This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon What is Model Monitoring and why is it required? Machine learning creates static models from historical data. But, once deployed in production, ML models become unreliable and obsolete and degrade with time.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
In this regard, I believe the future of datascience belongs to those: who can connect the dots and deliver results across the entire data lifecycle. You have to understand data, how to extract value from them and how to monitor model performances. These two languages cover most datascience workflows.
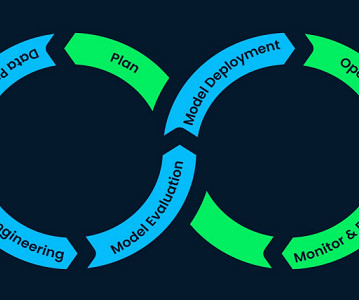
Learn how to develop an ML project from development to production. Many beginners in datascience and machine learning only focus on the data analysis and model development part, which is understandable, as the other department often does the deployment process. Establish a DataScience Project2.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
From NLP, ML, and generative AI, to even artificial general intelligence, the topics were diverse and awe-inspiring. DataScience Software Acceleration at the Edge Attendees had an amazing time learning about unlocking the potential of datascience through acceleration.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker.
IDC 2 predicts that by 2024, 60% of enterprises would have operationalized their ML workflows by using MLOps. The same is true for your ML workflows – you need the ability to navigate change and make strong business decisions. These and many other questions are now on top of the agenda of every datascience team.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Leveraging DataRobot’s JDBC connectors, enterprise teams can work together to train ML models on their data residing in SAP HANA Cloud and SAP Data Warehouse Cloud, as well as have an option to enrich it with data from external data sources.
As newer fields emerge within datascience and the research is still hard to grasp, sometimes it’s best to talk to the experts and pioneers of the field. That’s the datadrift problem, aka the performance drift problem. Josh did his PhD in Computer Science at UC Berkeley advised by Pieter Abbeel.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition. 2 Ensuring and maintaining high-quality data.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and datascience experience who wanted to implement MLOps. Join thousands of data leaders on the AI newsletter.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Many tools and techniques are available for ML model monitoring in production, such as automated monitoring systems, dashboarding and visualization, and alerts and notifications. Datadrift refers to a change in the input data distribution that the model receives. The MLOps difference?
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
By outsourcing the day-to-day management of the datascience platform to the team who created the product, AI builders can see results quicker and meet market demands faster, and IT leaders can maintain rigorous security and data isolation requirements. Peace of Mind with Secure AI-Driven DataScience on Google Cloud.
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machine learning models, and locked ROI. Exploratory Data Analysis After we connect to Snowflake, we can start our ML experiment.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Datascience practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
Once the best model is identified, it is usually deployed in production to make accurate predictions on real-world data (similar to the one on which the model was trained initially). Ideally, the responsibilities of the ML engineering team should be completed once the model is deployed. But this is only sometimes the case.
Auto DataDrift and Anomaly Detection Photo by Pixabay This article is written by Alparslan Mesri and Eren Kızılırmak. Model performance may change over time due to datadrift and anomalies in upcoming data. This can be prevented using Google’s Tensorflow Data Validation library.
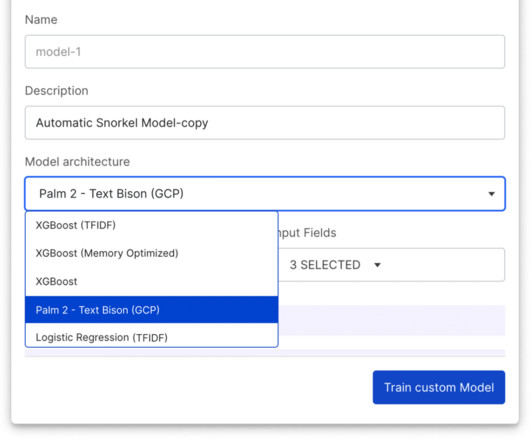
Enhanced user experience in Snorkel Flow Studio We’ve made significant improvements to Snorkel Flow Studio, making it easier for you to export training datasets in the UI, improving default display settings, adding per-class filtering and analysis, and several other great enhancements for easier integration with larger ML pipelines.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
In the first part of the “Ever-growing Importance of MLOps” blog, we covered influential trends in IT and infrastructure, and some key developments in ML Lifecycle Automation. DataRobot’s Robust ML Offering. This capability is a vital addition to the AI and ML enterprise workflow.
Snorkel AI and Google Cloud have partnered to help organizations successfully transform raw, unstructured data into actionable AI-powered systems. Snorkel Flow easily deploys on Google Cloud infrastructure, ingests data from Google Cloud data sources, and integrates with Google Cloud’s AI and Data Cloud services.
Snorkel AI and Google Cloud have partnered to help organizations successfully transform raw, unstructured data into actionable AI-powered systems. Snorkel Flow easily deploys on Google Cloud infrastructure, ingests data from Google Cloud data sources, and integrates with Google Cloud’s AI and Data Cloud services.
Building a machine learning (ML) pipeline can be a challenging and time-consuming endeavor. Inevitably concept and datadrift over time cause degradation in a model’s performance. For an ML project to be successful, teams must build an end-to-end MLOps workflow that is scalable, auditable, and adaptable.
Building a machine learning (ML) pipeline can be a challenging and time-consuming endeavor. Inevitably concept and datadrift over time cause degradation in a model’s performance. For an ML project to be successful, teams must build an end-to-end MLOps workflow that is scalable, auditable, and adaptable.
By simplifying Time Series Forecasting models and accelerating the AI lifecycle, DataRobot can centralize collaboration across the business—especially datascience and IT teams—and maximize ROI. Once the data is ready to start the training process, you need to choose your target variable. Configuring an ML project.
Having a canonical set of definitions in the ML community for all of these different notions of “models” would be immensely helpful. Uber wrote about how they build a datadrift detection system. Riders’ reaction to these different components and trip conversion rates are critical to building fares ML models.
Inadequate Monitoring : Neglecting to monitor user interactions and datadrifts hampers insights into product adoption and long-term performance. Real-World Application: Text-to-SQL in Healthcare In his talk, Noe provided a real-world case study on the issue. Register now for only$299!
The presented MLOps workflow provides a reusable template for managing the ML lifecycle through automation, monitoring, auditability, and scalability, thereby reducing the complexities and costs of maintaining batch inference workloads in production. SageMaker Pipelines serves as the orchestrator for ML model training and inference workflows.
Python is unarguably the most broadly used programming language throughout the datascience community. After a model has been selected for production, most datascience teams are faced with the question of “now what?” Consuming AI/ML Insights for Faster Decision Making.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times. If all goes well, of course ?
This workflow will be foundational to our unstructured data-based machine learning applications as it will enable us to minimize human labeling effort, deliver strong model performance quickly, and adapt to datadrift.” – Jon Nelson, Senior Manager of DataScience and Machine Learning at United Airlines.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content