This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
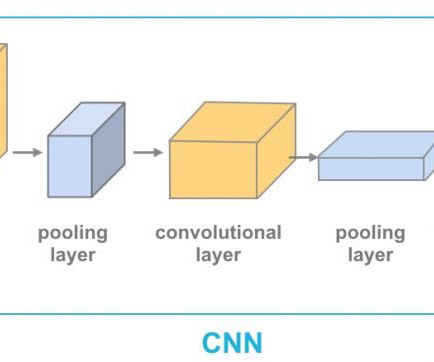
Get a personalized demo for your organization. With the rapid development of ConvolutionalNeuralNetworks (CNNs) , deep learning became the new method of choice for emotion analysis tasks. Multiple hidden layers are the basis of deep neuralnetworks to analyze data functions in the context of functional hierarchy.
We will take a gentle, detailed tour through a multilayer fully-connected neuralnetwork, backpropagation, and a convolutionalneuralnetwork. At Facebook, we use deep neuralnetworks as part of our effort to connect the entire world. To get the best results, it’s helpful to understand how they work.
Get a personalized demo. Training of NeuralNetworks for Image Recognition The images from the created dataset are fed into a neuralnetwork algorithm. The training of an image recognition algorithm makes it possible for convolutionalneuralnetwork image recognition to identify specific classes.
Get a demo. Prompt-based Segmentation combines the power of natural language processing (NLP) and computer vision to create an image segmentation model. Segment Anything Model demo example SAM’s architecture consists of an image encoder, a prompt encoder, and a mask decoder. Book a demo to learn more about the Viso Suite.
Vision Transformer (ViT) have recently emerged as a competitive alternative to ConvolutionalNeuralNetworks (CNNs) that are currently state-of-the-art in different image recognition computer vision tasks. Transformer models have become the de-facto status quo in Natural Language Processing (NLP).
Object detection systems typically use frameworks like ConvolutionalNeuralNetworks (CNNs) and Region-based CNNs (R-CNNs). Concept of ConvolutionalNeuralNetworks (CNN) However, in prompt object detection systems, users dynamically direct the model with many tasks it may not have encountered before.
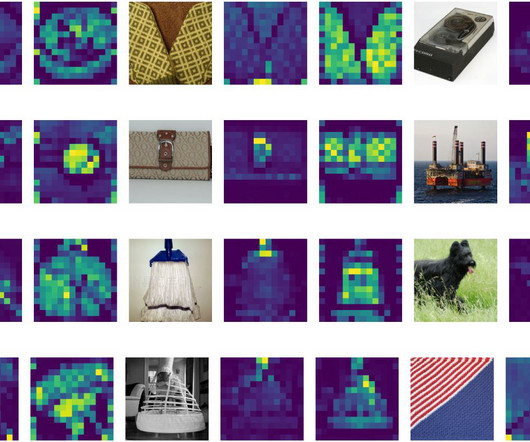
Example of a deep learning visualization: small convolutionalneuralnetwork CNN, notice how the thickness of the colorful lines indicates the weight of the neural pathways | Source How is deep learning visualization different from traditional ML visualization? You can find an interactive version online.
Get a demo for your organization. Pattern Recognition in Natural Language Processing Natural Language Processing (NLP) is a field of study that deals with the computational understanding of human language. In recent years, NLP has made great strides due to the increasing availability of data and advances in machine learning.
Its creators took inspiration from recent developments in natural language processing (NLP) with foundation models. This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. . ConvolutionalNeuralNetworks (CNNs) CNNs are integral to the image encoder of the Segment Anything Model architecture.
Get a demo for your organization. However, unsupervised learning has its own advantages, such as being more resistant to overfitting (the big challenge of ConvolutionalNeuralNetworks ) and better able to learn from complex big data, such as customer data or behavioral data without an inherent structure. About us: Viso.ai
Get a demo here. Viso Suite is the end-to-end, no-code computer vision platform Idea Behind Deep Belief Networks Deep belief networks consist of various layers of neurons, each connected to the neuron of the subsequent layer. Book a demo to learn more about the Viso suite.
Learn more about Viso Suite by booking a demo with us. Foundation models are large-scale neuralnetwork architectures that undergo pre-training on vast amounts of unlabeled data through self-supervised learning. Traditional NLP methods heavily rely on models that are trained on labeled datasets.
Arguably, one of the most pivotal breakthroughs is the application of ConvolutionalNeuralNetworks (CNNs) to financial processes. To learn more about Viso Suite, book a demo with our team. Technologies such as Optical Character Recognition (OCR) and Natural Language Processing (NLP) are foundational to this.
To learn more about enterprise-grade AI, book a demo with our team of experts to discuss Viso Suite. Image annotation AI / Data Annotation Job Aside from the image annotation – there is data annotation related to AI and machine learning applications, e.g. in natural language processing (NLP), or retail.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. In this post, we present a new version of the library, new vectors, new evaluation recipes, and a demo NER project that we trained to usable accuracy in just a few hours. from_disk("./fashion_brands_patterns.jsonl")
Get the Whitepaper or a Demo. VGG Deep ConvolutionalNeuralNetwork Architecture YOLO, or “You Only Look Once,” is a deep learning model for real-time object detection. To learn more about this AI model, read our guide about how Deep NeuralNetwork models work.
This enhances the interpretability of AI systems for applications in computer vision and natural language processing (NLP). Learn more by booking a demo. Source ) This has led to groundbreaking models like GPT for generative tasks and BERT for understanding context in Natural Language Processing ( NLP ). Vaswani et al.
Get a demo for your company. Using a Mask R–CNN ( convolutionalneuralnetwork ) model, they were able to achieve a detection accuracy of 75% and 79.5% However, the potential of Large Language Models (LLMs) and Natural Language Processing (NLP) doesn’t stop at mastering modern languages.
To learn more, get a personalized demo from the Viso team. In particular, researchers are working with the following deep learning models to enhance spatio-temporal action recognition systems: ConvolutionalNeuralNetworks (CNNs) In a basic sense, spatial recognition systems use CNNs to extract features from pixel data.
Book a demo to learn more. As the name suggests, this technique involves transferring the learnings of one trained machine learning model to another, in the form of neuralnetwork weights. We can choose a language model like BERT that can parse human text to build an NLP model such as a text summary.
Deep learning and ConvolutionalNeuralNetworks (CNNs) have enabled speech understanding and computer vision on our phones, cars, and homes. Natural Language Processing (NLP) and knowledge representation and reasoning have empowered the machines to perform meaningful web searches. Brooks et al.
Get a personal demo. Discriminative models include a wide range of models, like ConvolutionalNeuralNetworks (CNNs), Deep NeuralNetworks (DNNs), Support Vector Machines (SVMs), or even simpler models like random forests. In NLP this process is used to predict the next word in a sentence.
To start implementing computer vision for business solutions, book a demo of Viso Suite with our team of experts. Feedforward neuralnetworks on the other hand are more traditional one-way networks, where data flows in one direction (forward) which is the opposite of RNNs that have loops.
We’ve been working on Prodigy since we first launched Explosion last year, alongside our open-source NLP library spaCy and our consulting projects (it’s been a busy year!). Try the live demo! The model is a convolutionalneuralnetwork stacked with a unigram bag-of-words. Human time and attention is precious.
Request a demo for your organization! Temporal coherence was exploited in a co-training setting by early work on learning convolutionalneuralnetworks (CNNs) for visual object detection and face detection. About us: viso.ai PTMs are often used for language modeling, text classification, and question-answering systems.
To learn more, book a demo with our team. These models usually use a classification algorithm like a ConvolutionalNeuralNetwork (CNN) or a multimodal architecture. However, public datasets are available for a variety of tasks, whether it is captioning, segmentation , detection, NLP, or even video data.
From the development of sophisticated object detection algorithms to the rise of convolutionalneuralnetworks (CNNs) for image classification to innovations in facial recognition technology, applications of computer vision are transforming entire industries. Viso Suite is the end-to-End, No-Code Computer Vision Solution.
To learn more, book a demo with our team. Viso Suite, the all-in-one computer vision solution The journey of AI in art traces back to the development of neuralnetworks and deep learning technologies. And, Generative Adversarial Networks (GANs) , which opened new doors for generating high-quality, realistic images.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content