This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. Find out how Viso Suite can automate your team’s projects by booking a demo.
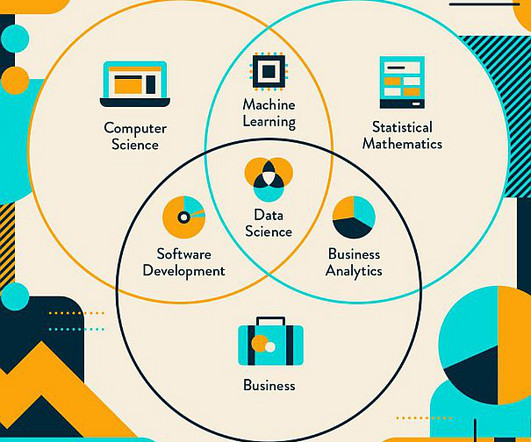
Get a demo here. Data Science Process Data Acquisition The first step in the data science process is to define the research goal. The next step is to acquire appropriate data that will enable you to derive insights. NumPy can be seen as a set of Python APIs that enables efficient scientific computing.
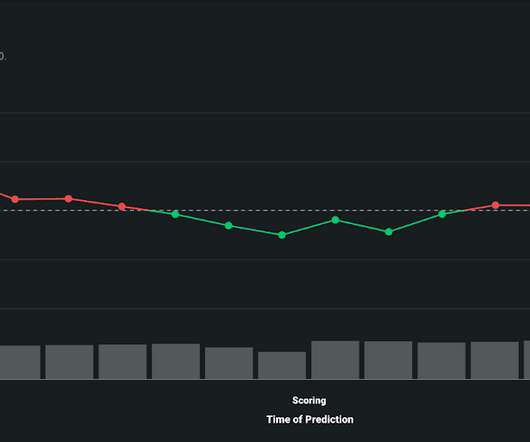
Model Observability provides an end-to-end picture of the internal states of a system, such as the system’s inputs, outputs, and environment, including datadrift, prediction performance, service health, and more relevant metrics. Visualize DataDrift Over Time to Maintain Model Integrity. Drift Over Time.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
For our joint solution with Snowflake, this means that code-first users can use DataRobot’s hosted Notebooks as the interface and Snowpark processes the data directly in the data warehouse. The DataRobot MLOps dashboards present the model’s health, datadrift, and accuracy over time and can help determine model accountability.
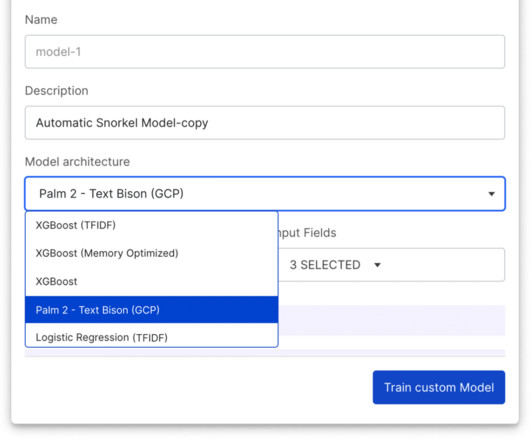
When Vertex Model Monitoring detects datadrift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
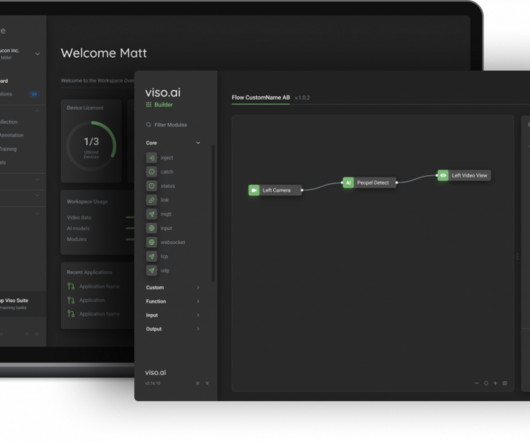
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., It enables data scientists to log, compare, and visualize experiments, track code, hyperparameters, metrics, and outputs. and Pandas or Apache Spark DataFrames.
When Vertex Model Monitoring detects datadrift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Book a demo today. Revamped Snorkel Flow SDK Also included in the 2023.R3 The post Snorkel Flow 2023.R3
For code-first users, we offer a code experience too, using the AP—both in Python and R—for your convenience. Check for model accuracy and datadrift and inspect each model from governance and service health perspectives, respectively. The process I will present will be using the DataRobot GUI. Setting up a Time Series Project.
Introduction Deepchecks is a groundbreaking open-source Python package that aims to simplify and enhance the process of implementing automated testing for machine learning (ML) models. A quick run down through the demonstrated notebook: Demonstration: Google Colaboratory Shouldn’t miss the demo. From Research to Production.
Learn more by booking a demo. Viso Suite: the only end-to-end computer vision platform Lightweight Models for Face Recognition DeepFace – Lightweight Face Recognition Analyzing Facial Attribute DeepFace AI is Python’s lightweight face recognition and facial attribute library.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Kedro Kedro is a Python library for building modular data science pipelines.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content