This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data.
If you add in IBM data governance solutions, the top left will look a bit more like this: The data governance solution powered by IBM Knowledge Catalog offers several capabilities to help facilitate advanced datadiscovery, automated data quality and data protection.
When building machine learning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. So much so that a basic barrier, the great range of data formats, is slowing advancement in ML.
Data scientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
An enterprise data catalog does all that a library inventory system does – namely streamlining datadiscovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Uncovering the Power of Comet Across the Data Science Journey Photo by Nguyen Le Viet Anh on Unsplash Machine learning (ML) projects are usually complicated and include several stages, from datadiscovery to model implementation. Comet provides different functions that make this whole process much more manageable.
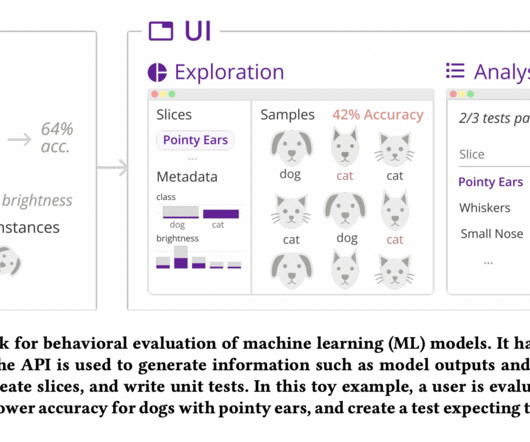
In the actual world, machine learning (ML) systems can embed issues like societal prejudices and safety worries. Understanding patterns of model output for subgroups or slices of input data goes beyond examining aggregate metrics like accuracy or F1 score. Zeno works together with other systems and combines the methods of others.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
With an open data lakehouse architecture, you can now optimize your data warehouse workloads for price performance and modernize traditional data lakes with better performance and governance for AI.
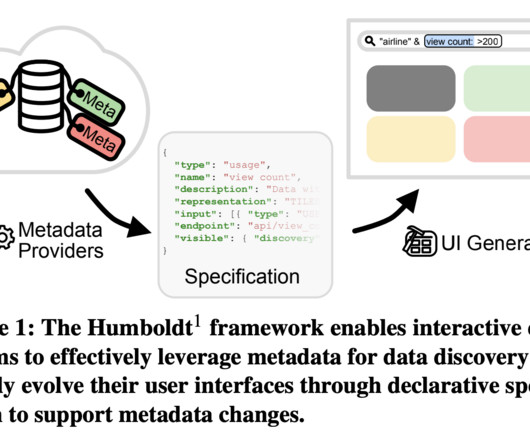
You can also use custom data identifiers to create data identifiers tailored to your specific use case. Datadiscovery and findability Findability is an important step of the process. Organizations need to have mechanisms to find the data under consideration in an efficient and quick manner for timely response.
Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai In this demo, you’ll see how Delphina’s AI-powered “junior” data scientist can transform the data science workflow, automating labor-intensive tasks like datadiscovery, transformation, and model building.
In Rita Sallam’s July 27 research, Augmented Analytics , she writes that “the rise of self-service visual-bases datadiscovery stimulated the first wave of transition from centrally provisioned traditional BI to decentralized datadiscovery.” We agree with that.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Is more data always better? AR : Absolutely.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Is more data always better? AR : Absolutely.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Is more data always better? AR : Absolutely.
Can you discuss the role of AI in Securiti’s platform and how it enhances data security and governance? Securiti uses advanced techniques harnessing AI and ML to provide increased accuracy in datadiscovery and classification. Legacy datadiscovery and DLP solutions are no longer meeting these needs.
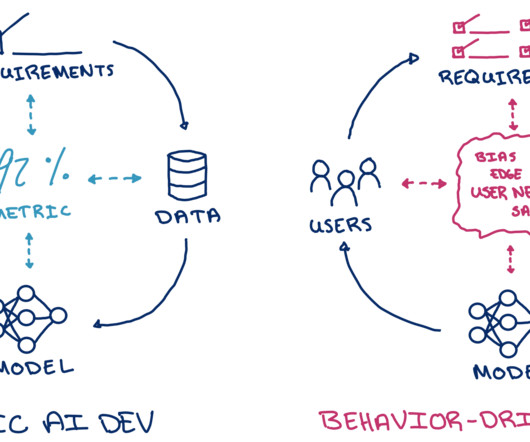
A platform for behavior-driven AI development The beauty of a behavior-based framing on AI development is that it is still data and model agnostic. While the specific behaviors for each ML task will be vastly different, subgroups of data and metrics are universal concepts. Datadiscovery and generation.
Datadiscovery has become increasingly challenging due to the proliferation of easily accessible data analysis tools and low-cost cloud storage. While these advancements have democratized data access, they have also led to less structured data stores and a rapid expansion of derived artifacts in enterprise environments.
IBM Watson Analytics IBM AI-driven insights are used by Watson Analytics, a cloud-based data analysis and visualization tool, to assist users in understanding their data. Users can rapidly find trends, patterns, and relationships in data using its automatic datadiscovery tool.
IBM Security® Discover and Classify (ISDC) is a datadiscovery and classification platform that delivers automated, near real-time discovery, network mapping and tracking of sensitive data at the enterprise level, across multi-platform environments.
IBM Watson Analytics IBM AI-driven insights are used by Watson Analytics, a cloud-based data analysis and visualization tool, to assist users in understanding their data. Users can rapidly find trends, patterns, and relationships in data using its automatic datadiscovery tool.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to David Hershey about GPT-3 and the feature of MLOps. David: Thank you.
The table only exists in the Data Catalog. This powerful solution opens up exciting possibilities for enterprise datadiscovery and insights. We encourage you to deploy it in your own environment and experiment with different types of queries across your data assets.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content