This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning creates static models from historical data. But, once deployed in production, ML models become unreliable and obsolete and degrade with time. There might be changes in the data distribution in production, thus causing […].
Introduction Whether you’re a fresher or an experienced professional in the Data industry, did you know that ML models can experience up to a 20% performance drop in their first year? Monitoring these models is crucial, yet it poses challenges such as data changes, concept alterations, and data quality issues.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
These are instead some of the skills that I would strongly master: Theoretical foundation: A strong grasp of concepts like exploratory data analysis (EDA), data preprocessing, and training/finetuning/testing practices, ML models remains essential. Programming expertise: A medium/high proficiency in Python and SQL is enough.
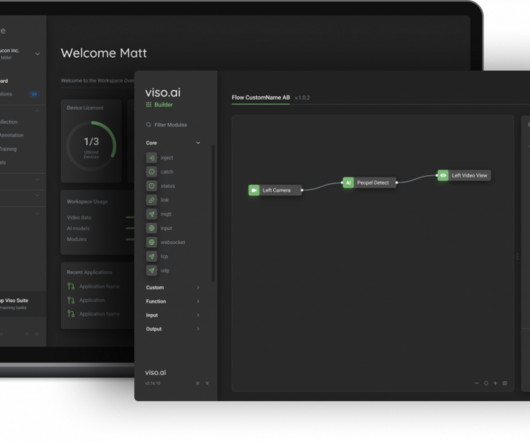
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. About us: Viso Suite provides enterprise ML teams with 695% ROI on their computer vision applications.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
It’s a common challenge faced in the production phase, and that is where Evidently.ai, a fantastic open-source tool, comes into play to make our ML model observable and easy to monitor. Introduction Have you experienced the frustration of a well-performing model in training and evaluation performing worse in the production environment?
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. Datadrift and model drift are also monitored.
Uber runs one of the most sophisticated data and machine learning(ML) infrastructures in the planet. Uber innvoations in ML and data span across all categories of the stack. Like any large tech company, data is the backbone of the Uber platform. Not surprisingly, data quality and drifting is incredibly important.
Learn how to develop an ML project from development to production. DataDrift Detection and Model Retraining Trigger – DataDrift Detection with… Read the full blog for free on Medium. Join thousands of data leaders on the AI newsletter.
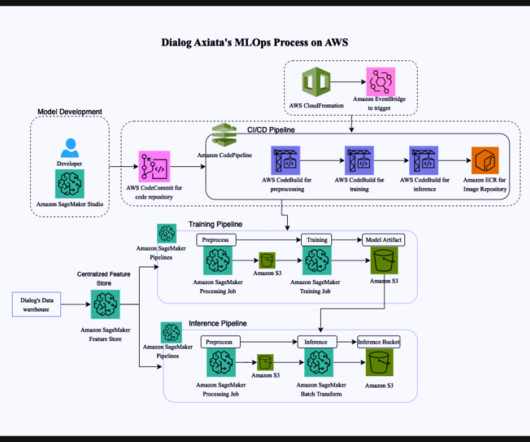
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition. 2 Ensuring and maintaining high-quality data.
This makes review cycles messier and more subjective than in traditional software or ML. The first property is something we saw with data and ML-powered software. What this meant was the emergence of a new stack for ML-powered app development, often referred to as MLOps. Evaluation is the engine, not the afterthought.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
Many tools and techniques are available for ML model monitoring in production, such as automated monitoring systems, dashboarding and visualization, and alerts and notifications. Datadrift refers to a change in the input data distribution that the model receives. The MLOps difference?
Introduction Deepchecks is a groundbreaking open-source Python package that aims to simplify and enhance the process of implementing automated testing for machine learning (ML) models. In this article, we will explore the various aspects of Deepchecks and how it can revolutionize the way we validate and maintain ML models.
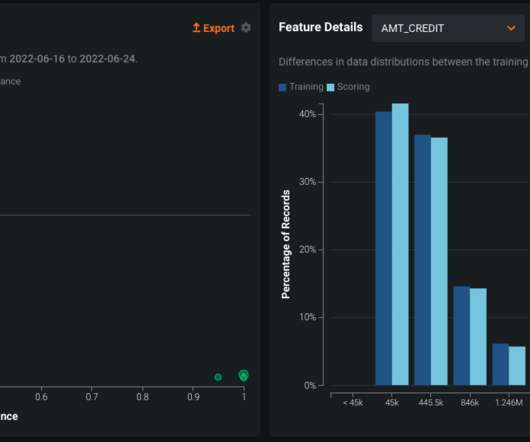
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
IDC 2 predicts that by 2024, 60% of enterprises would have operationalized their ML workflows by using MLOps. The same is true for your ML workflows – you need the ability to navigate change and make strong business decisions. Meanwhile, DataRobot can continuously train Challenger models based on more up-to-date data.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Leveraging DataRobot’s JDBC connectors, enterprise teams can work together to train ML models on their data residing in SAP HANA Cloud and SAP Data Warehouse Cloud, as well as have an option to enrich it with data from external data sources.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Adoption of AI/ML is maturing from experimentation to deployment. Model Observability provides an end-to-end picture of the internal states of a system, such as the system’s inputs, outputs, and environment, including datadrift, prediction performance, service health, and more relevant metrics. Model Observability Features.
The MLOps Process We can see some of the differences with MLOps which is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently. MLOps is the intersection of Machine Learning, DevOps, and Data Engineering.
From NLP, ML, and generative AI, to even artificial general intelligence, the topics were diverse and awe-inspiring. By combining the power of LLMs, auto-GPT, Langchain, and auto-ML, this innovative system enables dynamic and adaptable predictions. This includes datadrift, cold starts, sudden scaling, and competing priorities.
Once the best model is identified, it is usually deployed in production to make accurate predictions on real-world data (similar to the one on which the model was trained initially). Ideally, the responsibilities of the ML engineering team should be completed once the model is deployed. But this is only sometimes the case.
Auto DataDrift and Anomaly Detection Photo by Pixabay This article is written by Alparslan Mesri and Eren Kızılırmak. Model performance may change over time due to datadrift and anomalies in upcoming data. This can be prevented using Google’s Tensorflow Data Validation library.
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
Data science teams currently struggle with managing multiple experiments and models and need an efficient way to store, retrieve, and utilize details like model versions, hyperparameters, and performance metrics. ML model versioning: where are we at? The short answer is we are in the middle of a data revolution.
That’s the datadrift problem, aka the performance drift problem. There’s the risk that there’s some bad data that’s injected into your training process that’s going to break your model. The second challenge is evaluation. Every time you retrain a model it introduces risk.
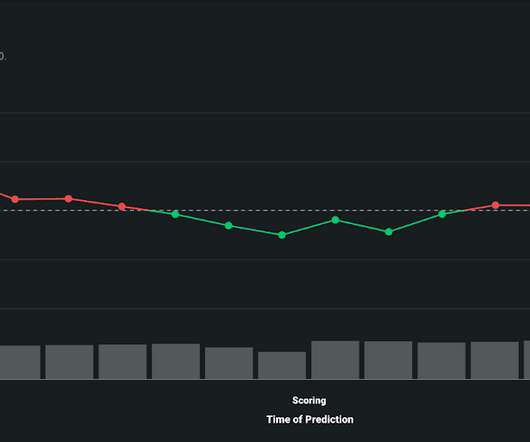
Monitoring Modern Machine Learning (ML) Methods In Production. Given the numerous variables that may change, how does the financial institution develop a robust monitoring strategy, and apply them in the context of ML models? In the image below, we see two charts depicting the amount of drift that has occurred for a deployed model.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machine learning models, and locked ROI. Exploratory Data Analysis After we connect to Snowflake, we can start our ML experiment. launch event on March 16th.
The DataRobot AI platform allows users with different skill sets across data analytics, data science, lines of business, and IT to experiment at scale and automate the mundane, management tasks of updating, while allowing teams to focus on their core expertise. Get Started with DataRobot Dedicated Managed AI Cloud on Google Cloud.
Identification of relevant representation data from a huge volume of data – This is essential to reduce biases in the datasets so that common scenarios (driving at normal speed with obstruction) don’t create class imbalance. To yield better accuracy, DNNs require large volumes of diverse, good quality data.
Enhanced user experience in Snorkel Flow Studio We’ve made significant improvements to Snorkel Flow Studio, making it easier for you to export training datasets in the UI, improving default display settings, adding per-class filtering and analysis, and several other great enhancements for easier integration with larger ML pipelines.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
The article is based on a case study that will enable readers to understand the different aspects of the ML monitoring phase and likewise perform actions that can make ML model performance monitoring consistent throughout the deployment. So let’s get into it. Other features include sales numbers and supplementary information.
Enhanced user experience in Snorkel Flow Studio We’ve made significant improvements to Snorkel Flow Studio, making it easier for you to export training datasets in the UI, improving default display settings, adding per-class filtering and analysis, and several other great enhancements for easier integration with larger ML pipelines.
In the first part of the “Ever-growing Importance of MLOps” blog, we covered influential trends in IT and infrastructure, and some key developments in ML Lifecycle Automation. DataRobot’s Robust ML Offering. This capability is a vital addition to the AI and ML enterprise workflow.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content