This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There might be changes in the data distribution in production, thus causing […]. The post The Importance of DataDrift Detection that DataScientists Do Not Know appeared first on Analytics Vidhya. But, once deployed in production, ML models become unreliable and obsolete and degrade with time.
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for datascientist to remain competitive in the market. Coding skills remain important, but the real value of datascientists today is shifting.
Human element: Datascientists are vulnerable to perpetuating their own biases into models. Machine learning : Even if scientists were to create purely objective AI, models are still highly susceptible to bias. One way to identify bias is to audit the data used to train the model.
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and data governance processes.
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. An example of how datadrift may occur is in the context of changing mobile usage patterns over time.
Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among datascientists, DevOps engineers, and IT teams. Model Training Frameworks This stage involves the process of creating and optimizing predictive models with labeled and unlabeled data.
Collaboration – Datascientists each worked on their own local Jupyter notebooks to create and train ML models. They lacked an effective method for sharing and collaborating with other datascientists. This has helped the datascientist team to create and test pipelines at a much faster pace.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
Each product translates into an AWS CloudFormation template, which is deployed when a datascientist creates a new SageMaker project with our MLOps blueprint as the foundation. These are essential for monitoring data and model quality, as well as feature attributions. Alerts are raised whenever anomalies are detected.
As AI-driven use cases increase, the number of AI models deployed increases as well, leaving resource-strapped data science teams struggling to monitor and maintain this growing repository. “We Today, his team is using open-source packages without a standardized AI platform. Accelerating Value-Realization with Industry Specific Use Cases.
Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Datascientists need to understand the business problem and the project scope to assess feasibility, set expectations, define metrics, and design project blueprints. Monitor and observe results.
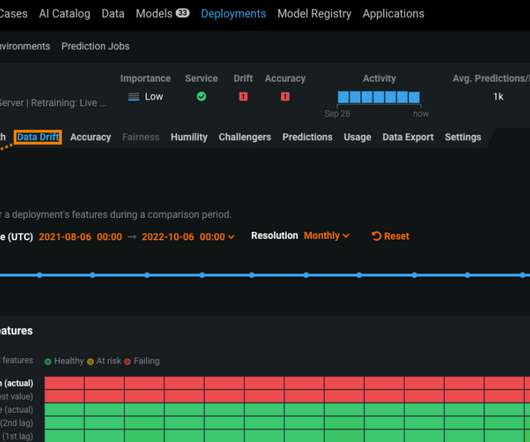
The primary goal of model monitoring is to ensure that the model remains effective and reliable in making predictions or decisions, even as the data or environment in which it operates evolves. Datadrift refers to a change in the input data distribution that the model receives.
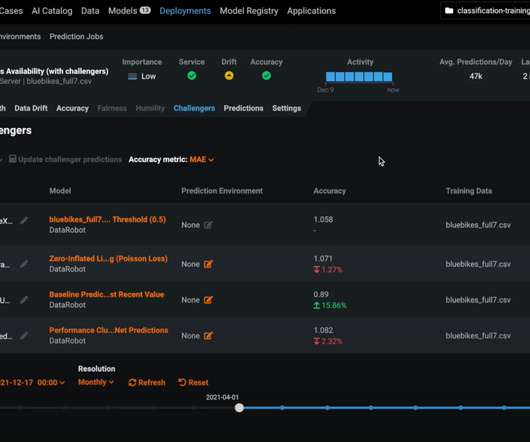
Additionally, DataRobot datascientists and support teams have a proven record of success working with thousands of customers on tens of thousands of AI use cases across a wide range of industries. Using DataRobot, companies can monitor their models in production for accuracy and datadrift, in addition to retraining them proactively.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
By tracking service, drift, prediction data, training data, and custom metrics, you can keep your models and predictions relevant in a fast-changing world. Tracking integrity is important: more than 84% of datascientists do not trust the model once it is in production. Drift Over Time.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
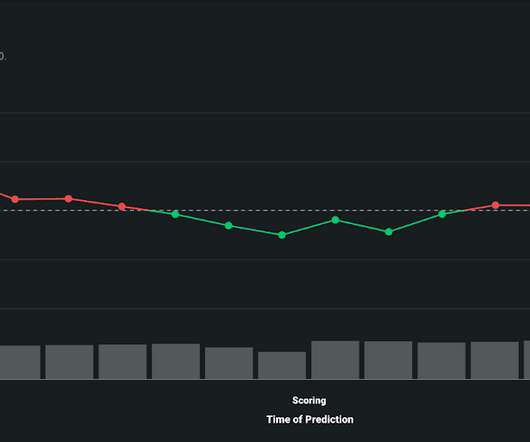
Datadrift is a phenomenon that reflects natural changes in the world around us, such as shifts in consumer demand, economic fluctuation, or a force majeure. The key, of course, is your response time: how quickly datadrift can be analyzed and corrected. Drill Down into Drift for Rapid Model Diagnostics.
Causation, Collision, and Confusion: Avoiding the most dangerous error in Statistics Datascientists know full well the dangers of bias, especially collision bias. This includes datadrift, cold starts, sudden scaling, and competing priorities.
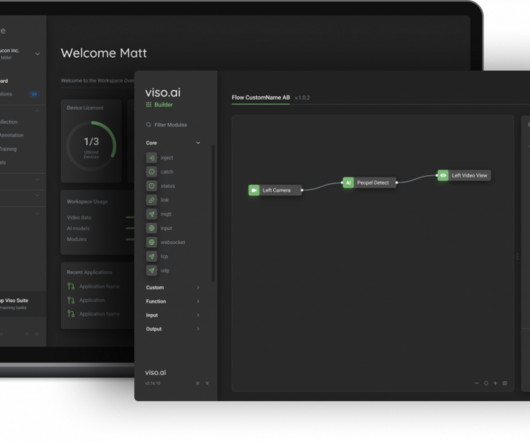
During machine learning model training, there are seven common errors that engineers and datascientists typically run into. It enables enterprises to create and implement computer vision solutions , featuring built-in ML tools for data collection, annotation, and model training. 6: DataDrift What is DataDrift?
Ensuring Long-Term Performance and Adaptability of Deployed Models Source: [link] Introduction When working on any machine learning problem, datascientists and machine learning engineers usually spend a lot of time on data gathering , efficient data preprocessing , and modeling to build the best model for the use case.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
Datascientists can use Amazon SageMaker Experiments , which automatically tracks the inputs, parameters, configurations, and results of iterations as trials. You can set up automated alerts to notify when there are deviations in the model quality, such as datadrift and anomalies.
When a new version of the model is registered in the model registry, it triggers a notification to the responsible datascientist via Amazon SNS. If the batch inference pipeline discovers data quality issues, it will notify the responsible datascientist via Amazon SNS.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
By outsourcing the day-to-day management of the data science platform to the team who created the product, AI builders can see results quicker and meet market demands faster, and IT leaders can maintain rigorous security and data isolation requirements.
Machine Learning Operations (MLOps) can significantly accelerate how datascientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
This new guided workflow is designed to ensure success for your AI use case, regardless of complexity, catering to both seasoned datascientists and those just beginning their journey.
Inadequate Monitoring : Neglecting to monitor user interactions and datadrifts hampers insights into product adoption and long-term performance. By adopting these practices, data professionals can drive innovation while mitigating risks, ensuring LLM-based solutions achieve both traction and reliability.
This new guided workflow is designed to ensure success for your AI use case, regardless of complexity, catering to both seasoned datascientists and those just beginning their journey.
For true impact, AI projects should involve datascientists, plus line of business owners and IT teams. By 2025, according to Gartner, chief data officers (CDOs) who establish value stream-based collaboration will significantly outperform their peers in driving cross-functional collaboration and value creation.
It can also include constraints on the data, such as: Minimum and maximum values for numerical columns Allowed values for categorical columns. Before a model is productionized, the Contract is agreed upon by the stakeholders working on the pipeline, such as the ML Engineers, DataScientists and Data Owners.
How do you drive collaboration across teams and achieve business value with data science projects? With AI projects in pockets across the business, datascientists and business leaders must align to inject artificial intelligence into an organization. You can also go beyond regular accuracy and datadrift metrics.
Solution: Because MLOps allows model reuse, datascientists do not have to create the same models over and over, and the business can package, control, and scale them. Refreshing models according to the business schedule or signs of datadrift. Constantly creating and testing new challenger models.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
For example, the IKEA effect is a cognitive bias that causes datascientists to overvalue AI systems that they have personally built. And sensory gating causes our brains to filter out information that isn’t novel, resulting in a failure to notice gradual datadrift or slow deterioration in system accuracy.
With governed, secure, and compliant environments, datascientists have the time to focus on innovation, and IT teams can focus on compliance, risk, and production with live performance updates, streamed to a centralized machine learning operations system.
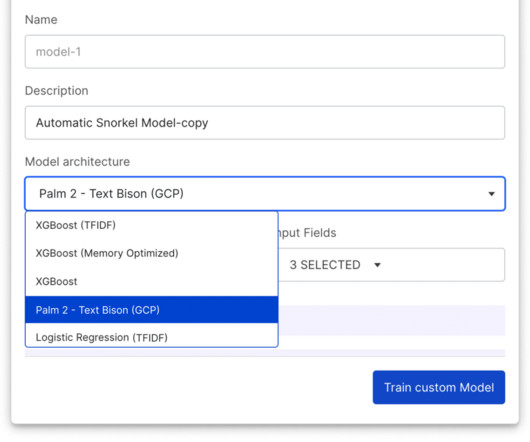
This new guided workflow is designed to ensure success for your AI use case, regardless of complexity, catering to both seasoned datascientists and those just beginning their journey. Learn more about what Snorkel can do for your organization Snorkel AI offers multiple ways for enterprises to uplevel their AI capabilities.
The first is by using low-code or no-code ML services such as Amazon SageMaker Canvas , Amazon SageMaker Data Wrangler , Amazon SageMaker Autopilot , and Amazon SageMaker JumpStart to help data analysts prepare data, build models, and generate predictions. Monitoring setup (model, datadrift).
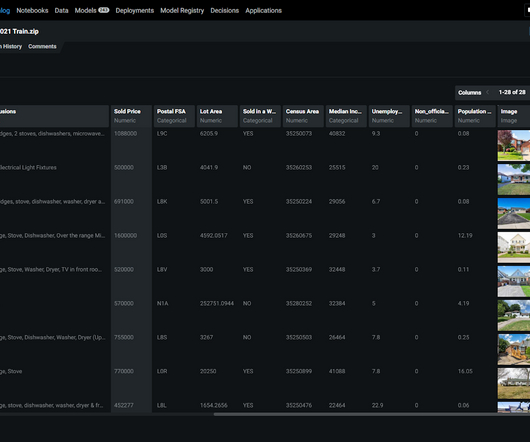
Describing the data As mentioned before, we will be using the data provided by Corporación Favorita in Kaggle. After deployment, we will monitor the model performance with the current best model and check for datadrift and model drift. Apart from that, we must constantly monitor the data as well.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. You can get the full code here. We pay our contributors, and we don’t sell ads.
However, dataset version management can be a pain for maturing ML teams, mainly due to the following: 1 Managing large data volumes without utilizing data management platforms. 2 Ensuring and maintaining high-quality data. 3 Incorporating additional data sources. 4 The time-consuming process of labeling new data points.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content