This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Instead of solely focusing on whos building the most advanced models, businesses need to start investing in robust, flexible, and secure infrastructure that enables them to work effectively with any AI model, adapt to technological advancements, and safeguard their data. Did we over-invest in companies like OpenAI and NVIDIA?
In this paper researchers introduced a new framework, ReasonFlux that addresses these limitations by reimagining how LLMs plan and execute reasoning steps using hierarchical, template-guided strategies. Recent approaches to enhance LLM reasoning fall into two categories: deliberate search and reward-guided methods.
Used alongside other techniques such as prompt engineering, RAG, and contextual grounding checks, Automated Reasoning checks add a more rigorous and verifiable approach to enhancing the accuracy of LLM-generated outputs. Amazon Nova Canvas and Amazon Nova Reel come with controls to support safety, security, and IP needs with responsible AI.
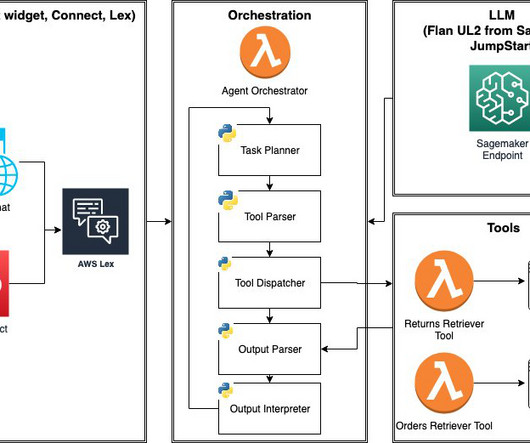
Large language model (LLM) agents are programs that extend the capabilities of standalone LLMs with 1) access to external tools (APIs, functions, webhooks, plugins, and so on), and 2) the ability to plan and execute tasks in a self-directed fashion. We conclude the post with items to consider before deploying LLM agents to production.
ConversationalAI has come a long way in recent years thanks to the rapid developments in generative AI, especially the performance improvements of large language models (LLMs) introduced by training techniques such as instruction fine-tuning and reinforcement learning from human feedback.
Say It Out Loud ChatRTX uses retrieval-augmented generation , NVIDIA TensorRT-LLM software and NVIDIA RTX acceleration to bring chatbot capabilities to RTX-powered Windows PCs and workstations. The latest version adds support for additional LLMs, including Gemma, the latest open, local LLM trained by Google.
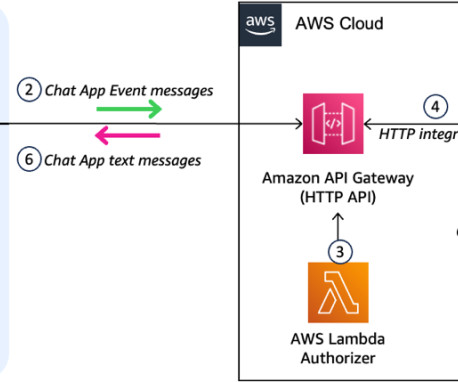
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. This request contains the user’s message and relevant metadata.
This evolution paved the way for the development of conversationalAI. The recent rise of Large Language Models (LLMs) has been a game changer for the ChatBot industry. These models are trained on extensive data and have been the driving force behind conversational tools like BARD and ChatGPT. Run the following command:
Despite the seemingly unstoppable adoption of LLMs across industries, they are one component of a broader technology ecosystem that is powering the new AI wave. Many conversationalAI use cases require LLMs like Llama 2, Flan T5, and Bloom to respond to user queries. pip install -qU sagemaker pinecone-client==2.2.1
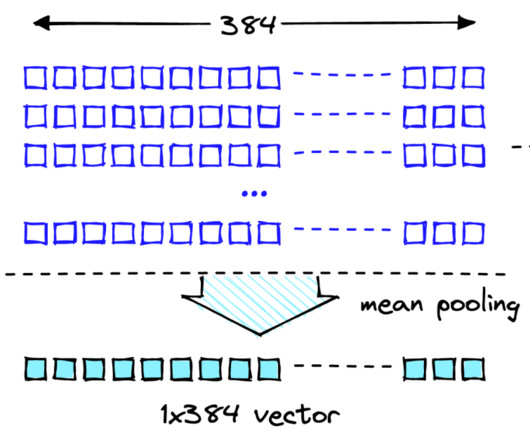
It’s developed by BAAI and is designed to enhance retrieval capabilities within large language models (LLMs). The model supports three retrieval methods: Dense retrieval (BGE-M3) Lexical retrieval (LLM Embedder) Multi-vector retrieval (BGE Embedding Reranker). The LLM processes the request and generates an appropriate response.
Solution overview The LMA sample solution captures speaker audio and metadata from your browser-based meeting app (as of this writing, Zoom and Chime are supported), or audio only from any other browser-based meeting app, softphone, or audio source. You can also create your own custom prompts and corresponding options.
Large Language Models (LLMs) present a unique challenge when it comes to performance evaluation. Unlike traditional machine learning where outcomes are often binary, LLM outputs dwell in a spectrum of correctness. auto-evaluation) and using human-LLM hybrid approaches. Consider harnessing LLMs for building an evaluation set.
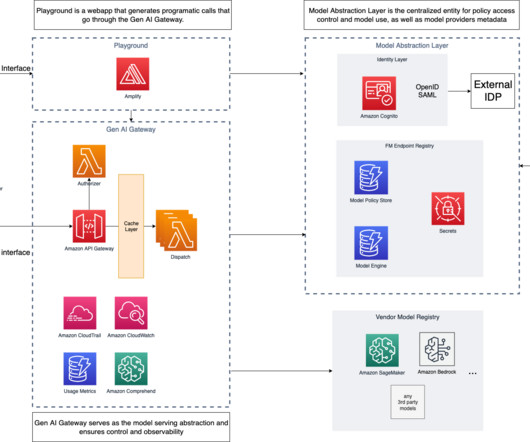
This means companies need loose coupling between app clients (model consumers) and model inference endpoints, which ensures easy switch among large language model (LLM), vision, or multi-modal endpoints if needed. This table will hold the endpoint, metadata, and configuration parameters for the model.
If you are looking to get started with generative AI and the use of LLMs in conversationalAI, this post is for you. We have included a sample project to quickly deploy an Amazon Lex bot that consumes a pre-trained open-source LLM. We also use LangChain, a popular framework that simplifies LLM-powered applications.
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. seconds or less. This represents about a full page of text. Choose Next.
Exploration of Dialogflow CX The weblog will provide an in-depth understanding of Dialogflow CX, highlighting its pivotal role in crafting intelligent conversational agents. Readers will gain insights into its features, functionalities, and its unique position in the realm of conversationalAI platforms.
Exploration of Dialogflow CX The weblog will provide an in-depth understanding of Dialogflow CX, highlighting its pivotal role in crafting intelligent conversational agents. Readers will gain insights into its features, functionalities, and its unique position in the realm of conversationalAI platforms. Click on ‘Continue’.
NVIDIA NeMo Framework NVIDIA NeMo is an end-to-end cloud-centered framework for training and deploying generative AI models with billions and trillions of parameters at scale. Akshit Arora is a senior data scientist at NVIDIA, where he works on deploying conversationalAI models on GPUs at scale.
Whether you are just starting to explore the world of conversationalAI or looking to optimize your existing agent deployments, this comprehensive guide can provide valuable long-term insights and practical tips to help you achieve your goals.
The introduction of external knowledge retrieval fundamentally expands the possibilities of conversationalAI applications. The second script shows how to query those embeddings with an LLM for RAG-based Q&A. This quick workflow lets you maintain a powerful, scalable knowledge base for any LLM-powered application.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content