This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its not a choice between better data or better models. The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use big data , but a much lower number manage to use it successfully. Why is this the case?
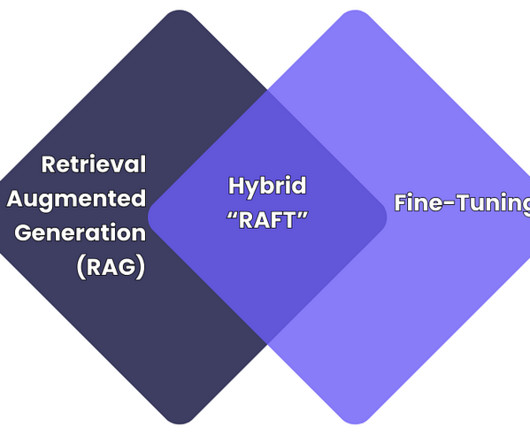
legal document review) It excels in tasks that require specialised terminologies or brand-specific responses but needs a lot of computational resources and may become obsolete with new data. Retrieval-Augmented Generation (RAG) RAG enhances LLMs by fetching additional information from external sources during inference to improve the response.
Like any large tech company, data is the backbone of the Uber platform. Not surprisingly, dataquality and drifting is incredibly important. Many datadrift error translates into poor performance of ML models which are not detected until the models have ran.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
Can you debug system information? Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Can you compare images?
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
The batch inference pipeline includes steps for checking dataquality against a baseline created by the training pipeline, as well as model quality (model performance) if ground truth labels are available. If the batch inference pipeline discovers dataquality issues, it will notify the responsible data scientist via Amazon SNS.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
How Vodafone Uses Data Contracts Utilizing such a Data Contract, both in training and prediction pipelines, we can detect and diagnose issues such as outliers, inconsistencies, and errors in the data before they can cause problems with the models. Another great use of using Data Contracts is that it helps us detect datadrift.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. This technology enables businesses to make informed decisions, optimize resources, and enhance strategic planning. billion in 2024 and is projected to reach a mark of USD 1339.1
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. For more information, please refer to this video. The subsequent steps i.e
DataRobot will automatically perform a dataquality assessment, determine the problem domain to solve for whether that be binary classification, regression, etc., More Information. This can be done programmatically through an API or in a point-and-click GUI environment. and recommend the best optimization metric to use.
Here are some specific reasons why they are important: Data Integration: Organizations can integrate data from various sources using ETL pipelines. This provides data scientists with a unified view of the data and helps them decide how the model should be trained, values for hyperparameters, etc.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Sentiment analysis, commonly referred to as opinion mining/sentiment classification, is the technique of identifying and extracting subjective information from source materials using computational linguistics , text analysis , and natural language processing. Using a tool like neptune.ai Tools like Domino , Superwise AI , Arize AI , etc.,
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. This is to say that clean data can better teach our models.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. This is to say that clean data can better teach our models.
Depending on your size, you might have a data catalog. Maybe storing and emitting open lineage information, etc. One of the features that Hamilton has is that it has a really lightweight dataquality runtime check. If you’re using tabular data, there’s Pandera. Datadrift.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Data ingestion (extraction and versioning). Data validation (writing tests to check for dataquality). Data preprocessing. It checks the data for quality issues and detects outliers and anomalies.
Those pillars are 1) benchmarks—ways of measuring everything from speed to accuracy, to dataquality, to efficiency, 2) best practices—standard processes and means of inter-operating various tools, and most importantly to this discussion, 3) data. In order to do this, we need to get better at measuring dataquality.
Those pillars are 1) benchmarks—ways of measuring everything from speed to accuracy, to dataquality, to efficiency, 2) best practices—standard processes and means of inter-operating various tools, and most importantly to this discussion, 3) data. In order to do this, we need to get better at measuring dataquality.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content