This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this regard, I believe the future of datascience belongs to those: who can connect the dots and deliver results across the entire data lifecycle. You have to understand data, how to extract value from them and how to monitor model performances. These two languages cover most datascience workflows.
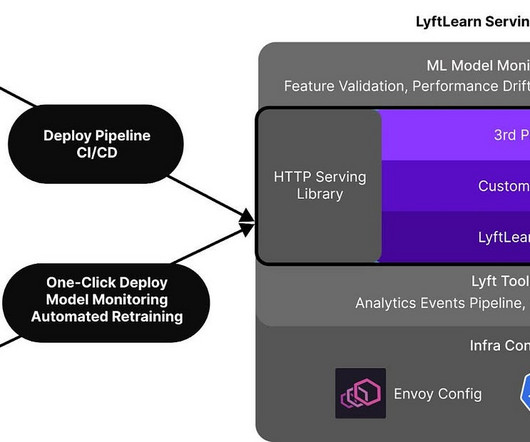
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
Axfood has a structure with multiple decentralized datascience teams with different areas of responsibility. Together with a central data platform team, the datascience teams bring innovation and digital transformation through AI and ML solutions to the organization.
Key Challenges in ML Model Monitoring in Production DataDrift and Concept DriftData and concept drift are two common types of drift that can occur in machine-learning models over time. Datadrift refers to a change in the input data distribution that the model receives.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and datascience experience who wanted to implement MLOps. Join thousands of data leaders on the AI newsletter.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale.
Evaluate the computing resources and development environment that the datascience team will need. Large projects or those involving text, images, or streaming data may need specialized infrastructure. Discuss with stakeholders how accuracy and datadrift will be monitored. Ensure predictions are explainable.
Uber wrote about how they build a datadrift detection system. To quantify the impact of such data incidents, the Fares datascience team has built a simulation framework that replicates corrupted data from real production incidents and assesses the impact on the fares data model performance.
By outsourcing the day-to-day management of the datascience platform to the team who created the product, AI builders can see results quicker and meet market demands faster, and IT leaders can maintain rigorous security and data isolation requirements. Peace of Mind with Secure AI-Driven DataScience on Google Cloud.
Data engineering – Identifies the data sources, sets up data ingestion and pipelines, and prepares data using Data Wrangler. Datascience – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation. Monitoring setup (model, datadrift).
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
All models built within DataRobot MLOps support ethical AI through configurable bias monitoring and are fully explainable and transparent. The in-built, data quality assessments and visualization tools result in equitable, fair models that minimize the potential for harm, along with world-class datadrift, service help, and accuracy tracking.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
By simplifying Time Series Forecasting models and accelerating the AI lifecycle, DataRobot can centralize collaboration across the business—especially datascience and IT teams—and maximize ROI. The model training process is not a black box—it includes trust and explainability. DataRobot Blueprint—from data to predictions.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a datascience development account (which has more controls than a typical application development account). He is passionate about Statistics, NLP and Model Explainability in AI/ML.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Is it a black-box model, or can the decisions be explained? Kale v0.7.0.
However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of data scientists and analysts. Most employees don’t master the conventional datascience toolkit (SQL, Python, R etc.). Adaptability over time To use Text2SQL in a durable way, you need to adapt to datadrift, i.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content