This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Lastly, balancing data volume and quality is an ongoing struggle. While massive, overly influential datasets can enhance model performance , they often include redundant or noisy information that dilutes effectiveness. Data validation frameworks play a crucial role in maintaining dataset integrity over time.
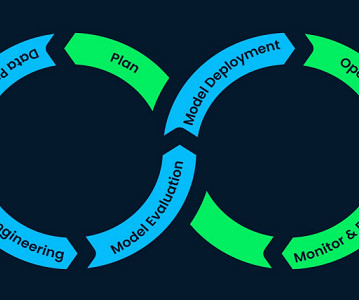
Machine learning starts with a defined dataset, but is then set free to absorb new data and create new learning paths and new conclusions. These outcomes may be unintended, biased, or inaccurate, as the model attempts to evolve on its own in what’s called “datadrift.”
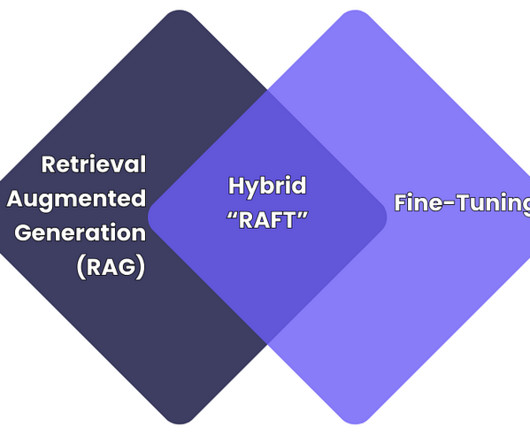
legal document review) It excels in tasks that require specialised terminologies or brand-specific responses but needs a lot of computational resources and may become obsolete with new data. Retrieval-Augmented Generation (RAG) RAG enhances LLMs by fetching additional information from external sources during inference to improve the response.
tweaktown.com Research Researchers unveil time series deep learning technique for optimal performance in AI models A team of researchers has unveiled a time series machine learning technique designed to address datadrift challenges. techxplore.com Are deepfakes illegal?
Or it can be external data from the web curated to fine-tune system performance. Model Re-training: Using the gathered information, the AI system is re-trained to make better predictions, provide answers, or carry out particular activities by refining the model parameters or weights. This is known as catastrophic forgetting.
Like any large tech company, data is the backbone of the Uber platform. Not surprisingly, data quality and drifting is incredibly important. Many datadrift error translates into poor performance of ML models which are not detected until the models have ran. TheSequence is a reader-supported publication.
This is not ideal because data distribution is prone to change in the real world which results in degradation in the model’s predictive power, this is what you call datadrift. There is only one way to identify the datadrift, by continuously monitoring your models in production.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
Imagine yourself as a pilot operating aircraft through a thunderstorm; you have all the dashboards and automated systems that inform you about any risks. You use this information to make decisions to navigate and land safely. Meanwhile, DataRobot can continuously train Challenger models based on more up-to-date data.
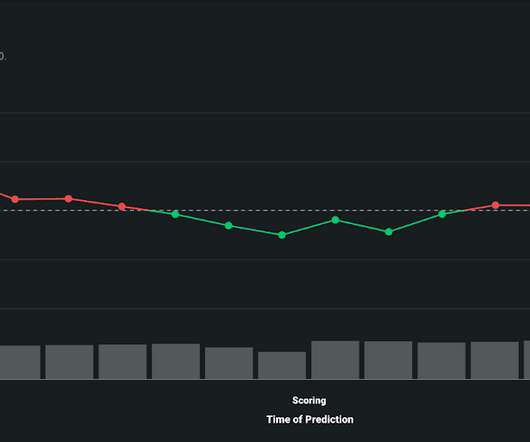
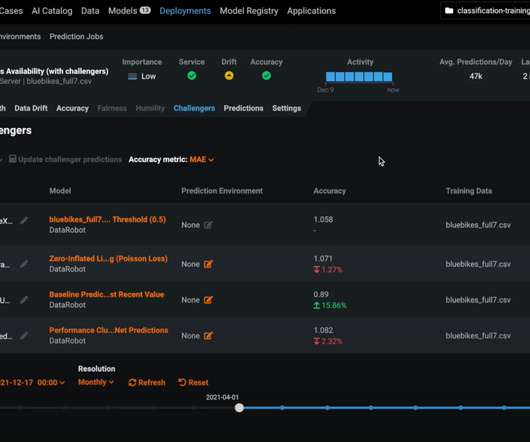
A myriad of issues can interfere with the performance and delivery of production models, resulting in poor or incomplete predictions and ill-informed decision-making. Visualize DataDrift Over Time to Maintain Model Integrity. The corrective action you take will depend on the cause and context of the drift.
Recently, we helped an EdTech startup build an information-retrieval app. Any scenario in which a student is looking for information that the corpus of documents can answer. The key shift in this SDLC is that evaluation isnt a final step, its an ongoing process that informs every design decision. How will you measure success?
Datadrift is a phenomenon that reflects natural changes in the world around us, such as shifts in consumer demand, economic fluctuation, or a force majeure. The key, of course, is your response time: how quickly datadrift can be analyzed and corrected. Drill Down into Drift for Rapid Model Diagnostics.
Auto DataDrift and Anomaly Detection Photo by Pixabay This article is written by Alparslan Mesri and Eren Kızılırmak. Model performance may change over time due to datadrift and anomalies in upcoming data. This can be prevented using Google’s Tensorflow Data Validation library.
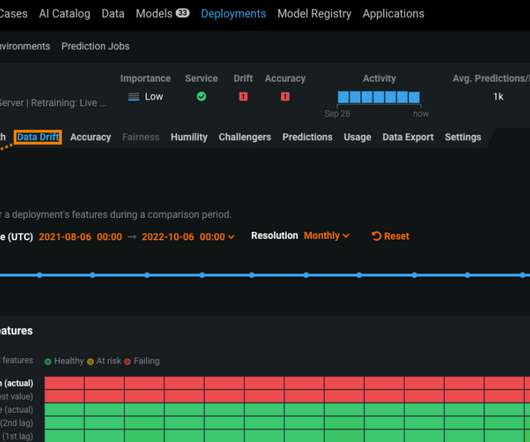
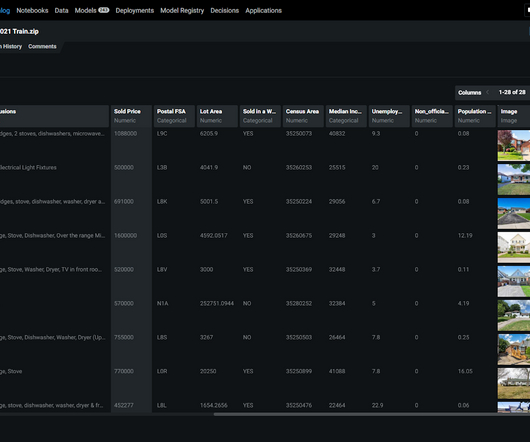
It should be clear when datadrift is happening and if the model needs to be retrained. The dataset we’ll be using contains information about homes and their sales price. Feature Impact displays that information, listing the most important features to the model in descending order. DataDrift.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
However, the data in the real world is constantly changing, and this can affect the accuracy of the model. This is known as datadrift, and it can lead to incorrect predictions and poor performance. In this blog post, we will discuss how to detect datadrift using the Python library TorchDrift.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
A prerequisite in measuring a deployed model’s evolving performance is to collect both its input data and business outcomes in a deployed setting. With this data in hand, we are able to measure both the datadrift and model performance, both of which are essential metrics in measuring the health of the deployed model.
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
At the higher levels of automation (Level 2 and above), the AD system performs multiple functions: Data collection – The AV system gathers information about the vehicle’s surroundings in real time with centimeter accuracy. AV systems fuse data from the devices that are integrated together to build a comprehensive perception.
Time Series forecasting using deep learning models can help retailers make more informed and strategic decisions about their operations and improve their competitiveness in the market. Describing the data As mentioned before, we will be using the data provided by Corporación Favorita in Kaggle.
The strength of modern AI is detecting patterns within historical data and using those learned patterns to make informed decisions on new data from the present. You can configure proactive notifications to alert you when the service health, datadrift status, model accuracy, or fairness exceed your defined acceptable levels.
However, dataset version management can be a pain for maturing ML teams, mainly due to the following: 1 Managing large data volumes without utilizing data management platforms. 2 Ensuring and maintaining high-quality data. 3 Incorporating additional data sources. 4 The time-consuming process of labeling new data points.
Can you debug system information? Metadata management : Robust metadata management capabilities enable you to associate relevant information, such as dataset descriptions, annotations, preprocessing steps, and licensing details, with the datasets, facilitating better organization and understanding of the data.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
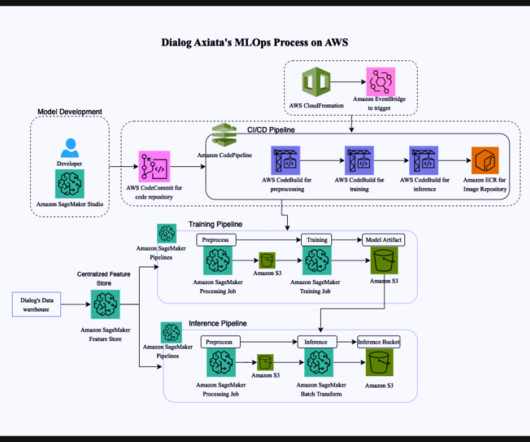
The analysis delves into various factors, such as customer profiles, usage patterns, and behavioral data, to accurately identify those at a higher risk of churning. With this powerful information, Dialog Axiata develops targeted retention strategies and campaigns specifically designed for high-risk customer groups.
Inadequate Monitoring : Neglecting to monitor user interactions and datadrifts hampers insights into product adoption and long-term performance. Consider a healthcare consultancy managing a vast database of drug information. Previously, consultants spent weeks manually querying data.
Can you provide more information about what the code is supposed to do and what isn’t working as expected? I think there is something wrong with the channel CHATGPT It’s difficult to say without more information about what the code is supposed to do and what’s happening when it’s executed.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Additionally, we also analyze unstructured information such as what amenities come with the property, for example a sauna or light fixtures, and review accompanying photographs. By analyzing all of this information, we aim to gain insights and determine an estimated selling price for a new property.
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
How Vodafone Uses Data Contracts Utilizing such a Data Contract, both in training and prediction pipelines, we can detect and diagnose issues such as outliers, inconsistencies, and errors in the data before they can cause problems with the models. Another great use of using Data Contracts is that it helps us detect datadrift.
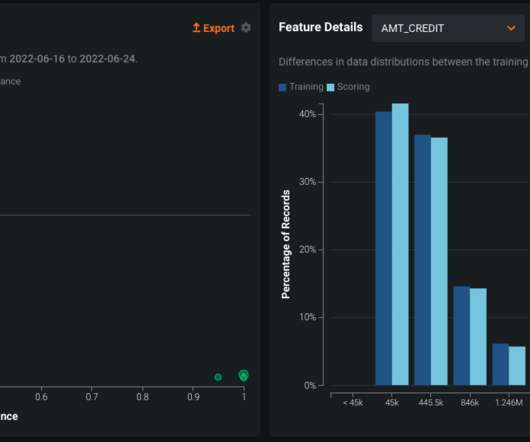
To solve this problem, you can leverage datasets with demographic and transactional information along with product and marketing campaign details. As you upload your data, DataRobot will do some initial exploratory data analysis to get a deeper understanding of the dataset prior to model training. A look at datadrift.
This can be useful for investors looking to make informed decisions about purchasing or selling stocks. Predicting energy consumption: Time series models can be used to analyze historical energy consumption data and make predictions about future energy demand. You can get the full code here.
Data science is a multidisciplinary field that relies on scientific methods, statistics, and Artificial Intelligence (AI) algorithms to extract knowledgable and meaningful insights from data. At its core, data science is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions.
For more information, please refer to this video. The data pipelines can be scheduled as event-driven or be run at specific intervals the users choose. Below are some pictorial representations of simple ETL operations we used for data transformation. The subsequent steps i.e
Computer vision models enable the machine to extract, analyze, and recognize useful information from a set of images. The authors performed data augmentation on image shape information by permuting the feature mean and variance within mini-batches. Researchers compared it to the other approaches that utilize MedMNIST-2D dataset.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. This technology enables businesses to make informed decisions, optimize resources, and enhance strategic planning. billion in 2024 and is projected to reach a mark of USD 1339.1
For example, it is illegal to use PII (Personal Identifiable Information) such as the address, gender, and age of a customer in AI models. With the help of XAI, companies can easily prove their compliance with regulations such as GDPR (General Data Protection Regulation). Why do we need local explanations?
DataRobot provides a push-button deployment framework with automatically generated compliance documentation, datadrift and accuracy monitoring, continuous retraining, and challenger analysis. More Information. Users can define prediction jobs that write results to Snowflake tables on a scheduled basis.
While there are many similarities with MLOps, LLMOps is unique because it requires specialized handling of natural-language data, prompt-response management, and complex ethical considerations. Retrieval Augmented Generation (RAG) enables LLMs to extract and synthesize information like an advanced search engine.
The proposed architecture for the batch inference pipeline uses Amazon SageMaker Model Monitor for data quality checks, while using custom Amazon SageMaker Processing steps for model quality check. Model approval After a newly trained model is registered in the model registry, the responsible data scientist receives a notification.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content