This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
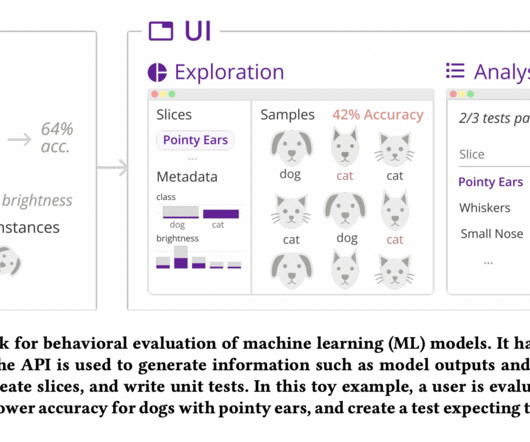
Understanding patterns of model output for subgroups or slices of input data goes beyond examining aggregate metrics like accuracy or F1 score. Stakeholders such as MLengineers, designers, and domain experts must work together to identify a model’s expected and potential faults.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. So does that mean feature selection is no longer necessary? Robert, you can go first.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. So does that mean feature selection is no longer necessary? Robert, you can go first.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. So does that mean feature selection is no longer necessary? Robert, you can go first.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. Solution overview The solution integrates with your existing data catalogs and repositories, creating a unified, scalable semantic layer across the entire data landscape.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content