This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Even among datasets that include the same subject matter, there is no standard layout of files or data formats. This obstacle lowers productivity through machine learning development—from datadiscovery to model training. Database metadata can be expressed in various formats, including schema.org and DCAT.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Banks and their employees place trust in their risk models to help ensure the bank maintains liquidity even in the worst of times.
So, instead of wandering the aisles in hopes you’ll stumble across the book, you can walk straight to it and get the information you want much faster. An enterprise data catalog does all that a library inventory system does – namely streamlining datadiscovery and access across data sources – and a lot more.
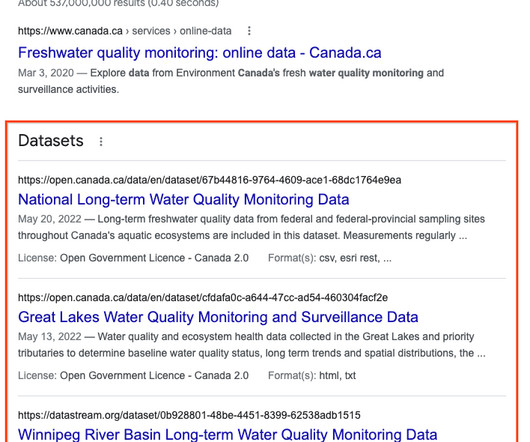
For one example, in the United States a recent new policy requires free and equitable access to outcomes of all federally funded research, including data and statistical information along with publications. Dataset Search shows users essential metadata about datasets and previews of the data where available.
It can include technologies that range from Oracle, Teradata and Apache Hadoop to Snowflake on Azure, RedShift on AWS or MS SQL in the on-premises data center, to name just a few. All phases of the data-information lifecycle. The data fabric embraces all phases of the data-information-insight lifecycle.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata.
The General Data Protection Regulation (GDPR) right to be forgotten, also known as the right to erasure, gives individuals the right to request the deletion of their personally identifiable information (PII) data held by organizations. Example: customer information pertaining to the email address art@venere.org.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Processing of Data Once the data is stored, Hive provides a metadata layer allowing users to define the schema and create tables.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. PP : Yeah, I think you guys are spot on.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. PP : Yeah, I think you guys are spot on.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage. PP : Yeah, I think you guys are spot on.
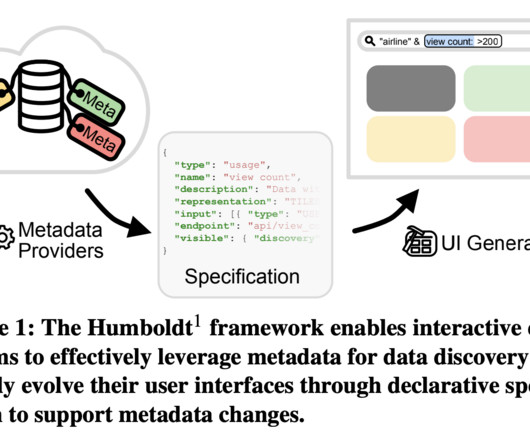
Data Transparency Data Transparency is the pillar that ensures data is accessible and understandable to all stakeholders within an organization. This involves creating data dictionaries, documentation, and metadata. It provides clear insights into the data’s structure, meaning, and usage.
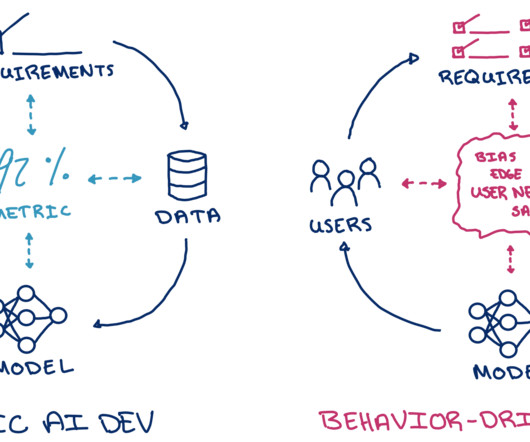
Behaviors are subgroups of data (typically defined by combinations of metadata) quantified by a specific metric. Succinctly, behavior-driven development requires sufficient data that is representative of expected behaviors and metadata for defining and quantifying the behaviors. Figure 5.
Datadiscovery has become increasingly challenging due to the proliferation of easily accessible data analysis tools and low-cost cloud storage. While these advancements have democratized data access, they have also led to less structured data stores and a rapid expansion of derived artifacts in enterprise environments.
Moreover, LRRs and other industry frameworks, such as the National Institute of Standards and Technology (NIST), Information Technology Infrastructure Library (ITIL), and Control Objectives for Information and Related Technologies (COBIT), are constantly evolving.
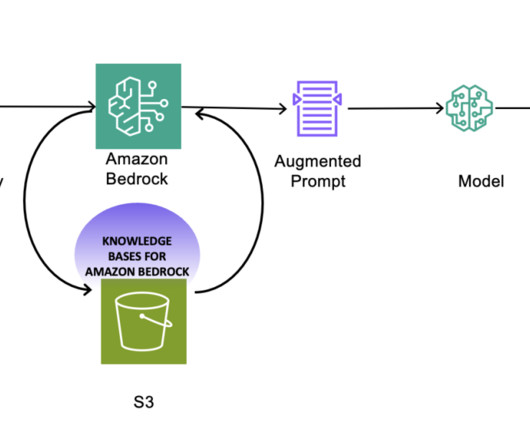
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadatainformation related to all of the data assets that are relevant to the search context.
Its user-friendly interface and collaboration features make data accessible and insightful for businesses of all sizes. Introduction In today’s data-driven world, the ability to effectively analyse and visualise information is paramount. It transforms complex data into clear visuals, enabling informed decisions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content