This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Consequently, AIOps is designed to harness data and insight generation capabilities to help organizations manage increasingly complex IT stacks. MLOps platforms are primarily used by data scientists, ML engineers, DevOps teams and ITOps personnel who use them to automate and optimize ML models and get value from AI initiatives faster.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. There is only one way to identify the datadrift, by continuously monitoring your models in production. What is MLOps?
In parallel to using data quality drift checks as a proxy for monitoring model degradation, the system also monitors feature attribution drift using the normalized discounted cumulative gain (NDCG) score. Pavel Maslov is a Senior DevOps and ML engineer in the Analytic Platforms team.
DataRobot DataDrift and Accuracy Monitoring detects when reality differs from the situation when the training dataset was created and the model trained. Meanwhile, DataRobot can continuously train Challenger models based on more up-to-date data. 1 IDC, MLOps – Where ML Meets DevOps, doc #US48544922, March 2022.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
MLOps is the intersection of Machine Learning, DevOps, and Data Engineering. Monitoring Models in Production There are several types of problems that Machine Learning applications can encounter over time [4]: Datadrift: sudden changes in the features values or changes in data distribution.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Data science – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation. MLOps engineering – Focuses on automating the DevOps pipelines for operationalizing the ML use case. Monitoring setup (model, datadrift). Deploy to production (inference endpoint).
These agents apply the concept familiar in the DevOps world—to run models in their preferred environments while monitoring all models centrally. DataRobot’s MLOps product offers a host of features designed to transform organizations’ user experience, firstly, through its model-monitoring agents.
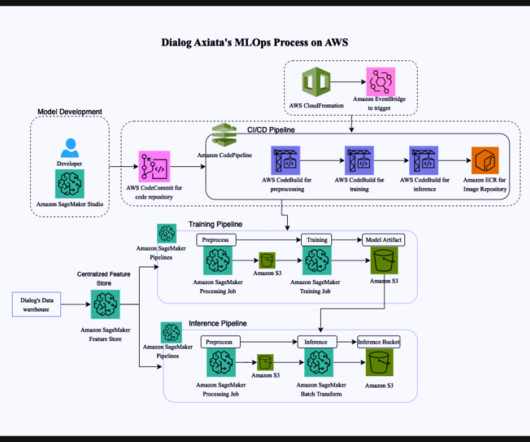
The incorporation of an experiment tracking system facilitates the monitoring of performance metrics, enabling a data-driven approach to decision-making. Datadrift and model drift are also monitored. By developing this project under the AI Factory framework, Dialog Axiata could overcome the aforementioned challenges.
Security: We have included steps and best practices from GitHub’s advanced security scanning and credential scanning (also available in Azure DevOps) that can be incorporated into the workflow. This will help teams maintain the confidentiality of their projects and data. is modified to push the data into ADX.
Some popular data quality monitoring and management MLOps tools available for data science and ML teams in 2023 Great Expectations Great Expectations is an open-source library for data quality validation and monitoring. It could help you detect and prevent data pipeline failures, datadrift, and anomalies.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a data science development account (which has more controls than a typical application development account). Refer to Operating model for best practices regarding a multi-account strategy for ML.
The DevOps and Automation Ops departments are under the infrastructure team. They also need to monitor and see changes in the data distribution ( datadrift, concept drift , etc.) The infrastructure team focuses on technology and delivers tools that other teams will adapt and use to work on their main deliverables.
The data scientists are here with software engineers. ML platform team can be for this DevOps team. That meant the data scientists, you could say the only thing that they were responsible for was the model. Piotr: Sounds like something with data, right? Datadrift. So trying to capture and use that.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. It is most common to use containers for machine learning pipelines.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content