This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There might be changes in the data distribution in production, thus causing […]. The post The Importance of DataDrift Detection that Data Scientists Do Not Know appeared first on Analytics Vidhya. But, once deployed in production, ML models become unreliable and obsolete and degrade with time.
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for data scientist to remain competitive in the market. You have to understand data, how to extract value from them and how to monitor model performances.
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. An example of how datadrift may occur is in the context of changing mobile usage patterns over time.
This is not ideal because data distribution is prone to change in the real world which results in degradation in the model’s predictive power, this is what you call datadrift. There is only one way to identify the datadrift, by continuously monitoring your models in production.
PythonData Science Tools and Libraries Scikit-learn Scikit-Learn is the most popular machine-learning library in the Python programming ecosystem. Skicit is a mature Python library and contains several algorithms for classification, regression, and clustering. E.g., NumPy arrays can be initiated by nested Python lists.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
Key Challenges in ML Model Monitoring in Production DataDrift and Concept DriftData and concept drift are two common types of drift that can occur in machine-learning models over time. Datadrift refers to a change in the input data distribution that the model receives.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
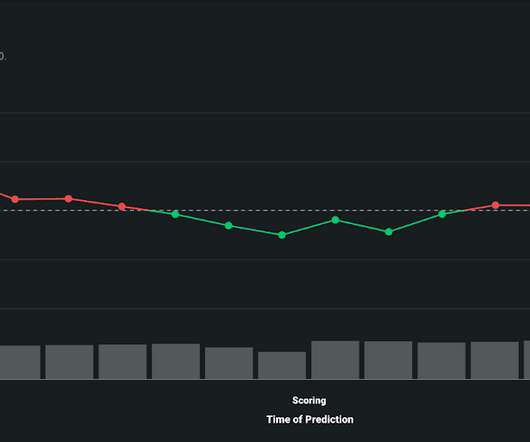
Model Observability provides an end-to-end picture of the internal states of a system, such as the system’s inputs, outputs, and environment, including datadrift, prediction performance, service health, and more relevant metrics. Visualize DataDrift Over Time to Maintain Model Integrity. Drift Over Time.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Monitoring Models in Production There are several types of problems that Machine Learning applications can encounter over time [4]: Datadrift: sudden changes in the features values or changes in data distribution. Model/concept drift: how, why, and when the performance of the model changes. 15, 2022. [4]
However, the data in the real world is constantly changing, and this can affect the accuracy of the model. This is known as datadrift, and it can lead to incorrect predictions and poor performance. In this blog post, we will discuss how to detect datadrift using the Python library TorchDrift.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., You can define expectations about data quality, track datadrift, and monitor changes in data distributions over time. and Pandas or Apache Spark DataFrames.
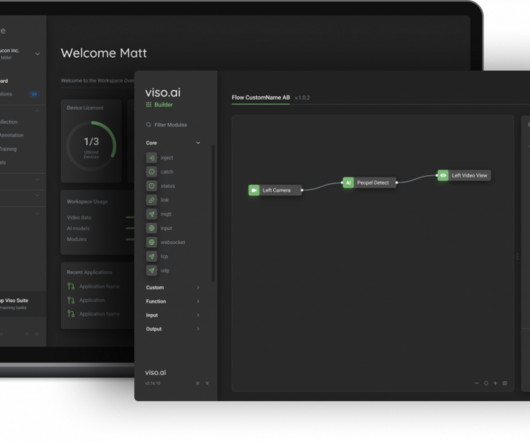
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
GitLab CI/CD serves as the macro-orchestrator, orchestrating model build and model deploy pipelines, which include sourcing, building, and provisioning Amazon SageMaker Pipelines and supporting resources using the SageMaker Python SDK and Terraform.
For our joint solution with Snowflake, this means that code-first users can use DataRobot’s hosted Notebooks as the interface and Snowpark processes the data directly in the data warehouse. The DataRobot MLOps dashboards present the model’s health, datadrift, and accuracy over time and can help determine model accountability.
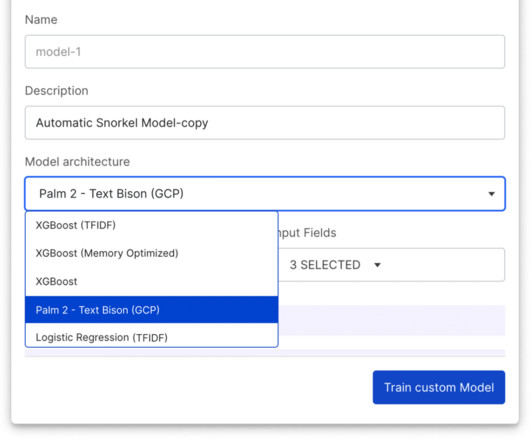
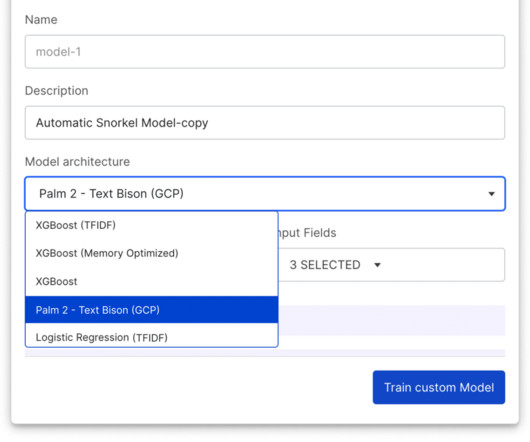
When Vertex Model Monitoring detects datadrift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
When Vertex Model Monitoring detects datadrift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
Describing the data As mentioned before, we will be using the data provided by Corporación Favorita in Kaggle. After deployment, we will monitor the model performance with the current best model and check for datadrift and model drift. Apart from that, we must constantly monitor the data as well.
For example, there is an example on how you can work with conda.yml and requirements.txt to enable security scans on the installed Python packages. We’ve even added support for dependable python package scans via pip install in a docker container. We have implemented Azure Data Explorer (ADX) as a platform to ingest and analyze data.
SageMaker has developed the distributed data parallel library , which splits data per node and optimizes the communication between the nodes. You can use the SageMaker Python SDK to trigger a job with data parallelism with minimal modifications to the training script. Each node has a copy of the DNN.
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
When Vertex Model Monitoring detects datadrift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
PyTerrier is a Python framework for performing information retrieval experiments, built on Terrier. NannyML is an open-source python library that allows you to estimate post-deployment model performance (without access to targets), detect datadrift, and intelligently link datadrift alerts back to changes in model performance.
For code-first users, we offer a code experience too, using the AP—both in Python and R—for your convenience. Check for model accuracy and datadrift and inspect each model from governance and service health perspectives, respectively. The process I will present will be using the DataRobot GUI. Setting up a Time Series Project.
AWS Glue consists of a metadata repository known as Glue catalog, an engine to generate the Scala or Python code for the ETL Job, and also does job monitoring, scheduling, and so on. Another type of data was images with specific event IDs getting dumped to an S3 location. For that, we used another pipeline based on AWS Glue.
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional data engineering and machine learning life cycles.
Viso Suite: the only end-to-end computer vision platform Lightweight Models for Face Recognition DeepFace – Lightweight Face Recognition Analyzing Facial Attribute DeepFace AI is Python’s lightweight face recognition and facial attribute library. Therefore, it can handle all procedures for facial recognition in the background.
Introduction Deepchecks is a groundbreaking open-source Python package that aims to simplify and enhance the process of implementing automated testing for machine learning (ML) models. From Research to Production.
Uber wrote about how they build a datadrift detection system. pyribs is a bare-bones Python library for quality diversity (QD) optimization. In our case that meant prioritizing stability, performance, and flexibility above all else. Don’t be afraid to use boring technology.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. You can learn more about Comet here.
JupyterLabs has been one of the most popular interactive tools for ML development with Python. This platform needs access to the Data Platform and needs to have support for all types of Data Connectors to fetch data from data sources. Consider the example of a Product Recommendation system in eCommerce.
You essentially divide things up into large tasks and chunks, but the software engineering that goes within that task is the thing that you’re generally gonna be updating and adding to over time as your machine learning grows within your company or you have new data sources, you want to create new models, right? To figure it out.
For this exercise, we are using a python operator to define the tasks, and we are going to keep DAG’s schedule as ‘None’ as we will be running the pipeline manually. These tasks will include loading iris dataset from scikit-learn dataset package, transforming the data, and using the refined dataframe to create a machine learning model.
Continuous Improvement: Data scientists face many issues after model deployment like performance degradation, datadrift, etc. By understanding what goes under the hood with Explainable AI, data teams are better equipped to improve and maintain model performance, and reliability.
The Data Profiler is a tool that we developed to help us start to get more insight into what’s happening in our data. It is essentially a Python library. It accepts data of a variety of different types, whether that’s Parquet files, or Opera, or CSV and text files, et cetera. You can pip install it.
The Data Profiler is a tool that we developed to help us start to get more insight into what’s happening in our data. It is essentially a Python library. It accepts data of a variety of different types, whether that’s Parquet files, or Opera, or CSV and text files, et cetera. You can pip install it.
Biased training data can lead to discriminatory outcomes, while datadrift can render models ineffective and labeling errors can lead to unreliable models. Morgan’s Athena uses Python-based open-source AI to innovate risk management.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Kedro Kedro is a Python library for building modular data science pipelines.
However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of data scientists and analysts. Most employees don’t master the conventional data science toolkit (SQL, Python, R etc.). Adaptability over time To use Text2SQL in a durable way, you need to adapt to datadrift, i.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content