This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon What is Model Monitoring and why is it required? Machine learning creates static models from historical data. There might be changes in the data distribution in production, thus causing […].
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for data scientist to remain competitive in the market. You have to understand data, how to extract value from them and how to monitor model performances.
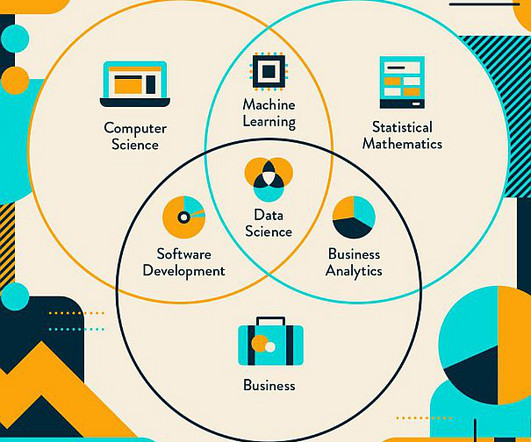
Datascience is a multidisciplinary field that relies on scientific methods, statistics, and Artificial Intelligence (AI) algorithms to extract knowledgable and meaningful insights from data. At its core, datascience is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions.
This is not ideal because data distribution is prone to change in the real world which results in degradation in the model’s predictive power, this is what you call datadrift. There is only one way to identify the datadrift, by continuously monitoring your models in production. What is Weights & Biases?
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and datascience experience who wanted to implement MLOps. Join thousands of data leaders on the AI newsletter.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., DataRobot MLOps facilitates collaboration between data scientists, data engineers, and IT operations, ensuring smooth integration of models into the production environment.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Key Challenges in ML Model Monitoring in Production DataDrift and Concept DriftData and concept drift are two common types of drift that can occur in machine-learning models over time. Datadrift refers to a change in the input data distribution that the model receives.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new datascience project and get it to production.
A seamless user experience when deploying and monitoring DataRobot models to Snowflake Monitoring service health, drift, and accuracy of DataRobot models in Snowflake “Organizations are looking for mature datascience platforms that can scale to the size of their entire business. launch event on March 16th.
GitLab CI/CD serves as the macro-orchestrator, orchestrating model build and model deploy pipelines, which include sourcing, building, and provisioning Amazon SageMaker Pipelines and supporting resources using the SageMaker Python SDK and Terraform. SageMaker Pipelines serves as the orchestrator for ML model training and inference workflows.
However, the data in the real world is constantly changing, and this can affect the accuracy of the model. This is known as datadrift, and it can lead to incorrect predictions and poor performance. In this blog post, we will discuss how to detect datadrift using the Python library TorchDrift.
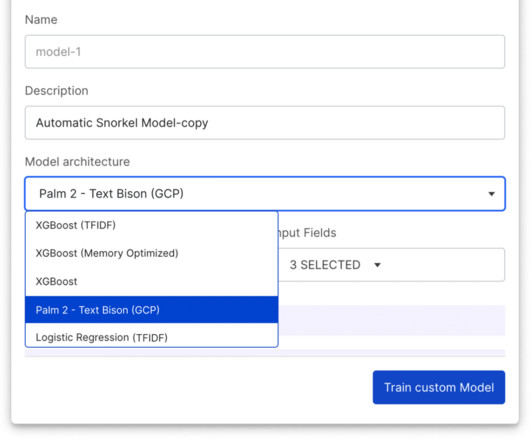
When Vertex Model Monitoring detects datadrift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. See what Snorkel can do to accelerate your datascience and machine learning teams. Book a demo today.
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional data engineering and machine learning life cycles.
Uber wrote about how they build a datadrift detection system. To quantify the impact of such data incidents, the Fares datascience team has built a simulation framework that replicates corrupted data from real production incidents and assesses the impact on the fares data model performance.
By simplifying Time Series Forecasting models and accelerating the AI lifecycle, DataRobot can centralize collaboration across the business—especially datascience and IT teams—and maximize ROI. For code-first users, we offer a code experience too, using the AP—both in Python and R—for your convenience.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. You can learn more about Comet here. You can get the full code here.
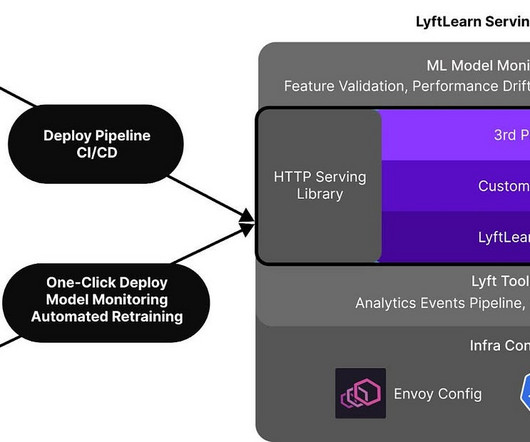
You essentially divide things up into large tasks and chunks, but the software engineering that goes within that task is the thing that you’re generally gonna be updating and adding to over time as your machine learning grows within your company or you have new data sources, you want to create new models, right? To figure it out.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Kedro Kedro is a Python library for building modular datascience pipelines.
However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of data scientists and analysts. Most employees don’t master the conventional datascience toolkit (SQL, Python, R etc.). the changing distribution of the data to which the model is applied.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content