
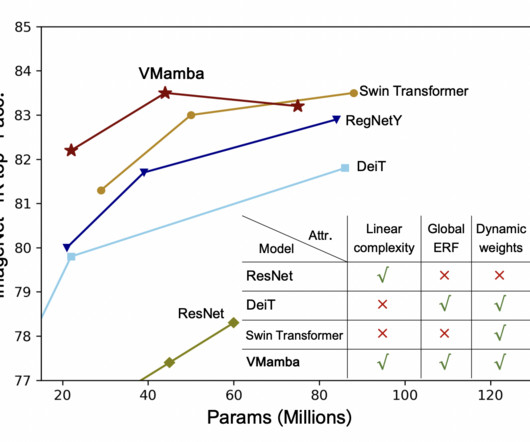
Meet VMamba: An Alternative to Convolutional Neural Networks CNNs and Vision Transformers for Enhanced Computational Efficiency
Marktechpost
JANUARY 23, 2024
There are two major challenges in visual representation learning: the computational inefficiency of Vision Transformers (ViTs) and the limited capacity of Convolutional Neural Networks (CNNs) to capture global contextual information. Also, don’t forget to follow us on Twitter. If you like our work, you will love our newsletter.




















Let's personalize your content