This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing Dataset Quality: A Multifaceted Approach Improving dataset quality involves a combination of advanced preprocessing techniques , innovative data generation methods, and iterative refinement processes. Data validation frameworks play a crucial role in maintaining dataset integrity over time.
Data storage and versioning You need data storage and versioning tools to maintain dataintegrity, enable collaboration, facilitate the reproducibility of experiments and analyses, and ensure accurate ML model development and deployment. Easy collaboration, annotator management, and QA workflows.
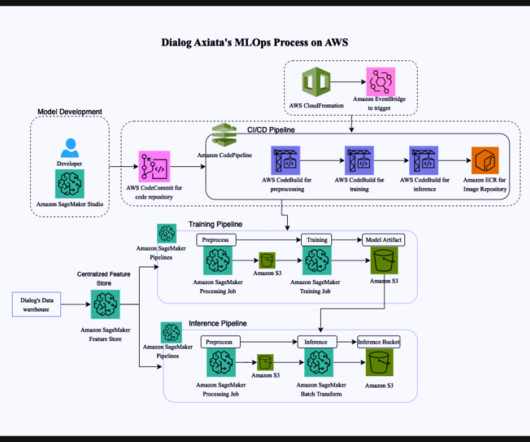
The incorporation of an experiment tracking system facilitates the monitoring of performance metrics, enabling a data-driven approach to decision-making. Datadrift and model drift are also monitored. By developing this project under the AI Factory framework, Dialog Axiata could overcome the aforementioned challenges.
Deepchecks offers several compelling features that set it apart from other testing frameworks and make it an attractive choice for ML practitioners: Comprehensive ML Testing: Deepchecks provides a wide range of checks and validations for ML models and data. When to use Deepchecks?
Significance of ETL pipeline in machine learning The significance of ETL pipelines lies in the fact that they enable organizations to derive valuable insights from large and complex data sets. Here are some specific reasons why they are important: DataIntegration: Organizations can integratedata from various sources using ETL pipelines.
Fiddler AI The Fiddler AI Observability solution allows data science, engineering, and line-of-business teams to validate, monitor, analyze, and improve ML models deployed on SageMaker AI. This proactive approach allows teams to quickly resolve issues, continuously improving model reliability and performance.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content