This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Biased training data can lead to discriminatory outcomes, while datadrift can render models ineffective and labeling errors can lead to unreliable models. PyTorch is an open-source AI framework offering an intuitive interface that enables easier debugging and a more flexible approach to building deeplearning models.
Machine learning frameworks like scikit-learn are quite popular for training machine learning models while TensorFlow and PyTorch are popular for training deeplearning models that comprise different neuralnetworks.
Over the last 10 years, a number of players have developed autonomous vehicle (AV) systems using deepneuralnetworks (DNNs). These systems require petabytes of data and thousands of compute units (vCPUs and GPUs) to train. DNN training methods and design AV systems are built with deepneuralnetworks.
Some popular data quality monitoring and management MLOps tools available for data science and ML teams in 2023 Great Expectations Great Expectations is an open-source library for data quality validation and monitoring. It could help you detect and prevent data pipeline failures, datadrift, and anomalies.
Time Series forecasting using deeplearning models can help retailers make more informed and strategic decisions about their operations and improve their competitiveness in the market. Describing the data As mentioned before, we will be using the data provided by Corporación Favorita in Kaggle.
Our software helps several leading organizations start with computer vision and implement deeplearning models efficiently with minimal overhead for various downstream tasks. Data Science Process Data Acquisition The first step in the data science process is to define the research goal. About us : Viso.ai
Today’s boom in CV started with the implementation of deeplearning models and convolutional neuralnetworks (CNN). Pacal conducted a large-scale study with a total of 106 deeplearning models. It surpassed all existing deeplearning models, thus achieving 99.02% accuracy on the SIPaKMeD dataset.
Artificial Intelligence (AI) models assist across various domains, from regression-based forecasting models to complex object detection algorithms in deeplearning. That’s exactly why we need methods to understand the factors influencing the decisions made by any deeplearning model. Why do we need Explainable AI (XAI)?
NannyML is an open-source python library that allows you to estimate post-deployment model performance (without access to targets), detect datadrift, and intelligently link datadrift alerts back to changes in model performance. It captures and provides the timings for all the layers present in the model.
In this section, we explore popular AI models for Time Series Forecasting, highlighting their unique features, advantages, and applications, including LSTM networks, Transformers, and user-friendly tools like Facebook Prophet. LSTMs are particularly effective for tasks where context from previous time steps is crucial.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deeplearning algorithms to forecast sales, predict customer churn and fraud detection, etc., Most of its products use machine learning or deeplearning models for some or all of their features.
Then using Machine Learning and DeepLearning sentiment analysis techniques, these businesses analyze if a customer feels positive or negative about their product so that they can make appropriate business decisions to improve their business. is one of the best options.
Sheer volume—I think where this came about is when we had the rise of deeplearning, there was a much larger volume of data used, and of course, we had big data that was driving a lot of that because we found ourselves with these mountains of data. That’s where you start to see datadrift.
Sheer volume—I think where this came about is when we had the rise of deeplearning, there was a much larger volume of data used, and of course, we had big data that was driving a lot of that because we found ourselves with these mountains of data. That’s where you start to see datadrift.
Sheer volume—I think where this came about is when we had the rise of deeplearning, there was a much larger volume of data used, and of course, we had big data that was driving a lot of that because we found ourselves with these mountains of data. That’s where you start to see datadrift.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






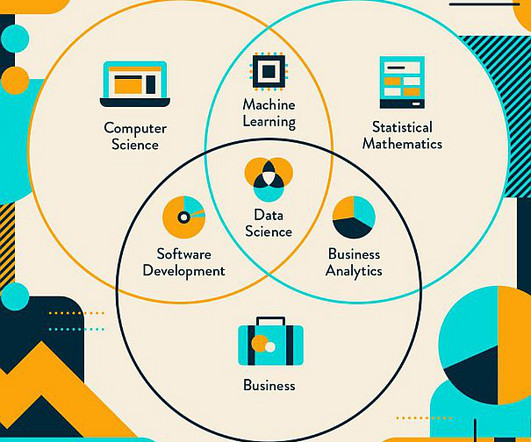


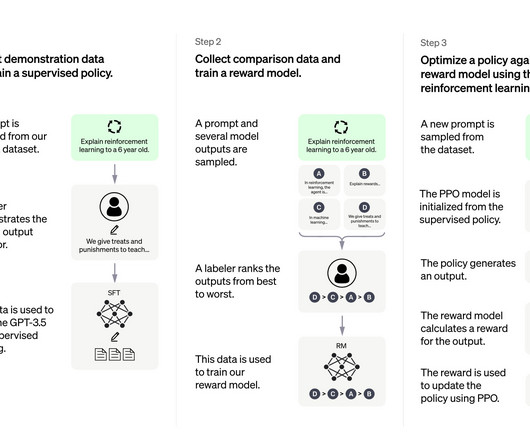












Let's personalize your content