This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Even among datasets that include the same subject matter, there is no standard layout of files or data formats. This obstacle lowers productivity through machine learning development—from datadiscovery to model training. Database metadata can be expressed in various formats, including schema.org and DCAT.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly.
An enterprise data catalog does all that a library inventory system does – namely streamlining datadiscovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Moreover, banks must stay in compliance with industry regulations like BCBS 239, which focus on improving banks’ risk data aggregation and risk reporting capabilities.
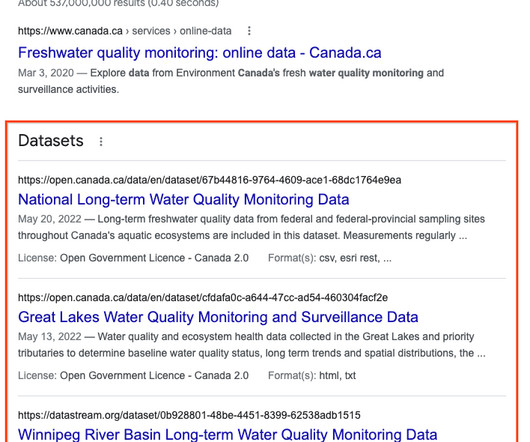
Dataset Search shows users essential metadata about datasets and previews of the data where available. Users can then follow the links to the data repositories that host the datasets. Dataset Search primarily indexes dataset pages on the Web that contain schema.org structured data.
Data fabric promotes data discoverability. Here, data assets can be published into categories, creating an enterprise-wide data marketplace. This marketplace provides a search mechanism, utilizing metadata and a knowledge graph to enable asset discovery. data virtualization) play a key role.
Monitor and identify data quality issues closer to the source to mitigate the potential impact on downstream processes or workloads. Efficiently adopt data platforms and new technologies for effective data management. Apply metadata to contextualize existing and new data to make it searchable and discoverable.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata.
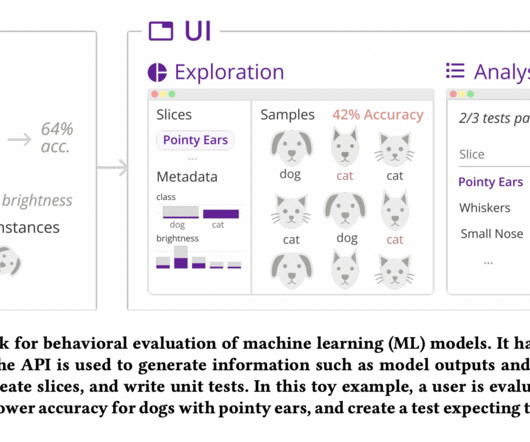
Model outputs, metrics, metadata, and altered instances are only some of the fundamental components of behavioral assessment that can be implemented as Python API functions. The participant in Case 2 used the API’s extensibility to create model-analysis metadata. Zeno is made available to the public via a Python script.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Processing of Data Once the data is stored, Hive provides a metadata layer allowing users to define the schema and create tables.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. Robert, you can go first. I have a certain point of view on this.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. Robert, you can go first. I have a certain point of view on this.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. Robert, you can go first. I have a certain point of view on this.
Data Transparency Data Transparency is the pillar that ensures data is accessible and understandable to all stakeholders within an organization. This involves creating data dictionaries, documentation, and metadata. It provides clear insights into the data’s structure, meaning, and usage.
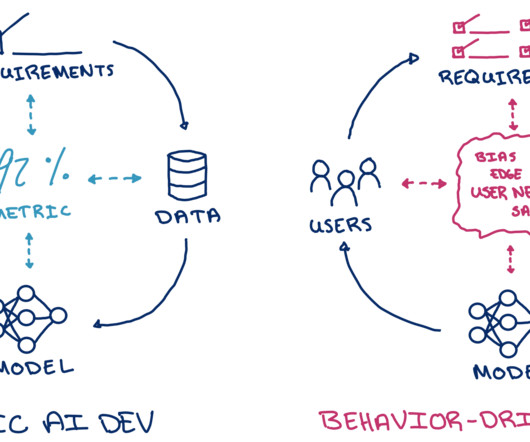
Behaviors are subgroups of data (typically defined by combinations of metadata) quantified by a specific metric. Succinctly, behavior-driven development requires sufficient data that is representative of expected behaviors and metadata for defining and quantifying the behaviors. Figure 5.
Also consider storing the metadata of the files being loaded in your knowledge bases for effective tracking. You can also use custom data identifiers to create data identifiers tailored to your specific use case. Datadiscovery and findability Findability is an important step of the process.
Datadiscovery has become increasingly challenging due to the proliferation of easily accessible data analysis tools and low-cost cloud storage. While these advancements have democratized data access, they have also led to less structured data stores and a rapid expansion of derived artifacts in enterprise environments.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. Solution overview The solution integrates with your existing data catalogs and repositories, creating a unified, scalable semantic layer across the entire data landscape.
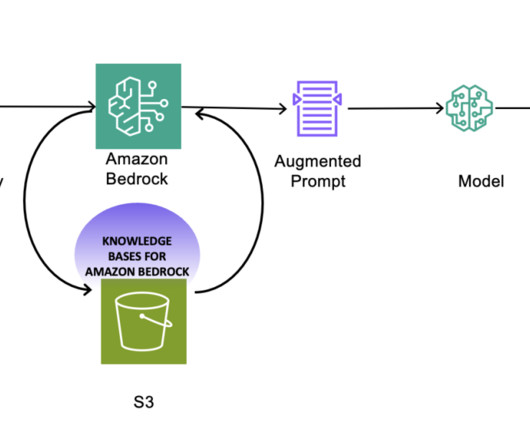
The enhanced metadata supports the matching categories to internal controls and other relevant policy and governance datasets. Integrated vectorized embedding capabilities streamline data preparation for various applications such as retrieval augmented generation (RAG) and other machine learning and generative AI use cases.
Catalogue Tableau Catalogue automatically catalogues all data assets and sources into one central list and provides metadata in context for fast datadiscovery.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content