This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There might be changes in the data distribution in production, thus causing […]. The post The Importance of DataDrift Detection that Data Scientists Do Not Know appeared first on Analytics Vidhya. But, once deployed in production, ML models become unreliable and obsolete and degrade with time.
What makes AI governance different from data governance? As the world turns and datadrifts, AI systems can deviate from their intended design, magnifying ethical concerns like fairness and bias. AI governance focuses on outputs–the decisions, predictions, and autonomous content created by AI systems.
Data quality is of paramount importance at Uber, powering critical decisions and features. In this blog learn how we automated column-level drift detection in batch datasets at Uber scale, reducing the median time to detect issues in critical datasets by 5X.
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. An example of how datadrift may occur is in the context of changing mobile usage patterns over time.
Data validation frameworks play a crucial role in maintaining dataset integrity over time. Automated tools such as TensorFlow Data Validation (TFDV) and Great Expectations help enforce schema consistency, detect anomalies, and monitor datadrift.
Discover how Databricks Lakehouse Monitoring empowers you to ensure reliable, accurate forecasts by proactively detecting datadrift, model degradation, and more.
Like any large tech company, data is the backbone of the Uber platform. Not surprisingly, data quality and drifting is incredibly important. Many datadrift error translates into poor performance of ML models which are not detected until the models have ran. TheSequence is a reader-supported publication.
Post-deployment monitoring and maintenance: Managing deployed models includes monitoring for datadrift, model performance issues, and operational errors, as well as performing A/B testing on your different models.
tweaktown.com Research Researchers unveil time series deep learning technique for optimal performance in AI models A team of researchers has unveiled a time series machine learning technique designed to address datadrift challenges. techxplore.com Are deepfakes illegal?
DataDrift Detection and Model Retraining Trigger – DataDrift Detection with… Read the full blog for free on Medium. Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI.
legal document review) It excels in tasks that require specialised terminologies or brand-specific responses but needs a lot of computational resources and may become obsolete with new data.
This is not ideal because data distribution is prone to change in the real world which results in degradation in the model’s predictive power, this is what you call datadrift. There is only one way to identify the datadrift, by continuously monitoring your models in production.
The Problems in Production Data & AI Model Output Building robust AI systems requires a thorough understanding of the potential issues in production data (real-world data) and model outcomes. Model Drift: The model’s predictive capabilities and efficiency decrease over time due to changing real-world environments.
MLOps monitoring requires teams to continuously track metrics such as model accuracy (correctness), precision (consistency), recall (memory) and datadrift (external factors that degrade models over time). The real-time monitoring and alerting systems within AIOps technologies enable IT teams to identify and resolve IT issues quickly.
Baseline job datadrift: If the trained model passes the validation steps, baseline stats are generated for this trained model version to enable monitoring and the parallel branch steps are run to generate the baseline for the model quality check. Monitoring (datadrift) – The datadrift branch runs whenever there is a payload present.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
Key Challenges in ML Model Monitoring in Production DataDrift and Concept DriftData and concept drift are two common types of drift that can occur in machine-learning models over time. Datadrift refers to a change in the input data distribution that the model receives.
Knowing this, we walked through a demo of DataRobot AI Cloud MLOps solution , which can manage the open-source models developed by the retailer and regularly provide metrics such as service health, datadrift and changes in accuracy. Accelerating Value-Realization with Industry Specific Use Cases.
This guide will cover […] The post Monitor Data & Model in Airline Ops with Evidently & Streamlit in Production appeared first on Analytics Vidhya. Introduction Have you experienced the frustration of a well-performing model in training and evaluation performing worse in the production environment?
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
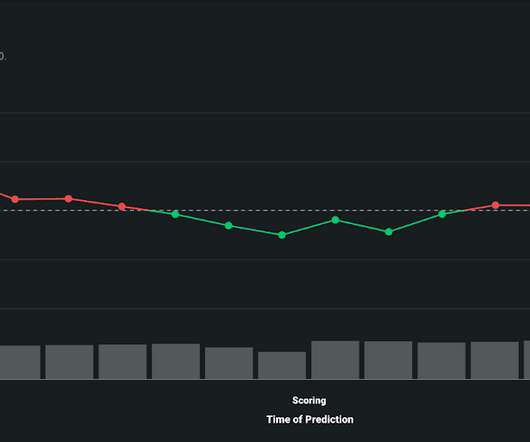
Model Observability provides an end-to-end picture of the internal states of a system, such as the system’s inputs, outputs, and environment, including datadrift, prediction performance, service health, and more relevant metrics. Visualize DataDrift Over Time to Maintain Model Integrity. Drift Over Time.
Datadrift is a phenomenon that reflects natural changes in the world around us, such as shifts in consumer demand, economic fluctuation, or a force majeure. The key, of course, is your response time: how quickly datadrift can be analyzed and corrected. Drill Down into Drift for Rapid Model Diagnostics.
Introduction Whether you’re a fresher or an experienced professional in the Data industry, did you know that ML models can experience up to a 20% performance drop in their first year? Monitoring these models is crucial, yet it poses challenges such as data changes, concept alterations, and data quality issues.
Auto DataDrift and Anomaly Detection Photo by Pixabay This article is written by Alparslan Mesri and Eren Kızılırmak. Model performance may change over time due to datadrift and anomalies in upcoming data. This can be prevented using Google’s Tensorflow Data Validation library.
Discuss with stakeholders how accuracy and datadrift will be monitored. Incorporate methodologies to address model drift and datadrift. Predictions can be made in batches or in real time. Predictions can be saved to a database or used immediately in another process. Plan for ongoing maintenance and enhancement.
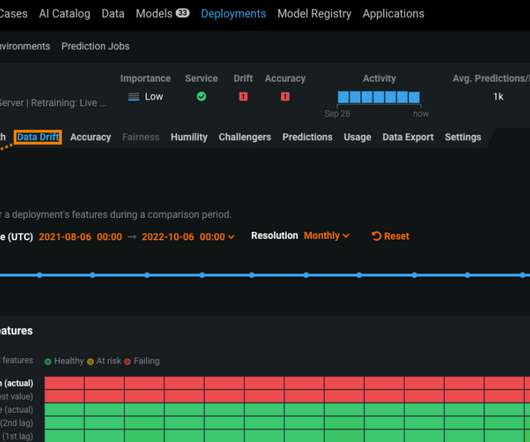
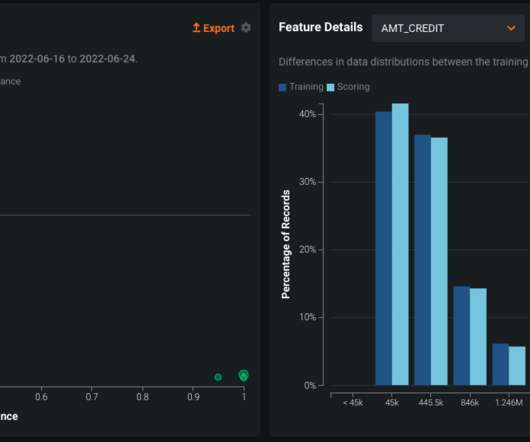
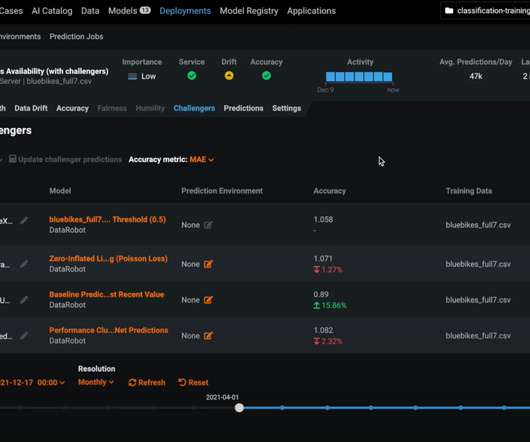
It should be clear when datadrift is happening and if the model needs to be retrained. DataRobot offers three primary explainability features in MLOps: Service Health , DataDrift , and Accuracy. DataDrift. This is called datadrift and can cause the deployment to become inaccurate.
However, the data in the real world is constantly changing, and this can affect the accuracy of the model. This is known as datadrift, and it can lead to incorrect predictions and poor performance. In this blog post, we will discuss how to detect datadrift using the Python library TorchDrift.
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
DataRobot DataDrift and Accuracy Monitoring detects when reality differs from the situation when the training dataset was created and the model trained. Meanwhile, DataRobot can continuously train Challenger models based on more up-to-date data.
A prerequisite in measuring a deployed model’s evolving performance is to collect both its input data and business outcomes in a deployed setting. With this data in hand, we are able to measure both the datadrift and model performance, both of which are essential metrics in measuring the health of the deployed model.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
Monitoring Models in Production There are several types of problems that Machine Learning applications can encounter over time [4]: Datadrift: sudden changes in the features values or changes in data distribution. Model/concept drift: how, why, and when the performance of the model changes.
For instance, a notebook that monitors for model datadrift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
The Stuff They Didn’t Tell You in Data Science Class: Tips and Tricks for Every Level of Practical Data Science | Slides Here In this session, attendees were reminded about the gap between applying data science and studying data science. This includes datadrift, cold starts, sudden scaling, and competing priorities.
Enterprises can accelerate collaborative experimentation with the flexibility to customize models across open-source frameworks and production environments through a superior user experience, a decade of DataRobot’s data science expertise, and support for diverse organizational use cases.
Describing the data As mentioned before, we will be using the data provided by Corporación Favorita in Kaggle. After deployment, we will monitor the model performance with the current best model and check for datadrift and model drift. Apart from that, we must constantly monitor the data as well.
Offering a seamless workflow, the platform integrates with the cloud and data sources in the ecosystem today. Data science teams have explainability and governance with one-click compliance documentation, blueprints, and model lineage. Advanced features like monitoring, datadrift tracking, and retraining keep models aligned.
And sensory gating causes our brains to filter out information that isn’t novel, resulting in a failure to notice gradual datadrift or slow deterioration in system accuracy. DataDrift assesses how the distribution of data changes across all features.
By contrast: ML-powered software introduces uncertainty due to real-world entropy (datadrift, model drift), making testing probabilistic rather than deterministic. We dont disagree with this but wed add that, with traditional software, each version completes a clearly defined, stable development cycle.
However, dataset version management can be a pain for maturing ML teams, mainly due to the following: 1 Managing large data volumes without utilizing data management platforms. 2 Ensuring and maintaining high-quality data. 3 Incorporating additional data sources. 4 The time-consuming process of labeling new data points.
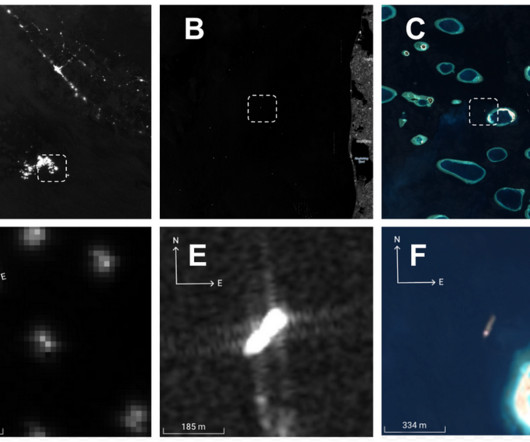
It is important to emphasize that while the data sources are largely stable, ocean conditions are not, and models can exhibit performance degradations even in the absence of datadrift. For example, marine infrastructure (wind turbines, oil platforms, etc) is constantly under construction.
Some popular data quality monitoring and management MLOps tools available for data science and ML teams in 2023 Great Expectations Great Expectations is an open-source library for data quality validation and monitoring. It could help you detect and prevent data pipeline failures, datadrift, and anomalies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content