This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
And sensory gating causes our brains to filter out information that isn’t novel, resulting in a failure to notice gradual datadrift or slow deterioration in system accuracy. DataDrift assesses how the distribution of data changes across all features. Contact us to request a personal demo. Request a demo.
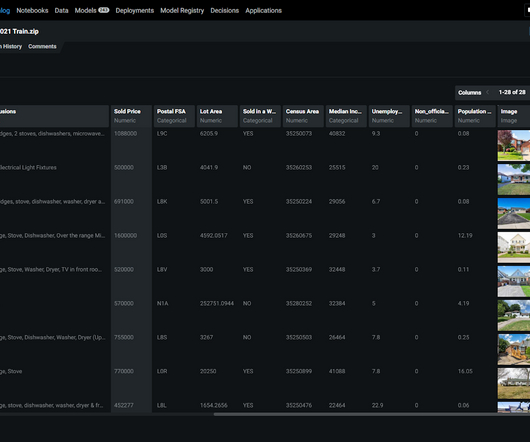
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. It enables data scientists to log, compare, and visualize experiments, track code, hyperparameters, metrics, and outputs. It could help you detect and prevent data pipeline failures, datadrift, and anomalies.
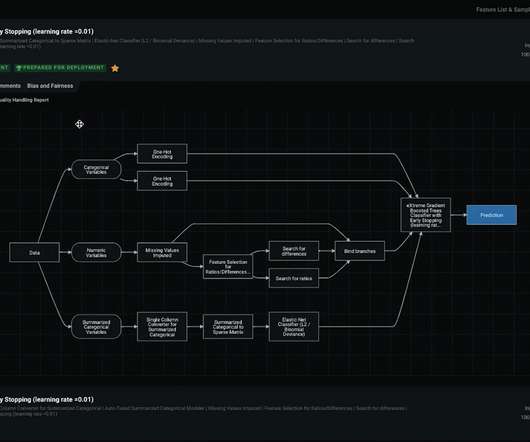
The model training process is not a black box—it includes trust and explainability. You can see the entire process from data to predictions with all of the different steps—as well as the supportive documentation on every stage and an automated compliance report, which is very important for highly regulated industries.
The demo from the session highlights unique and differentiated capabilities that empower all users—from the analysts to the data scientists and even the person at the end of the journey who just needs to access an instant price estimate. DataRobot does a great job of explaining exactly how it got to this feature.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
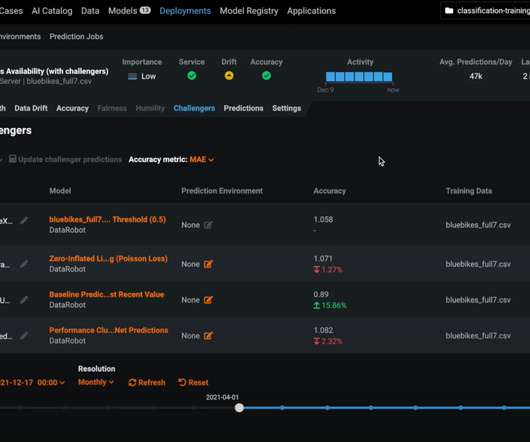
This explainability of the predictions can help you see how and why the AI came to these predictions. Set up a data pipeline that delivers predictions to HubSpot and automatically initiate offers within the business rules you set. A look at datadrift. A clear picture of the model’s accuracy. AI Experience 2022.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Is it a black-box model, or can the decisions be explained? Kale v0.7.0.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content