This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Simply put, focusing solely on dataanalysis, coding or modeling will no longer cuts it for most corporate jobs. My personal opinion: its more important than ever to be an end-to-end data scientist. You have to understand data, how to extract value from them and how to monitor model performances. What to do then?
Many beginners in datascience and machine learning only focus on the dataanalysis and model development part, which is understandable, as the other department often does the deployment process. We will walk through it together, from the dataanalysis to automatic retraining.
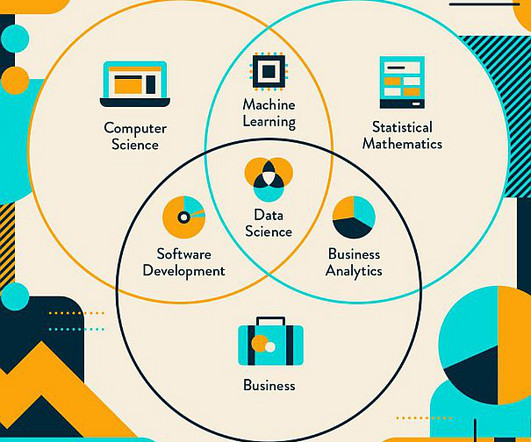
Datascience is a multidisciplinary field that relies on scientific methods, statistics, and Artificial Intelligence (AI) algorithms to extract knowledgable and meaningful insights from data. At its core, datascience is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions.
Key Challenges in ML Model Monitoring in Production DataDrift and Concept DriftData and concept drift are two common types of drift that can occur in machine-learning models over time. Datadrift refers to a change in the input data distribution that the model receives.
This includes: Supporting Snowflake External OAuth configuration Leveraging Snowpark for exploratory dataanalysis with DataRobot-hosted Notebooks and model scoring. Exploratory DataAnalysis After we connect to Snowflake, we can start our ML experiment. Learn more about Snowflake External OAuth.
By outsourcing the day-to-day management of the datascience platform to the team who created the product, AI builders can see results quicker and meet market demands faster, and IT leaders can maintain rigorous security and data isolation requirements. Peace of Mind with Secure AI-Driven DataScience on Google Cloud.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new datascience project and get it to production.
How do you drive collaboration across teams and achieve business value with datascience projects? With AI projects in pockets across the business, data scientists and business leaders must align to inject artificial intelligence into an organization. DataAnalysis Must Include Business Value.
By simplifying Time Series Forecasting models and accelerating the AI lifecycle, DataRobot can centralize collaboration across the business—especially datascience and IT teams—and maximize ROI. Prepare your data for Time Series Forecasting. Perform exploratory dataanalysis.
Failure to consider the severity of these problems can lead to issues like degraded model accuracy, datadrift, security issues, and data inconsistencies. Data retrieval: Having several dataset versions requires machine learning practitioners to know which dataset versions correspond to a certain model performance outcome.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. You can learn more about Comet here. You can get the full code here.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
This workflow will be foundational to our unstructured data-based machine learning applications as it will enable us to minimize human labeling effort, deliver strong model performance quickly, and adapt to datadrift.” – Jon Nelson, Senior Manager of DataScience and Machine Learning at United Airlines.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Kedro Kedro is a Python library for building modular datascience pipelines.
However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of data scientists and analysts. Most employees don’t master the conventional datascience toolkit (SQL, Python, R etc.). Adaptability over time To use Text2SQL in a durable way, you need to adapt to datadrift, i.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content