than the 1.5
Healthcare documentation is an integral part of the sector that ensures the delivery of high-quality care and maintains the continuity of patient information. However, as healthcare providers have to deal with excessive amounts of data, managing it can feel overwhelming.
Akeneo is the product experience (PX) company and global leader in Product Information Management (PIM). How is AI transforming product information management (PIM) beyond just centralizing data? Akeneo is described as the “worlds first intelligent product cloud”what sets it apart from traditional PIM solutions?
In today’s digital landscape, data drives decision-making, innovation, and growth. With the vast amount of information available online, the ability to extract and analyze data efficiently has become crucial.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
Large language models (LLMs) have unlocked new possibilities for extractinginformation from unstructured text data. This post walks through examples of building informationextraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
During the evaluation process, researchers aimed to gauge Opus’s ability to pinpoint specific information within a vast dataset provided by users and recall it later. Astonishingly, Opus not only located the correct sentence but also expressed suspicion that it was being subjected to a test.
Sensitive customer data, intellectual property, and confidential business information remain entirely within your organizations control. or financial sector-specific regulations often require strict controls on how and where data is stored and processed. Regulatory environments like GDPR in Europe, HIPAA in the U.S.,
MultiOn AI has recently announced the release of its latest innovation, the Retrieve API, an autonomous web information retrieval API designed to revolutionize how developers and businesses extract and utilize web data. The development of the Retrieve API stemmed from feedback received after the launch of the Agent API.
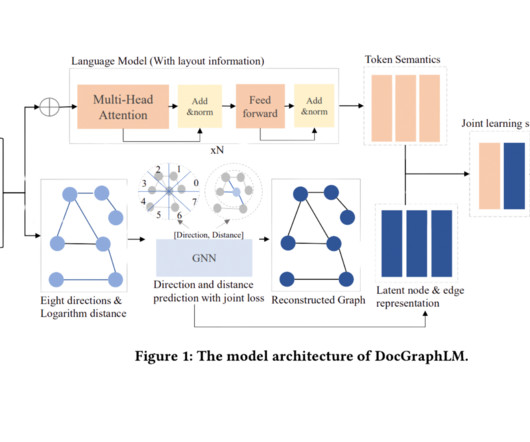
These documents, often in PDF or image formats, present a complex interplay of text, layout, and visual elements, necessitating innovative approaches for accurate informationextraction. The model consistently improved informationextraction and question-answering tasks when tested on standard datasets like FUNSD, CORD, and DocVQA.
In this article, we will explore the best AI document management solutions that are redefining the way organizations handle their digital assets, empowering you to make an informed decision when selecting the ideal platform for your organization's document management requirements.
Real-time customer data is integral in hyperpersonalization as AI uses this information to learn behaviors, predict user actions, and cater to their needs and preferences. This is also a critical differentiator between hyperpersonalization and personalization – the depth and timing of the data used.
Content creators like bloggers and social media managers can use HARPA AI to generate content ideas, optimize posts for SEO, and summarize information from various sources. Researchers can use HARPA AI for dataextraction and analysis for market research or competitive analysis to gather insights. Is HARPA AI worth it?
Extractinginformation quickly and efficiently from websites and digital documents is crucial for businesses, researchers, and developers. They require specific data from various online sources to analyze trends, monitor competitors, or gather insights for strategic decisions.
Perplexity promises its Perplexity Deep Research can deliver the information you need. In addition, this research framework provides a reference for fine-grained mining of other specific issues in social media data. techcrunch.com Applied use cases What is Perplexity Deep Research, and how do you use it? Let's find out.
Medical dataextraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). The clinical text’s sensitive patient information also raises concerns about privacy and regulatory compliance.
The explosion of content in text, voice, images, and videos necessitates advanced methods to parse and utilize this information effectively. Enter generative AI, a groundbreaking technology that transforms how we approach dataextraction. Generative AI models excel at extracting relevant features from vast amounts of text data.
Introduction In the ever-evolving landscape of data processing, extracting structured information from PDFs remains a formidable challenge, even in 2024. While numerous models excel at question-answering tasks, the real complexity lies in transforming unstructured PDF content into organized, actionable data.
Clinical reviewers frequently face the challenge of adapting to diverse data sources and formats. To address this issue, Evernorth has developed an innovative clinical support tool designed to facilitate rapid and efficient access to necessary information, irrespective of data structure or format.
Using robust infrastructure and advanced language models, these AI-driven tools enhance decision-making by providing valuable insights, improving operational efficiency by automating routine tasks, and helping with data privacy through built-in detection and management of sensitive information.
Introduction In the world of data analysis, extracting useful information from tabular data can be a difficult task. Conventional approaches typically require manual exploration and analysis of data, which can be requires a significant amount of effort, time, or workforce to complete.
Given the value of data today, organizations across various industries are working with vast amounts of data across multiple formats. Manually reviewing and processing this information can be a challenging and time-consuming task, with a margin for potential errors.
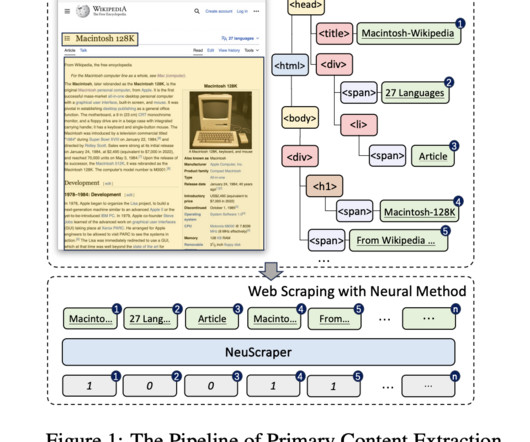
Unlike screen scraping, which simply captures the pixels displayed on a screen, web scraping captures the underlying HTML code along with the data stored in the corresponding database. This approach is among the most efficient and effective methods for dataextraction from websites.
With the growing need for automation in dataextraction, OCR tools have become an essential part of many applications, from digitizing documents to extractinginformation from scanned images. Optical Character Recognition (OCR) is a powerful technology that converts images of text into machine-readable content.
They have a propensity to generate misleading or completely false information, a phenomenon known as ‘hallucination’. Simplifying DataExtraction with LangChain Agents Retrieving data from a database is seldom a straightforward endeavor. The future of data interaction is here, and you’re a part of it.
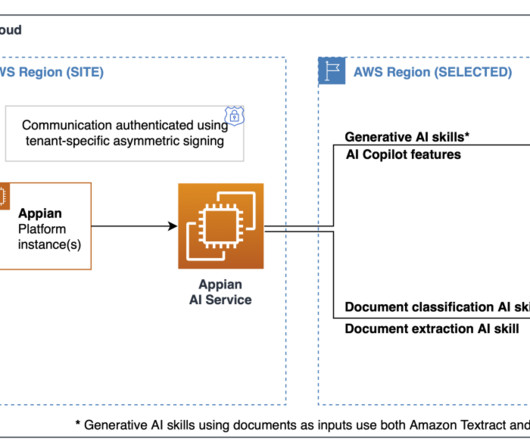
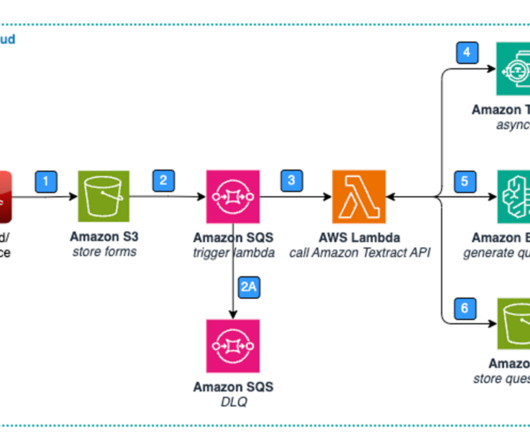
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Figure 1: Architecture – Standard Form – DataExtraction & Storage.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. In this stage, we store initial document information in an Amazon DynamoDB table after receiving an Amazon S3 event notification.
Through a practical use case of processing a patient health package at a doctors office, you will see how this technology can extract and synthesize information from all three document types, potentially improving data accuracy and operational efficiency. For more information, see Create a guardrail.
Automating the dataextraction process, especially from tables and figures, can allow researchers to focus on data analysis and interpretation rather than manual dataextraction. With quicker access to relevant data, researchers can accelerate the pace of their work and contribute to advancements in their fields.
For a retail chatbot like AnyCompany Pet Supplies AI assistant, guardrails help make sure that the AI collects the information needed to serve the customer, provides accurate product information, maintains a consistent brand voice, and integrates with the surrounding services supporting to perform actions on behalf of the user.
For more information about version updates, see Shut down and Update Studio Classic Apps. Each model card shows key information, including: Model name Provider name Task category (for example, Text Generation) Select the model card to view the model details page. Search for Meta to view the Meta model card.
The quest for clean, usable data for pretraining Large Language Models (LLMs) resembles searching for treasure amidst chaos. While rich with information, the digital realm is cluttered with extraneous content that complicates the extraction of valuable data.
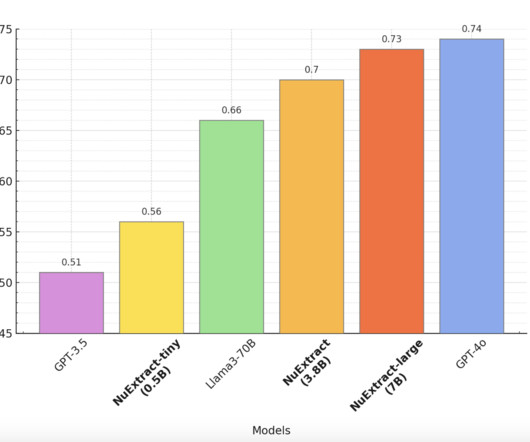
NuMind introduces NuExtract , a cutting-edge text-to-JSON language model that represents a significant advancement in structured dataextraction from text. This model aims to transform unstructured text into structured data highly efficiently.
The core feature of DeepHermes 3 is its ability to switch between intuitive and deep reasoning, allowing users to customize how the model processes and delivers information. Further, the model has an improved function-calling feature that facilitates efficient processing of JSON-structured outputs.
Firecrawl is a vital tool for data scientists because it addresses these issues head-on. This guarantees a complete dataextraction procedure by ensuring that no important data is lost. Firecrawl extractsdata and returns it in a clean, well-formatted Markdown.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content