This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Simply put, focusing solely on dataanalysis, coding or modeling will no longer cuts it for most corporate jobs. My personal opinion: its more important than ever to be an end-to-end data scientist. You have to understand data, how to extract value from them and how to monitor model performances. What to do then?
Many beginners in data science and machine learning only focus on the dataanalysis and model development part, which is understandable, as the other department often does the deployment process. We will walk through it together, from the dataanalysis to automatic retraining. Establish a Data Science Project2.
Key Challenges in ML Model Monitoring in Production DataDrift and Concept DriftData and concept drift are two common types of drift that can occur in machine-learning models over time. Datadrift refers to a change in the input data distribution that the model receives.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
This includes: Supporting Snowflake External OAuth configuration Leveraging Snowpark for exploratory dataanalysis with DataRobot-hosted Notebooks and model scoring. Exploratory DataAnalysis After we connect to Snowflake, we can start our ML experiment. Learn more about Snowflake External OAuth.
Offering a seamless workflow, the platform integrates with the cloud and data sources in the ecosystem today. Data science teams have explainability and governance with one-click compliance documentation, blueprints, and model lineage. Advanced features like monitoring, datadrift tracking, and retraining keep models aligned.
However, dataset version management can be a pain for maturing ML teams, mainly due to the following: 1 Managing large data volumes without utilizing data management platforms. 2 Ensuring and maintaining high-quality data. 3 Incorporating additional data sources. 4 The time-consuming process of labeling new data points.
If your dataset is not in time order (time consistency is required for accurate Time Series projects), DataRobot can fix those gaps using the DataRobot Data Prep tool , a no-code tool that will get your data ready for Time Series forecasting. Prepare your data for Time Series Forecasting. Perform exploratory dataanalysis.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. You can learn more about Comet here.
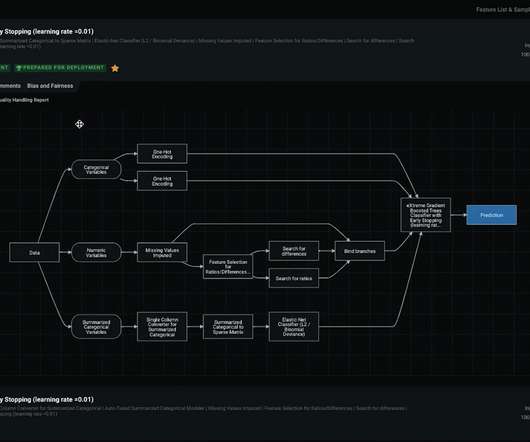
Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow. A typical workflow is illustrated here from data ingestion, EDA (Exploratory DataAnalysis), experimentation, model development and evaluation, to the registration of a candidate model for production.
At the 2022 Gartner Data and Analytics Summit, data leaders learned the latest insights and trends. Here are five key takeaways from one of the biggest data conferences of the year. DataAnalysis Must Include Business Value. You can also go beyond regular accuracy and datadrift metrics.
As an example for catalogue data, it’s important to check if the set of mandatory fields like product title, primary image, nutritional values, etc. are present in the data. So, we need to build a verification layer that runs based on a set of rules to verify and validate data before preparing it for model training.
Common data visualization techniques display the exploratory data by bar charts, pie charts, histograms, line graphs, etc. By visualization, you can identify anomalies in your data and have a better representation of your data content. Here is an example that uses Matplotlib to plot a sine waveform.
I started my project with a simple data set with historical information of coupons sent to clients and a target variable that captured information about whether the coupon was redeemed or not in the past. A look at datadrift. A clear picture of the model’s accuracy.
Making Data Stationary: Many forecasting models assume stationarity. If the data is non-stationary, apply transformations like differencing or logarithmic scaling to stabilize its statistical properties. Exploratory DataAnalysis (EDA): Conduct EDA to identify trends, seasonal patterns, and correlations within the dataset.
How are you looking at model evaluation for cases where data adapts rapidly? Wouldn’t it take time for datadrift to be detected, labeled, and passed back to the model for training? KM: Final question before we end the session. You want to answer that question? I can briefly start.
How are you looking at model evaluation for cases where data adapts rapidly? Wouldn’t it take time for datadrift to be detected, labeled, and passed back to the model for training? KM: Final question before we end the session. You want to answer that question? I can briefly start.
Biased training data can lead to discriminatory outcomes, while datadrift can render models ineffective and labeling errors can lead to unreliable models. Scikit-learn is a powerful open-source Python library for machine learning and predictive dataanalysis. Morgan and Spotify.
This workflow will be foundational to our unstructured data-based machine learning applications as it will enable us to minimize human labeling effort, deliver strong model performance quickly, and adapt to datadrift.” – Jon Nelson, Senior Manager of Data Science and Machine Learning at United Airlines.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Pipelines can be scheduled to carry out CI, CD, or CT.
Adaptability over time To use Text2SQL in a durable way, you need to adapt to datadrift, i. the changing distribution of the data to which the model is applied. For example, let’s assume that the data used for initial fine-tuning reflects the simple querying behaviour of users when they start using the BI system.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content