This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon What is Model Monitoring and why is it required? Machinelearning creates static models from historical data. There might be changes in the data distribution in production, thus causing […].
If we say an end-to-end machinelearning project doesn't stop when it is developed, it's only halfway. A machineLearning project succeeds if the model is in production and creates continuous value for the business. However, creating an end-to-end machinelearning project has now become a necessity.
What makes AI governance different from data governance? As the world turns and datadrifts, AI systems can deviate from their intended design, magnifying ethical concerns like fairness and bias. AI governance focuses on outputs–the decisions, predictions, and autonomous content created by AI systems.
Download the MachineLearning Project Checklist. Planning MachineLearning Projects. Machinelearning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. More organizations are investing in machinelearning than ever before.
Source: Author Introduction Machinelearning model monitoring tracks the performance and behavior of a machinelearning model over time. Organizations can ensure that their machine-learning models remain robust and trustworthy over time by implementing effective model monitoring practices.
They mitigate issues like overfitting and enhance the transferability of insights to unseen data, ultimately producing results that align closely with user expectations. This emphasis on data quality has profound implications. Data validation frameworks play a crucial role in maintaining dataset integrity over time.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machinelearning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machinelearning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
Human element: Data scientists are vulnerable to perpetuating their own biases into models. Machinelearning : Even if scientists were to create purely objective AI, models are still highly susceptible to bias. One way to identify bias is to audit the data used to train the model.
Post-deployment monitoring and maintenance: Managing deployed models includes monitoring for datadrift, model performance issues, and operational errors, as well as performing A/B testing on your different models. Project management skills in understanding how quickly to iterate on data projects, from an MVP to a Final product.
tweaktown.com Research Researchers unveil time series deep learning technique for optimal performance in AI models A team of researchers has unveiled a time series machinelearning technique designed to address datadrift challenges. techxplore.com Are deepfakes illegal?
MachineLearning Operations (MLOps) is a set of practices and principles that aim to unify the processes of developing, deploying, and maintaining machinelearning models in production environments. Types of MLOps Tools MLOps tools play a pivotal role in every stage of the machinelearning lifecycle.
Model drift is an umbrella term encompassing a spectrum of changes that impact machinelearning model performance. Two of the most important concepts underlying this area of study are concept drift vs datadrift. Source ) The impact of concept drift on model performance is potentially significant.
Uber runs one of the most sophisticated data and machinelearning(ML) infrastructures in the planet. Uber innvoations in ML and data span across all categories of the stack. Like any large tech company, data is the backbone of the Uber platform. Not surprisingly, data quality and drifting is incredibly important.
I wasn’t surprised by these responses as they are commonly cited, and also of course because the data challenge is our organization’s reason for being. When it comes to data challenges, LXT can both source data and label it so that machinelearning algorithms can make sense of it.
Biased training data can lead to discriminatory outcomes, while datadrift can render models ineffective and labeling errors can lead to unreliable models. TensorFlow is a flexible, extensible learning framework that supports programming languages like Python and Javascript.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machinelearning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems. Scaling is one of the biggest issues in the machinelearning cycle.
MachineLearning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Ensuring Long-Term Performance and Adaptability of Deployed Models Source: [link] Introduction When working on any machinelearning problem, data scientists and machinelearning engineers usually spend a lot of time on data gathering , efficient data preprocessing , and modeling to build the best model for the use case.
It should be clear when datadrift is happening and if the model needs to be retrained. DataRobot offers three primary explainability features in MLOps: Service Health , DataDrift , and Accuracy. DataDrift. This is called datadrift and can cause the deployment to become inaccurate.
We sat down for an interview at the annual 2023 Upper Bound conference on AI that is held in Edmonton, AB and hosted by Ammi (Alberta Machine Intelligence Institute). Your primary focus has being on reinforcement learning, what draws you to this type of machinelearning ? What's the machinelearning studying?
legal document review) It excels in tasks that require specialised terminologies or brand-specific responses but needs a lot of computational resources and may become obsolete with new data.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Statistical methods and machinelearning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon MachineLearning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Today, SAP and DataRobot announced a joint partnership to enable customers connect core SAP software, containing mission-critical business data, with the advanced MachineLearning capabilities of DataRobot to make more intelligent business predictions with advanced analytics.
The MLOps Process We can see some of the differences with MLOps which is a set of methods and techniques to deploy and maintain machinelearning (ML) models in production reliably and efficiently. MLOps is the intersection of MachineLearning, DevOps, and Data Engineering. References [1] E. Russell and P.
The Problems in Production Data & AI Model Output Building robust AI systems requires a thorough understanding of the potential issues in production data (real-world data) and model outcomes. Model Drift: The model’s predictive capabilities and efficiency decrease over time due to changing real-world environments.
Knowing this, we walked through a demo of DataRobot AI Cloud MLOps solution , which can manage the open-source models developed by the retailer and regularly provide metrics such as service health, datadrift and changes in accuracy. Monitoring with MachineLearning.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift.
Do you need help to move your organization’s MachineLearning (ML) journey from pilot to production? Challenges Customers may face several challenges when implementing machinelearning (ML) solutions. Ensuring data quality, governance, and security may slow down or stall ML projects. You’re not alone.
Learn to monitor your mo in production Photo by Alexander Sinn on Unsplash Introduction Machinelearning models are designed to make predictions based on data. However, the data in the real world is constantly changing, and this can affect the accuracy of the model. Table of Contents What is DataDrift?
Building out a machinelearning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machinelearning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
During machinelearning model training, there are seven common errors that engineers and data scientists typically run into. It enables enterprises to create and implement computer vision solutions , featuring built-in ML tools for data collection, annotation, and model training.
The Stuff They Didn’t Tell You in Data Science Class: Tips and Tricks for Every Level of Practical Data Science | Slides Here In this session, attendees were reminded about the gap between applying data science and studying data science. This includes datadrift, cold starts, sudden scaling, and competing priorities.
To address the large value challenge, you can utilize the Amazon SageMaker distributed data parallelism feature (SMDDP). SageMaker is a fully managed machinelearning (ML) service. With data parallelism, a large volume of data is split into batches. This reduces the development velocity and ability to fail fast.
That’s the datadrift problem, aka the performance drift problem. Previously, Josh worked as a deep learning & robotics researcher at OpenAI and as a management consultant at McKinsey. Josh did his PhD in Computer Science at UC Berkeley advised by Pieter Abbeel.
Long-term ML project involves developing and sustaining applications or systems that leverage machinelearning models, algorithms, and techniques. Failure to consider the severity of these problems can lead to issues like degraded model accuracy, datadrift, security issues, and data inconsistencies.
Auto DataDrift and Anomaly Detection Photo by Pixabay This article is written by Alparslan Mesri and Eren Kızılırmak. After deployment, MachineLearning model needs to be monitored. Model performance may change over time due to datadrift and anomalies in upcoming data.
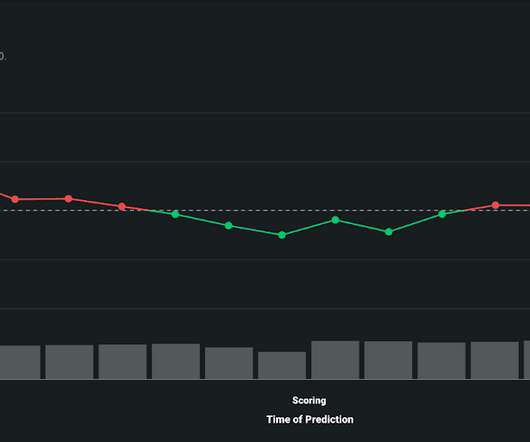
How do you track the integrity of a machinelearning model in production? By tracking service, drift, prediction data, training data, and custom metrics, you can keep your models and predictions relevant in a fast-changing world. Visualize DataDrift Over Time to Maintain Model Integrity.
Monitoring Modern MachineLearning (ML) Methods In Production. In our previous two posts, we discussed extensively how modelers are able to both develop and validate machinelearning models while following the guidelines outlined by the Federal Reserve Board (FRB) in SR 11-7. Monitoring Model Metrics.
Introduction Whether you’re a fresher or an experienced professional in the Data industry, did you know that ML models can experience up to a 20% performance drop in their first year? Monitoring these models is crucial, yet it poses challenges such as data changes, concept alterations, and data quality issues.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content